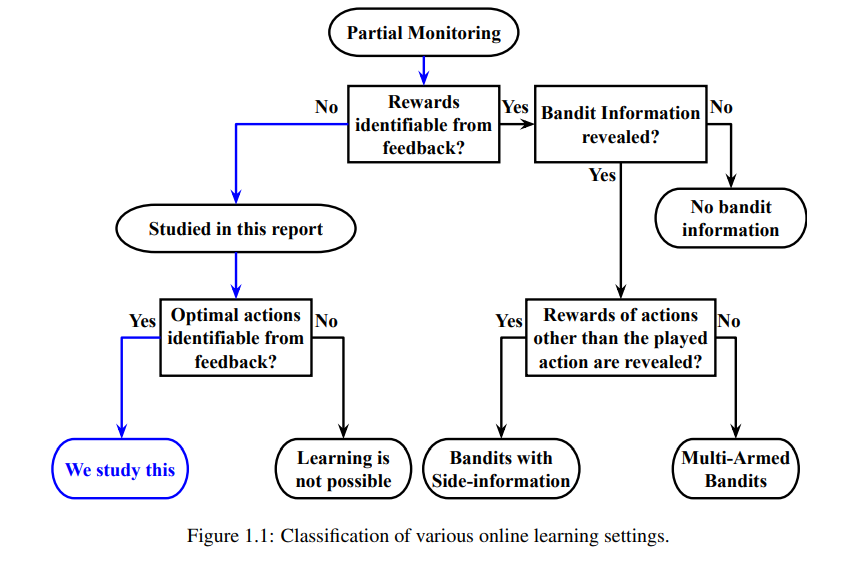
文献中考虑的许多序列决策问题变体取决于反馈的类型和它们揭示的有关相关奖励的信息量。之前的大多数工作都研究了行动的反馈揭示了与行动相关的奖励的案例。然而,在许多领域,如众包、医疗诊断和自适应资源分配,行动的反馈可能是薄弱的,即可能根本没有揭示任何关于奖励的信息。如果没有任何关于奖励的信息,就不可能了解哪种行动是最佳的。显然,只有在问题结构是这样的,即可以在不明确知道奖励的情况下识别最佳行动的情况下,学习最佳行动才是可行的。本文的目标是研究一类问题,在不明确知道奖励的情况下可以推断出最优行动。研究了无监督顺序选择(USS),所选行动的回报/损失从未显示,但问题结构适合于识别最优行动。本文还提出了一种名为审查半Bandits (CSB)的新设置,从一个行动中观察到的奖励取决于分配给它的资源数量。
本文的主要研究内容是USS问题。在USS问题中,无法从观察到的反馈中推断出与动作相关的损失。这种情况出现在许多现实应用中。例如,在医疗诊断中,患者的真实状态可能不为人知;因此,测试的有效性无法得知。在众包系统中,众包工人的专业知识水平是未知的;因此,他们的工作质量是不可知的。在此类问题中,可以观察到测试/工作者的预测,但由于缺乏真实值,无法确定其可靠性。通过比较不同动作得到的反馈,可以找到一类USS问题在满足“弱支配”性质时的最优动作。针对该问题,本文提出了基于置信上界和Thompson采样的性能最优算法。
本文提出一种称为审查半bandits (CSB)的新设置,其中从行动中观察到的反馈取决于分配的资源数量。如果没有分配足够的资源,反馈就会被“审查”。在CSB设置中,学习者在每一轮中在不同的活动(动作)之间分配资源,并从每个动作中接受审查损失作为反馈。目标是学习一种资源分配策略,使累计损失最小化。每个时间步长的损失取决于两个未知参数,一个与动作有关,但与分配的资源无关,另一个取决于分配的资源数量。更具体地说,如果动作的资源分配超过一个恒定的(但未知的)阈值,该阈值可以取决于动作,则损失等于零。CSB模型可以应用于许多资源分配问题,如警察巡逻、交通规则和执行、偷猎控制、广告预算分配、随机网络效用最大化等。
论文的最后一部分重点研究了多玩家多臂匪徒的分布式学习,以识别最优动作子集。这种设置是这样的,奖励只适用于那些只有一个玩家参与的行动。这些问题适用于无线ad hoc网络和认知无线电中寻找最佳通信信道的问题。本文的贡献是通过利用这些问题表现出的特定结构来解决上述序列决策问题。对于这些具有弱反馈的每个设置,开发了可证明的最优算法。最后,在合成数据集和真实数据集上验证了它们在不同问题实例上的经验性能。
https://www.zhuanzhi.ai/paper/309b90e6694df9044e90a6f254fa559a