从T5到GPT-4最新最全梳理,人大等《大型语言模型综述》,51页pdf详述大模型进展
机器之心编辑部
为什么仿佛一夜之间,自然语言处理(NLP)领域就突然突飞猛进,摸到了通用人工智能的门槛?如今的大语言模型(LLM)发展到了什么程度?未来短时间内,AGI 的发展路线又将如何?

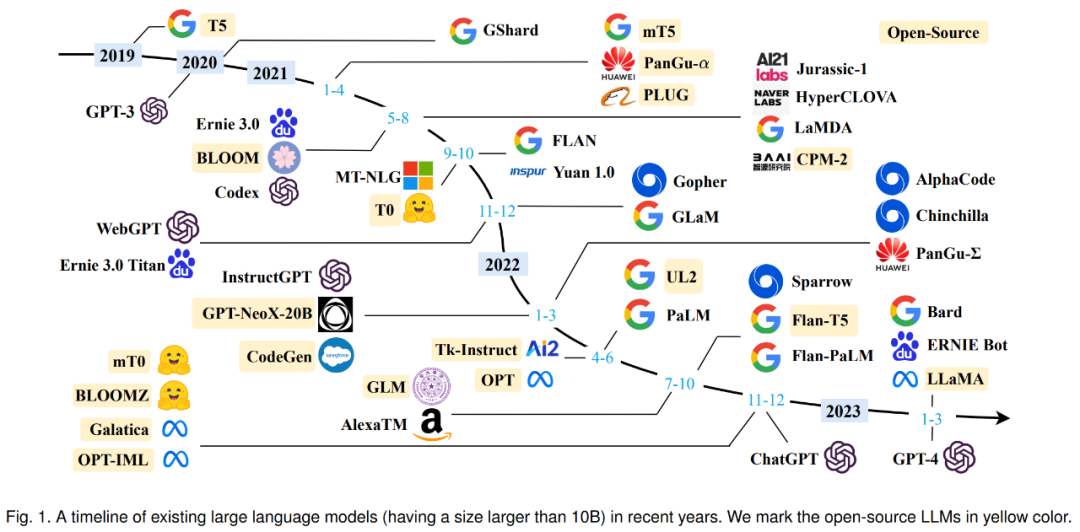
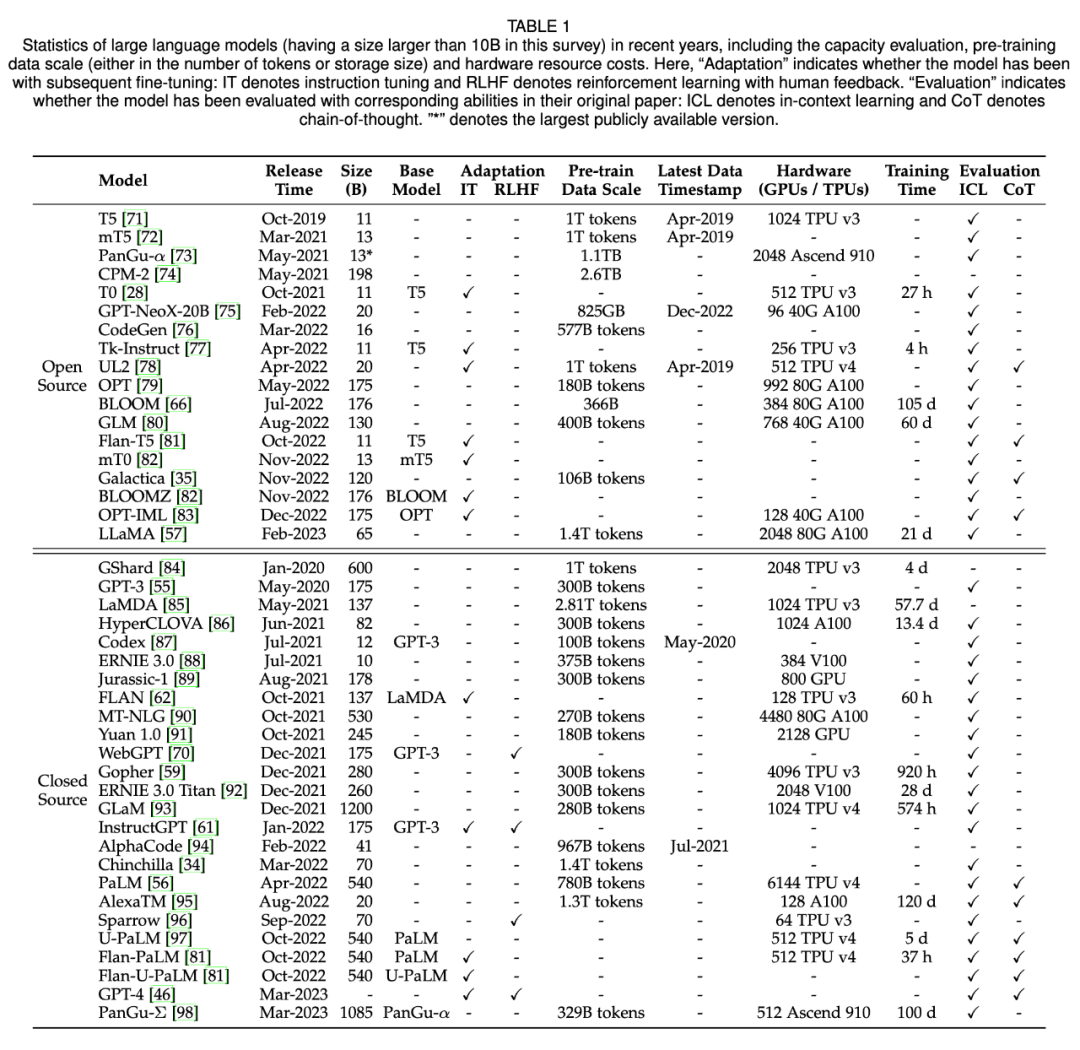
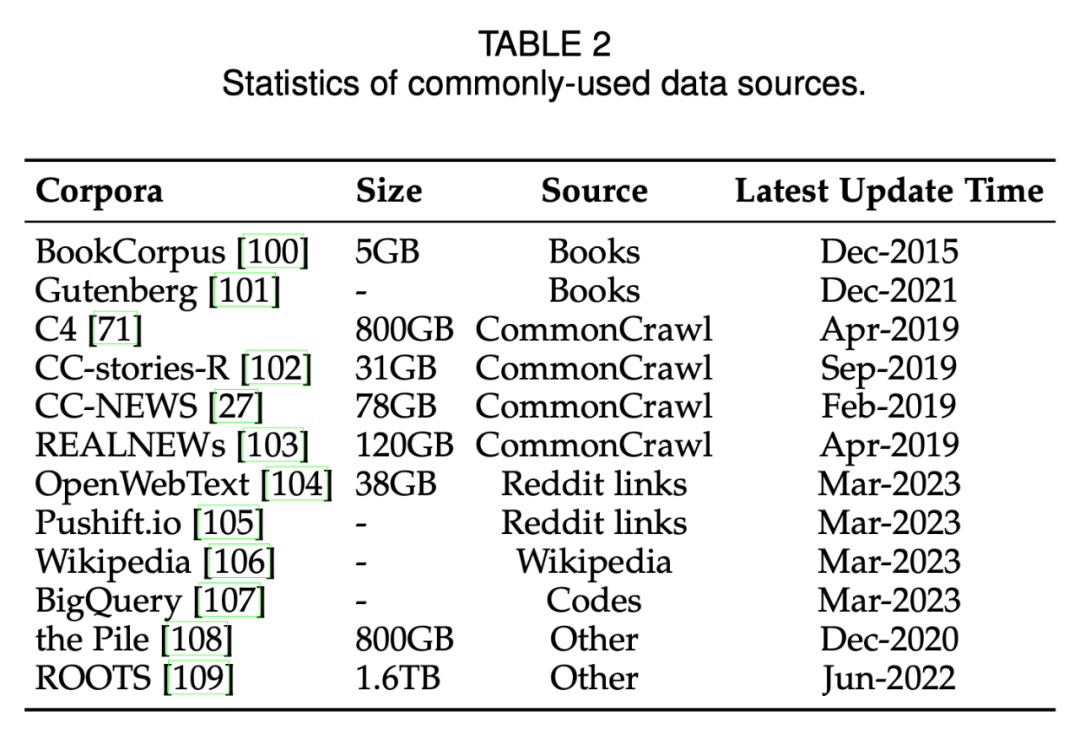
