「视觉语言多模态预训练」最新2022研究综述 ,概述图像(视频)-文本预训练模型机制
浙江大学和海康威视最新《视觉语言多模态预训练》综述

多模态机器学习领域,为特定任务而制作的人工标注数据昂贵,且不同任务难以进行迁移而需要大量重新训练,导致训练多个任务的效率低下和资源浪费。预训练模型通过以自监督为代表的方式进行大规模数据训练,对数据集中不同模态的信息进行提取和融合,以学习其中蕴涵的通用知识表征,从而服务于广泛的相关下游视觉语言多模态任务,这一方法逐渐成为人工智能各领域的主流方法。依靠互联网所获取的大规模图文对与视频数据,以及以自监督学习为代表的预训练技术方法的进步,视觉语言多模态预训练模型在很大程度上打破了不同视觉语言任务之间的壁垒,提升了多个任务训练的效率并促进了具体任务的性能表现。为总结视觉语言多模态预训练领域的进展,本文首先对常见的预训练数据集和预训练方法进行了汇总,然后对目前最新的以及近年来经典的方法进行系统概述,按输入来源分为了图像-文本预训练模型和视频-文本多模态模型两大类,阐述了各方法之间的共性和差异,并将各模型在具体下游任务上的实验情况进行了汇总。最后,本文总结了视觉语言预训练面临的挑战和未来发展趋势。
http://www.cjig.cn/jig/ch/reader/view_abstract.aspx?flag=2&file_no=202203030000003&journal_id=jig
深度学习(deep learning, DL)方法在计算机视 觉(computer vision, CV)、自然语言处理(nature language processing, NLP)以及多模态机器学习(multimodal machine learning, MMML)的各个具体任务 上取得了令人瞩目的进展,但不同任务之间需要使 用专有的数据进行训练,大量的重新训练使得时间 和经济成本显著增加。预训练模型(pre-trained model, PTM)与微调(fine-tuning)相结合的范式旨在缓解 这一困难,预训练模型首先在大规模通用数据集上 利用自监督为代表的方式进行预训练,使得模型在 迁移至下游任务之前学习到通用的表征,然后在小 型专有数据集中进行微调得以获取特定任务知识 (Yosinski 等,2014)。这一方法在很大程度上打破 了各具体任务之间的壁垒,在避免重新训练所造成 的资源浪费的同时,对下游任务的性能起到促进作 用。Transformer(Vaswani 等,2017)是当前预训练 模型最为广泛使用的基础结构,其因为在处理长距 离依赖关系方面的优势,最初在机器翻译方面取得 了成功,随后广泛用于 NLP 领域。