

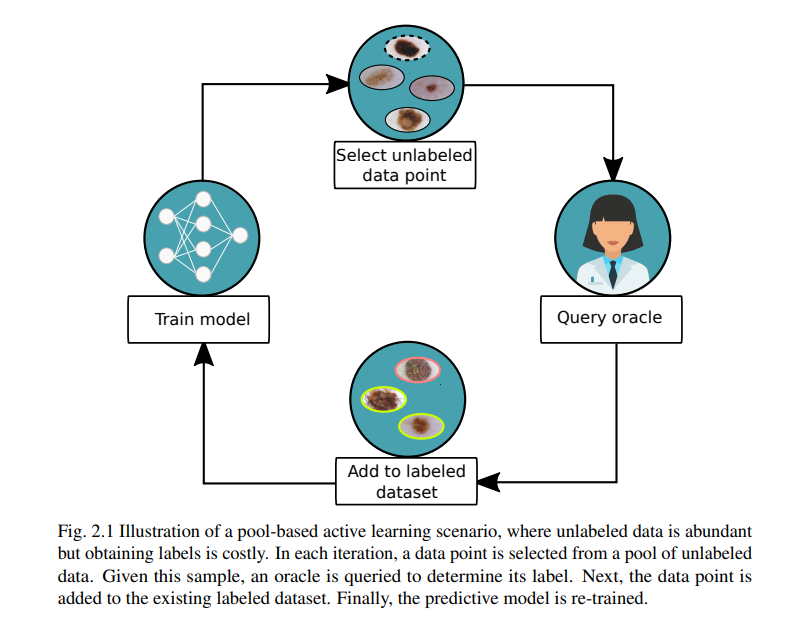
**最近机器学习方法的大部分成功都是通过利用过去几年产生的大量标记数据而实现的。**然而,对于一些重要的实际应用来说,如此大规模的数据收集仍然是不可行的。这包括机器人、医疗健康、地球科学和化学等领域,在这些领域获取数据可能既昂贵又耗时。在本文中,我们考虑三个不同的学习问题,其中可以收集的数据量是有限的。这包括在在线学习期间限制对标签、整个数据集和生成经验的访问的设置。本文通过采用序列决策策略来解决这些数据限制,这些策略在收集新数据和根据新获得的证据做出明智的决策之间迭代。**首先,解决标签获取成本较高时如何高效地收集批量标签的问题。**概率主动学习方法可用于贪婪地选择信息量最大的待标记数据点。然而,对于许多大规模问题,标准的贪心算法在计算上变得不可行。为缓解这个问题,本文提出一种可扩展的贝叶斯批量主动学习方法,其动机是近似模型参数的完整数据后验。
**其次,我们解决了自动化分子设计的挑战,以加速对新药物和材料的搜索。**由于迄今为止只探索了化学空间的一个小区域,可用于某些化学系统的数据量是有限的。本文通过将3D分子设计问题制定为强化学习任务,克服了生成模型对数据集的依赖,并提出了一种对称感知策略,可以生成用以前方法无法实现的分子结构。
**最后,我们考虑了如何在不同任务中有效地学习机器人行为的问题。**实现这一目标的一个有希望的方向是在不同的任务上下文中泛化局部学习的策略。上下文策略搜索通过显式地将策略约束在参数化上下文空间上,从而提供数据高效的学习和泛化。进一步构建上下文策略表示,在各种机器人领域实现更快的学习和更好的泛化。



成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年3月31日
Arxiv
0+阅读 · 2023年3月30日
Arxiv
14+阅读 · 2021年2月14日


相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2023年3月31日
Arxiv
0+阅读 · 2023年3月30日
Arxiv
14+阅读 · 2021年2月14日