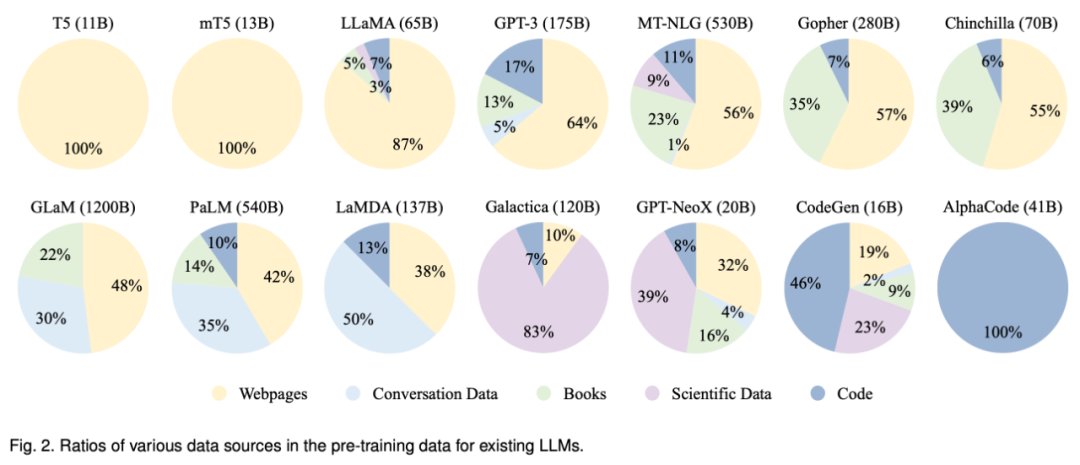

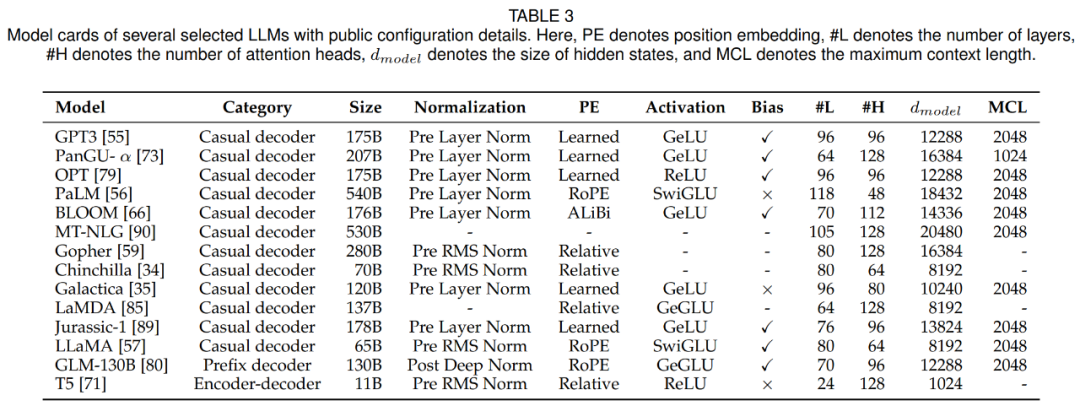
-
平衡数据分布。 -
结合指令调优和预训练。
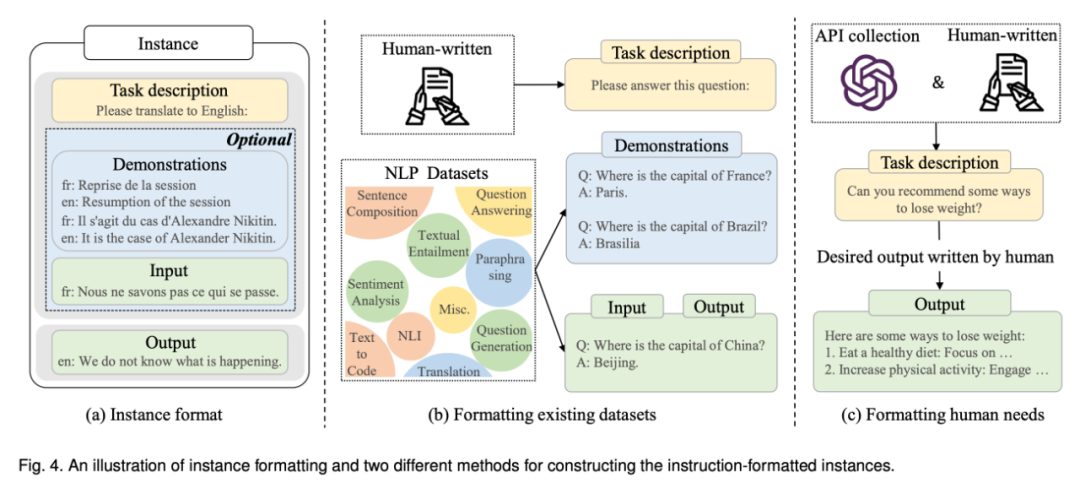