GPT(Radford 等, 2018)采用 Transformer 作为模型预训练的基础结构 在大规模语料库中进行预训练,将学习到语言知识 的参数模型用于具体任务,实验中 12 个下游的 NLP 任务性能取得了显著的提升。BERT(Devlin 等,2019) 采用了双向语言模型进行预训练,在语料中随机对 15%的单词令牌(token)进行掩码,要求模型可以 预测出原有单词令牌,此外还进行了句子预测任务, 实验中 11 个下游的 NLP 任务性能取得了提升。随 后的若干工作(Dong 等,2019;Liu 等,2019a;Radford 等,2019;Shoeybi 等,2019;Zellers 等, 2019;Yang 等,2019;Brown 等,2020;Lewis 等, 2020;Raffel 等,2020;Zhang 等,2020b,2021b;Fedus 等,2021;Sun 等,2021;琚生根 等,2022;强继朋 等,2022)证明预训练的语言模型能够普适 地对下游任务性能起到促进作用。受到 NLP 领域的 启发,CV 方面的研究者也相继开展基于Transformer 的视觉预训练工作。ViT(Dosovitskiy 等,2021)将图像的补丁块(patch)作为序列输入 Transformer 进 行预训练,克服 Transformer 结构难以处理图像输入 这一困难。CLIP(Radford 等,2021)将自然语言作 为监督以提升图像分类效果,使用对比学习 (contrastive learning, CL)方法促进图像和文本的匹 配能力。MAE(He 等,2021a)将 NLP 中常用的自 监督方法用于 CV 预训练,其通过训练自编码器, 预测经过随即掩码而缺失的图像 patch,从而高效、 准确地进行图像分类任务。
人类最具有抽象知识表达能力的信息为语言信息,而人类获取的最丰富的信息为视觉信息,上述工作分别在这两种模态上开展预训练并取得的成功。视觉语言任务(vision-and-language task)(Pan 等, 2016a,b;Tapaswi 等,2016;Yu 等,2016a;Jang 等,2017;Maharaj 等,2017)是典型的多模态机器 学习任务,其中视觉和语言两种模态的信息互相作 为指引,需让不同模态的信息对齐和交互,进行视 觉语言预训练(visual-language pre-training, VLP)工 作并提升模型在下游的视觉问题回答(visual question answering, VQA)(Johnson 等,2017)、视频描 述(video captioning)(Zhou 等,2018a,b,2019;)、 文本-视频检索(image-text retrieval)(Wang 等,2016, 2019;Song 和 Soleymani,2019b)等任务上的效果。视觉语言任务存在着很大的挑战。其中一个难点是, 使用何种易于大规模获得并且含有大量通用知识的 多模态数据来源,以构建训练数据集;另一个难点 是,怎样通过有效的机制,将属性相差巨大的不同 模态的信息进行统一训练。对于以上问题,一方面,当前的主要方法通过 获取来自互联网的图文对、包含语言描述的教学视 频、附带字幕的影视剧以及其他各类视频等视觉语 言多模态数据,制作涵盖广泛常识信息的大规模预 训练数据集;另一方面,设计能够处理多种模态信 息的神经网络模型,通过以自监督为代表的方式进 行大规模数据训练,对数据集中不同模态的信息进 行提取和融合,以学习其中蕴涵的通用知识表征, 从而服务于广泛的相关下游视觉语言多模态任务。
当前对预训练模型的综述工作主要集中在单模态(Qiu 等,2020;Kalyan 等,2021;Min 等,2021;陈德光 等,2021;韩毅 等,2022),部分工作梳理 视频-文本多模态类型(Ruan 和 Jin,2021),但较为 全面的 VLP 综述工作(Chen 等,2022)相对较少。本文梳理最新视觉语言多模态预训练模型的相关研 究成果,首先对 VLP 模型常用的预训练数据集和预 训练方法进行了简单介绍,然后在介绍基础结构之 后对 VLP 模型按视觉输入来源进一步分类, 介绍目 前具有代表性的图像-文本预训练模型和视频-文本 预训练模型,并根据模型结构不同分为了单流和双 流类型,重点阐述各研究特点,对不同 VLP 预训练 模型在主要下游任务上的性能表现也进行了汇总。最后对目前研究面临的问题进行探讨。
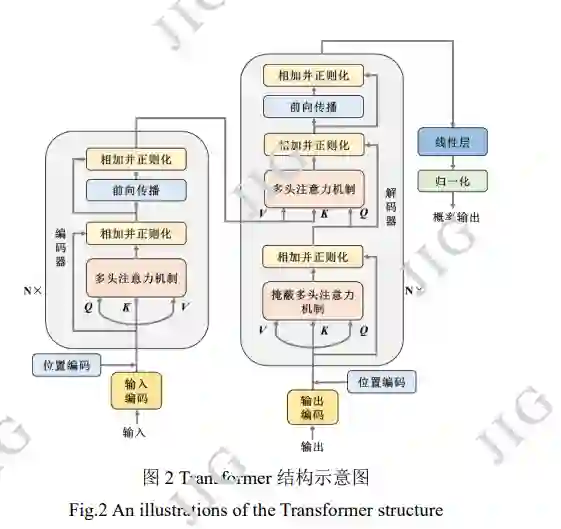
1 预训练数据集与预训练任务
在各类预训练任务中,模型性能受预训练数据 集质量的影响显著。为了获取通用的多模态知识, 视觉-语言预训练任务主要使用带有弱标签的视觉语言对进行模型训练。图像-文本任务主要为图像及 标题、内容描述、人物的动作描述等。类似地,视频 -语言预训练数据集包含大量的视频-文本对,其标签 来源包括视频中的文字描述以及由自动语音识别 (automatic speech recognition, ASR)技术获得的文 本信息等。部分模型为针对性提升某一模态的表征 提取能力,在多模态预训练之外还进行单模态数据 集进行预训练,使用如图片数据集与纯文本数据集。 