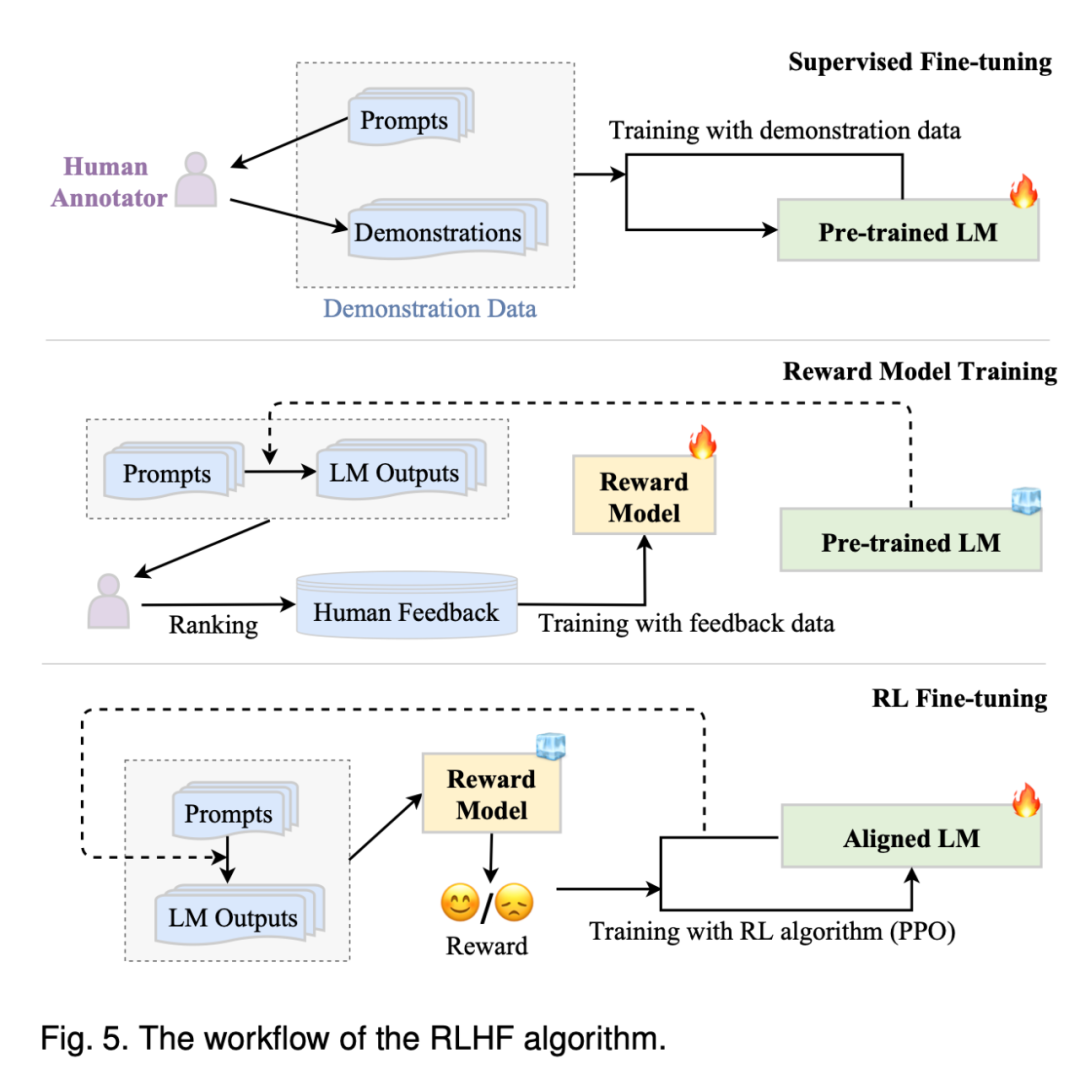
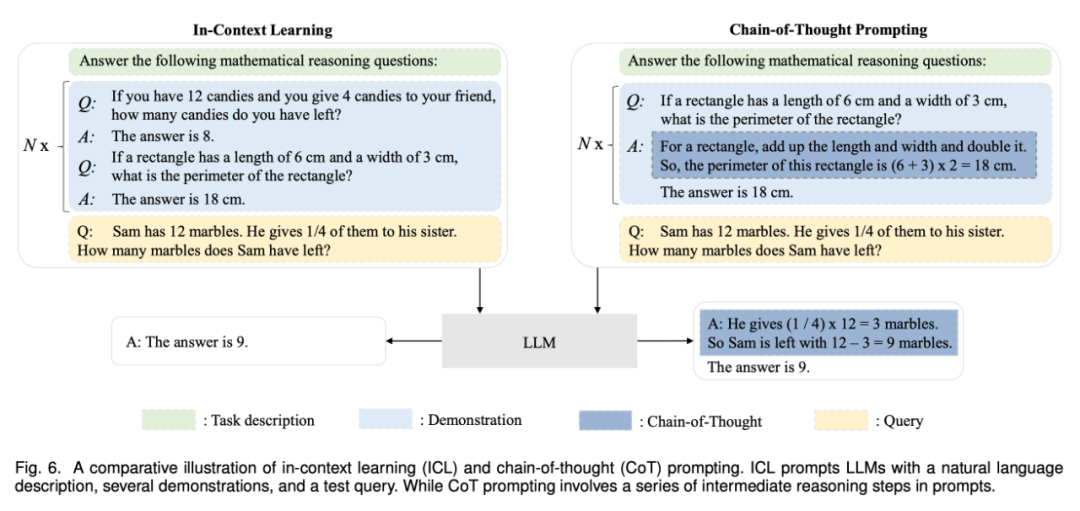

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复或发消息“BM53” 就可以获取《从T5到GPT-4最新最全梳理,人大等《大型语言模型综述》,51页pdf详述大模型进展》专知下载链接



登录查看更多
相关内容
Arxiv
20+阅读 · 2023年3月21日


相关VIP内容
相关资讯
相关论文
Arxiv
20+阅读 · 2023年3月21日