预训练中常用的公开数据集有,图文数据集 SBU(Ordonez 等,2011),Flickr30k(Young 等, 2014),COCO Captions(Chen 等,2015),Visual Genome(VG)(Krishna 等,2017b),Conceptual Captions (CC, CC3M)(Sharma 等,2018)和 Conceptual 12M (CC12M)(Changpinyo 等,2021),VQA(Antol 等, 2015),VQA v2.0(Goyal 等,2019),Visual7W(Zhu 等,2016),GQA(Hudson 和 Manning,2019)。视 频数据集 TVQA(Lei 等,2018),HowTo100M(Miech 等,2019),Kinetics(Kay 等,2017),Kinetics-600 (Carreira 等,2018),Kinetics-700(Carreira 等, 2019),YT-Temporal-180M(Zellers 等,2021),WebVid-2M(Bain 等,2021)。单模态图片数据集 COCO (Lin 等,2014),OpenImages(Krasin 等,2017), 文本数据集 BooksCorpus(Zhu 等,2015)以及 English Wikipedia。数据集信息汇总如表 1 所示,以下对代 表性的数据集做进一步介绍。


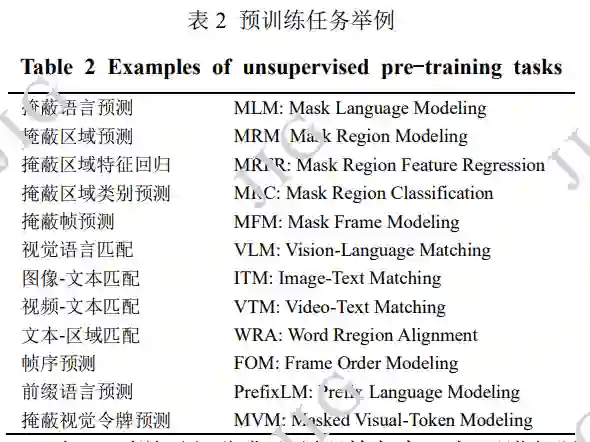
预训练任务
2 预训练模型
2.1 模型基础
本文根据特征在进行视觉和语言模态融合处理 之前,是否进行处理,将 VLP 模型按结构分为单流 式(single-stream)和双流式(cross-stream),其对比 如下图 1 所示。
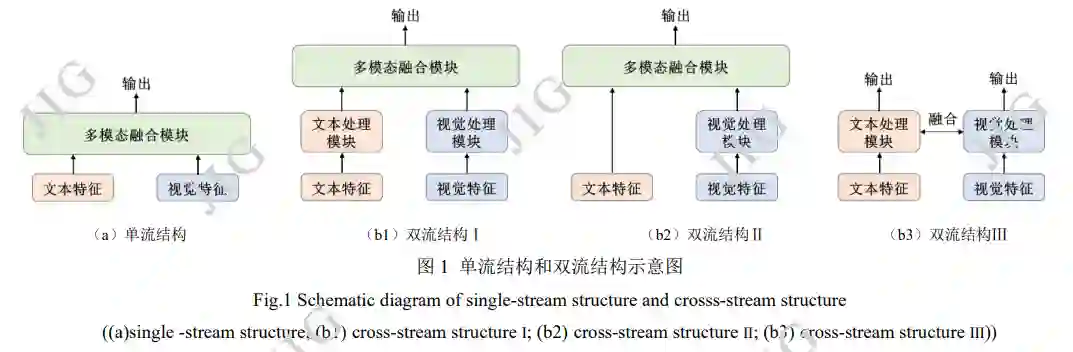
单流模型将视觉特征和语言特征直接输入融合 模块,进行模型训练,其典型方式如图 1(a)所示。双流模型将视觉特征和语言特征分别进行处理,然 后进行模态间的融合,典型类型包括但不限于图中三类,图 1(b1)中,模型首先对两路特征分别进行 处理,然后进行跨模态融合;如图 1(b2)中,视觉 特征经过视觉处理模块后,与文本特征一同送入多 模态融合模块进行交互;图 1(b3)中,两路特征送 入各自处理模块后进行交互式的参数训练。
2.2 图像-文本多模态预训练模型
单流模型相对双流模型结构较简单,一般将图 像与文本两种模态信息置于等同重要位置,对图像 和文本编码后共同输入跨模态融合模块进行预训练。 对于输入图像是否采用采用目标检测算法,可对研 究进行更细致的分类。


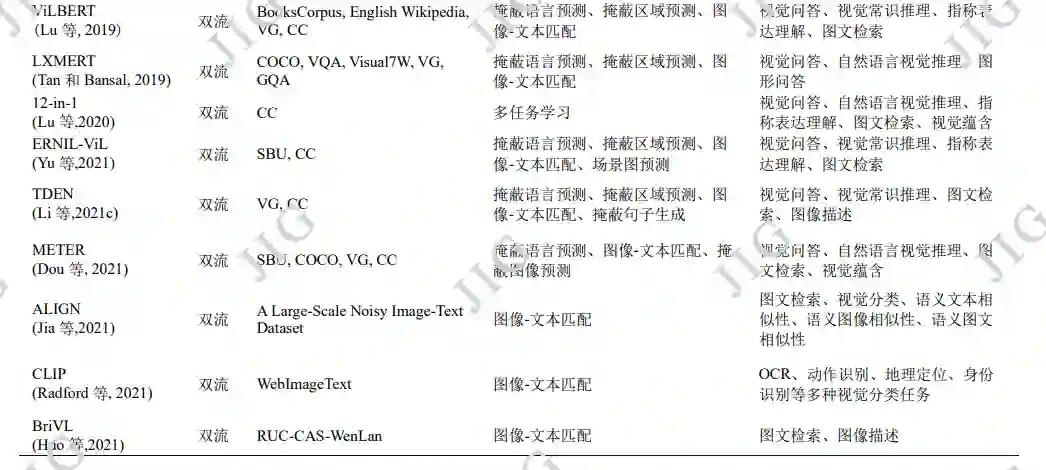
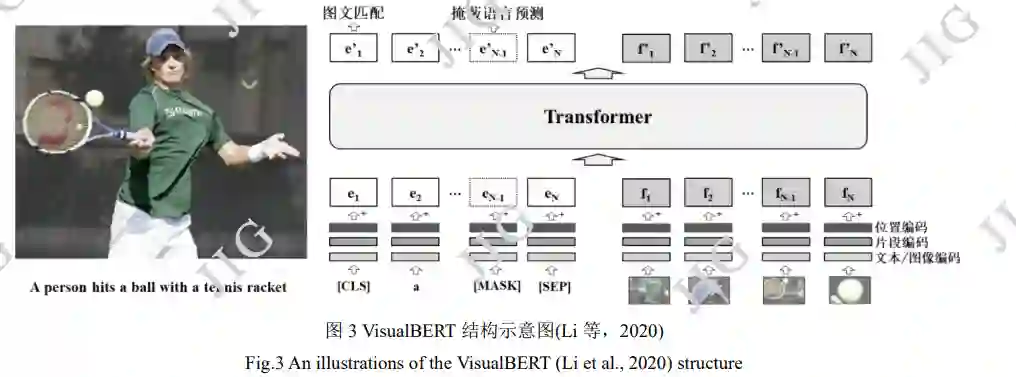

由于图像和文本信息在属性上区别较大,将不 同模态输入置于相同输入地位可能对模态间匹配造 成不良影响。在这一假设下,部分模型根据多模态 输入特点设计双流预训练模型,使用不同编码器灵 活处理各自模态特征,并通过后期融合对不同模态 进行关联。
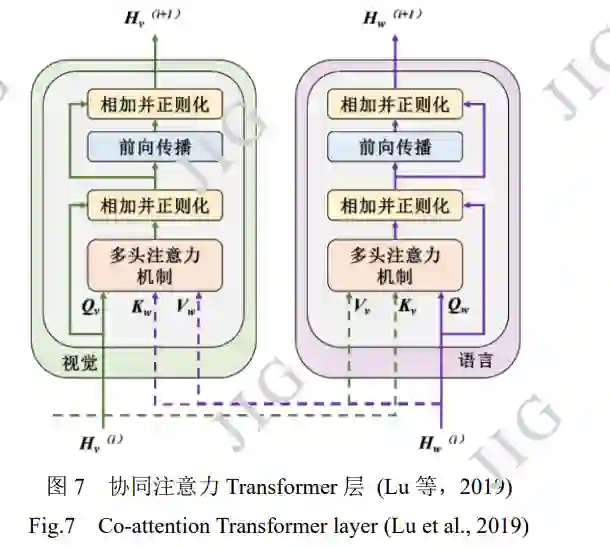
2.3 视频-文本多模态预训练模型
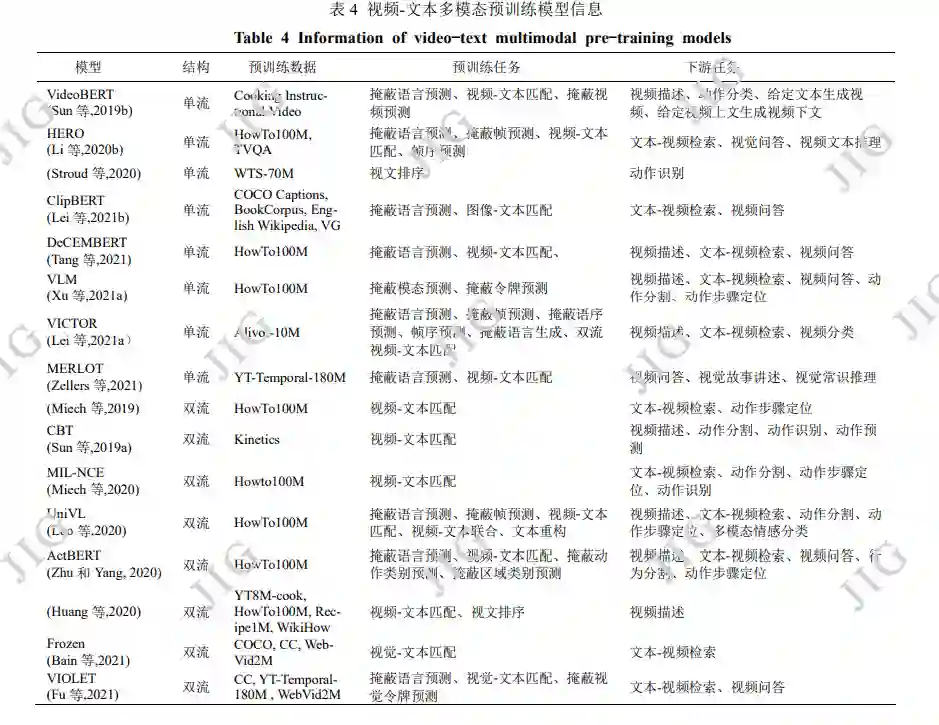
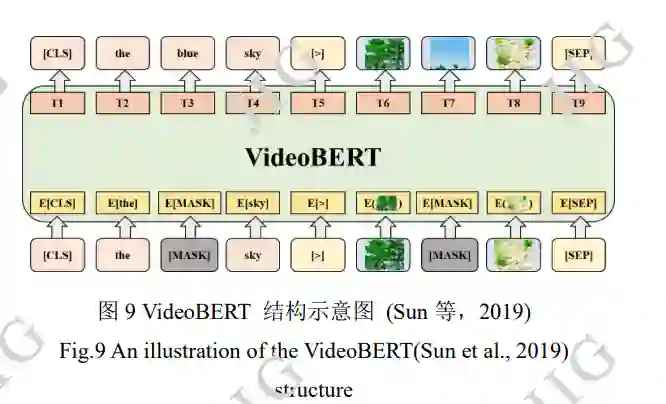
Sun 等人(2019b)提出的 VideoBERT 模型是第 一个将 Transformer 结构拓展到视频语言预训练的 工作,模型结构如图 9 所示。对 ASR 得到的文本输 入采取常用的类 BERT 处理,对于视频输入,按每 秒 20 帧采样速度从视频剪切多个 1.5s 视频片段, 应用预训练过的 S3D 提取视频特征,然后采用层级 k 聚类(hierachical k-means)标记视觉特征,以聚类 中心对视频特征进行矢量量化(vector quantization, VQ)操作。文本与视频的联合特征被送入多模态 Transformer进行MLM,VTM和掩蔽视频预测(video only mask completion, VOM)预训练任务。VOM 以 聚类的视频片段作为被掩蔽和预测的视觉单元。模 型目标是学习长时间高级视听语义特征,如随时间 推移而展开的事件与动作,采用网络收集的厨艺教 学视频作为预训练数据,在预设下游任务上表现良 好,但由于视觉中心代表的视觉信息难以全面描述 视频内容,使得模型的泛化性受到一定限制。
Miech 等人(2019)提出了视频文本预训练中被 广泛使用的大规模叙述性视频数据集 HowTo100M, baseline 方法将提取到的视频和文本特征映射到相 同维度从而优化模态间的关联性。Miech等人(2020) 进一步研究发现 HowTo100M 中由于人的讲述与画 面展示不同步,导致大约 50%的视频剪辑片段与 ASR 描述文本没有对齐(如图 10 所示)。为解决这 一偏差问题引入了多实例学习(multiple instance learning, MIL),基于同一视频中连续时间内画面语 义相似的前提,在目标视频片段的相邻时间内截取 多个视频-描述对作为对比学习的候选正例。然后采 用噪声估计 NCE 来优化视频文本联合特征的学习, 提出了 MIL-NCE,在 8 个数据集 4 类下游任务中表 现良好。MIL-NCE 方法在后续使用 HowTo100M 数 据集的预训练模型中广泛使用。
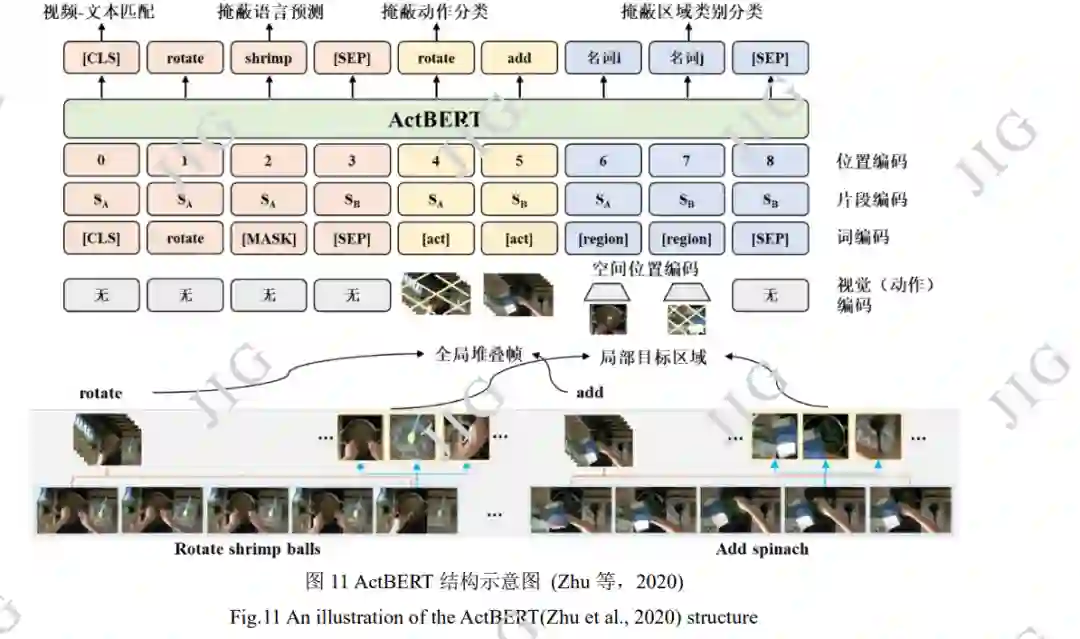
Zhu 等(2020)提出了全局局部动作 VLP 模型 ActBERT,结构如图 11 所示,对于视频输入采取两 种编码处理。首先是动作编码,加入全局堆叠帧获 取全局动作信息,动作信息来自每个视频相应描述 中提取动词所构建的字典,为简化问题删除了没有 任何动词的视频片段。然后是视觉编码,加入经 Faster-RCNN 对图像提取的 RoI 特征获取局部区域 信息。ActBERT 利用全局动作信息来促进文本与局 部目标区域间的交互,使一个视觉中心能同时描述 局部和全局视觉内容,提升视频和文本的关联性。 引入了掩蔽动作分类(mask action classification, MAC),即随机掩蔽输入的动作表示向量,使模型通 过其他信息如文本信息和物体信息来预测出动作标 签。模型在 5 类下游任务上表现良好。
3. 下游任务性能对比
3.1 图像-文本多模态预训练模型
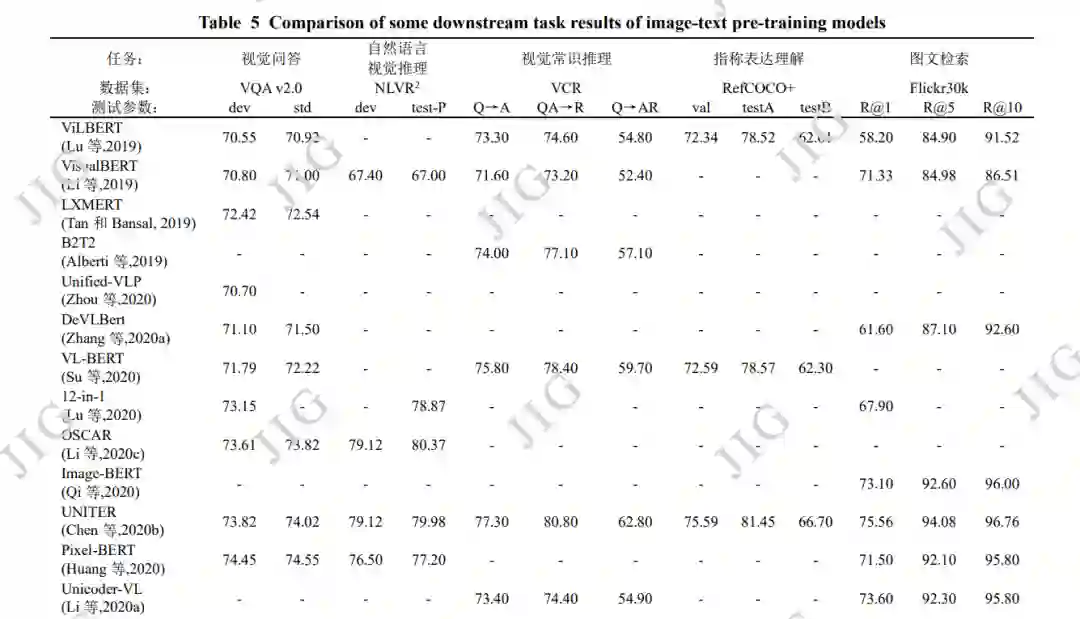
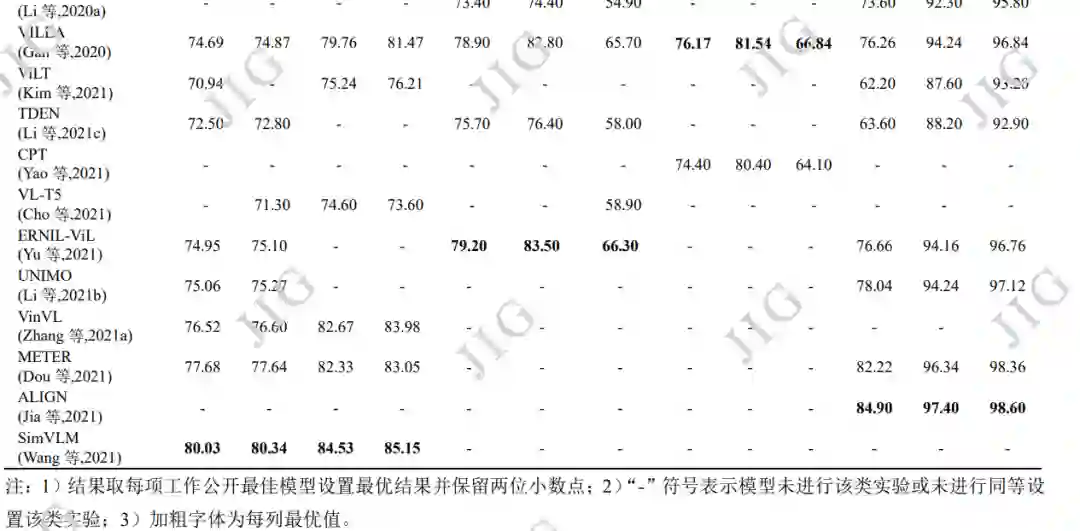
图像-文本多模态下游任务繁多,代表性的任务 有分类任务如视觉问答(Johnson 等,2017;Hudson 和 Manning,2019)),自然语言视觉推理(natural language visual reasoning, NLVR)(Suhr 等,2017, 2018),视觉常识推理(Gao 等,2019);指称表达理解(referring expression comprehension, REC)(Yu 等, 2016b;Mao 等,2016),视觉蕴含(visual entailment, VE)(Xie 等,2018a,2019)等,检索任务如图文检 索(image-text retrieval)(Karpathy 和 Li,2015; Plummer 等,2015;Lee 等,2018);生成任务如图 像描述(Vinyals 等,2015;Xu 等,2015;Anderson 等,2018),新对象图像描述(novel object captioning, NoCaps )( Agrawal 等 , 2019 ) 及 多 模 态 翻 译 (multimodal translation)(Elliott 等,2016)。如下对 表 5 中 VLP 模型所进行对比的下游任务与相关数据 集进行进一步介绍。
3.2 视频-文本多模态预训练模型
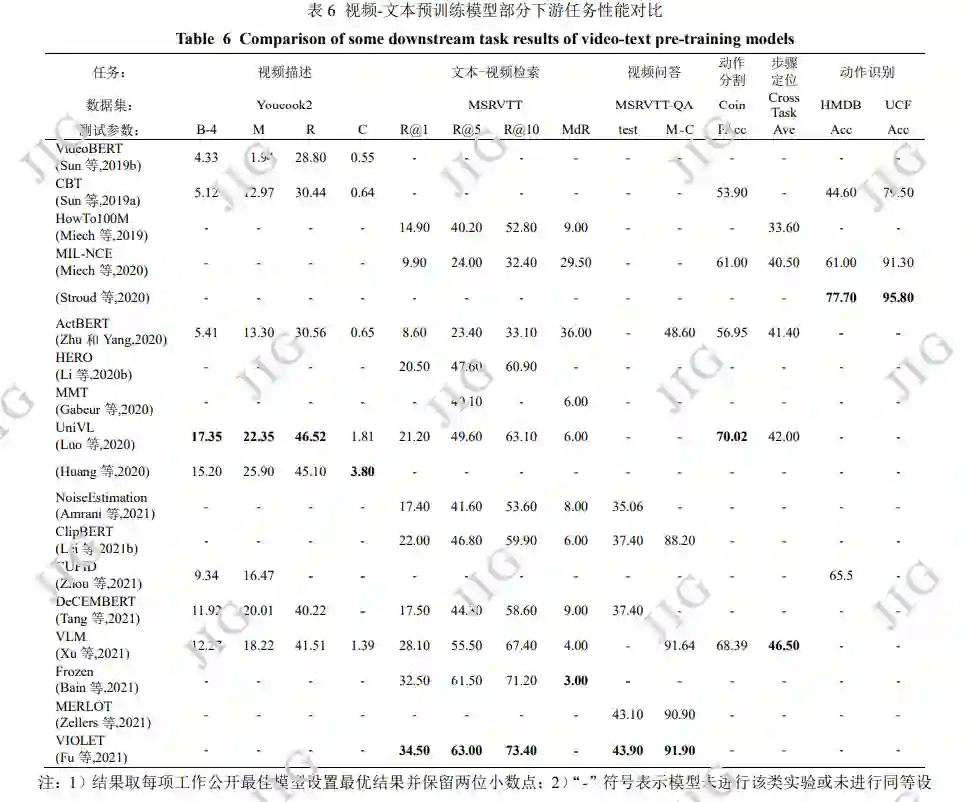
关于视频的视觉-语言交叉任务同样覆盖广泛, 代表性的任务有视频描述(Gan 等,2017;Krishna 等,2017a);文本-视频检索(Gao 等,2017;Hendricks 等,2017;Mithun 等,2018;Lei 等,2020b);视频 问答(video question answering)(Yu 等,2018;Lei 等,2020a);动作分割(action segmentation)(Tang 等,2019);步骤定位(action step localization) (Zhukov 等,2019);动作识别(Kuehne 等,2011; Soomro 等,2012);视频摘要(video summarization) (Plummer 等,2017);视觉故事讲述(visual storytelling)(Agrawal 等,2016 ;Huang 等,2016)。 如下对表 6 中 VLP 模型所进行对比的下游任务与相 关数据集进行进一步介绍
4 问题与挑战
视觉语言多模态预训练作为前沿研究,尽管在 下游视觉语言交叉任务上已经有了不错表现,但在 未来工作中还需考虑以下几个方向:
1)训练数据域的差异
预训练数据集与下游任务数据集之间存在数据 域的差异,部分工作表明(Zhou 等 2021),与预训 练数据集的域相一致的下游任务数据集可以显著提 升任务表现,而数据域的差异是造成模型在不同任 务之间迁移时性能下降的重要原因。HERO(Li 等 2020b)指出,不能通过增加微调过程的数据规模, 来缩小下游任务数据与预训练数据的域差异所造成 的影响。MERLOT(Zellers 等,2021)使用较为多 样的预训练数据,增大了数据域的分布,在一定程 度上提升了模型的性能,但也增加了训练消耗。因 此,如何提升预训练数据集的质量和多样性是今后 预训练任务的重要课题。
2)知识驱动的预训练模型
预训练模型的本质是通过参数量极大的神经网 络对大规模训练数据进行拟合,以学习潜在的通用 知识,在此过程中扩大数据规模可以带来预训练性 能的提升,但会增加计算资源和能耗的消耗,因此 一味通过增加数据和训练量换取性能的思路是难以 持续的。对于输入的图文、视频等多模态信息,存在 着大量隐含的外部常识信息可以用于更快速的引导 模型对于事件内容的挖掘(Chen 等,2021),因此探 索如何通过知识驱动的方式建立具有广泛知识来源 的模型架构,将知识图谱等结构化知识注入模型, 探索轻量化的网络结构,从而增加模型的训练效率 和可解释性,是预训练模型的具有前景的方向。
3)预训练模型的评价指标
现有的视觉语言预训练模型大多在少数几个下 游数据集上进行效果的实验验证,难以确切判断在 其它数据集上的有效性,而真正通用的预训练系统 应该在广泛的下游任务、数据域和数据集上进行推 广,这就需要建立较为通用的预训练评价指标,来 有效评价预训练效果,并指出模型是否易于在不同 任务和数据之间进行迁移。VALUE(Li 等,2021a) 作为一个视频语言预训练评价基准,覆盖了视频、 文本、音频输入,包含了视频检索、视觉问答、字幕 匹配任务的 11 个数据集,根据不同难度的任务的元 平均得分(meta-average score)度量预训练模型的性 能。但这类工作目前正处于起步阶段,相关的研究 也被研究者重点关注。
4)探索多样的数据来源
视频中的音频包含了丰富的信息,当前视频预 训练中常使用 ASR 方法将音频转换为文本,在此 过程中部分原有信息损失掉了,因此探索包含音频 的预训练模型是一个可取的方向。目前的多模态预 训练数据来源以英文图文和视频为主,进行多语言 学习的预训练工作较少,将模型在不同语言间进行 迁移还需要继续研究。此外,探索从结构化的多模 态数据中进行更细粒度的预训练工作(Zellers 等, 2021),如从图表中进行目标推理的训练等。
5)预训练模型的社会偏见和安全性
由于大规模数据集在来源上涉及范围广泛,难 以逐一排查具体信息,数据中难以避免地存在部分 社会偏见以及错误知识,而通过预训练模型由于学 习到了这些不良内容,其生成的结果会进一步增加 这类内容所造成了影响,造成更大的社会问题 (Dixon 2008)。因此在获取数据时如何对存在的 数据隐私,以及涉及国家、种族、性别公平性等问 题进行考量,通过算法对选取的预训练数据内容进 行过滤,在社会安全、伦理等方面尤其重要。
5 结 语
视觉和语言在人类学习视觉实体与抽象概念的 过程中扮演着重要的角色,本文对视觉语言多模态 预训练领域自 2019 年以来的模型与方法,基于视觉 来源从图像-文本与视频-文本两大方向进行综述, 并进一步基于模型结构分别介绍各具体模型的特点 与研究贡献。此外,还介绍了常用视觉语言多模态 预训练模型数据集、预训练任务设定以及各模型在 主要下游任务上的表现。 最后对该领域的问题与挑 战进行了总结并提出未来研究方向。希望通过本文 让读者了解当前工作的前沿,以启发进而做出更有 价值的多模态预训练工作。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“VLMP” 就可以获取《「视觉语言多模态预训练」最新2022研究综述 》专知下载链接





