

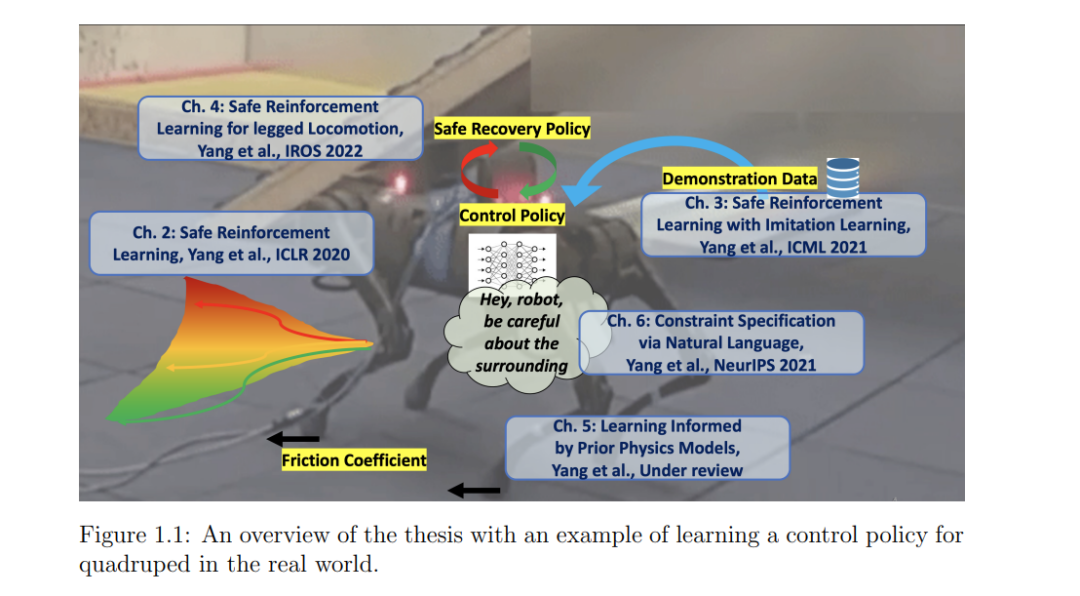
为自动驾驶汽车等自动系统设计控制策略是复杂的。为此,研究人员越来越多地使用强化学习(RL)来设计策略。然而,对于安全攸关系统而言,保障其在实际训练和部署过程中的安全运行是一个尚未解决的问题。此外,当前的强化学习方法需要精确的模拟器(模型)来学习策略,这在现实世界的应用中很少出现这种情况。**本文介绍了一个安全的强化学习框架,提供了安全保证,并开发了一种学习系统动力学的受限学习方法。本文开发了一种安全的强化学习算法,在满足安全约束的同时优化任务奖励。在提供基线策略时,考虑安全强化学习问题的一种变体。**基线策略可以产生于演示数据,可以为学习提供有用的线索,但不能保证满足安全约束。本文提出一种策略优化算法来解决该问题。将一种安全的强化学习算法应用于腿部运动,以展示其在现实世界的适用性。本文提出一种算法,在使机器人远离不安全状态的安全恢复策略和优化的学习器策略之间进行切换,以完成任务。进一步利用系统动力学的知识来确定策略的切换。结果表明,我们可以在不摔倒的情况下在现实世界中学习腿部运动技能。重新审视了已知系统动力学的假设,并开发了一种从观察中进行系统辨识的方法。知道系统的参数可以提高模拟的质量,从而最小化策略的意外行为。最后,虽然safe RL在许多应用中都有很大的前景,但目前的方法需要领域专业知识来指定约束。本文引入了一个新的基准,在自由格式的文本中指定约束。本文开发了一个模型,可以解释和遵守这种文本约束。我们证明该方法比基线获得了更高的回报和更少的约束违背。


成为VIP会员查看完整内容




相关内容

普林斯顿大学,又译
普林斯敦大学,常被直接称为
普林斯顿,是美国一所私立研究型大学,现为八所常青藤学校之一,绰号为老虎。
Arxiv
15+阅读 · 2020年12月15日


相关VIP内容
相关资讯
相关论文
Arxiv
15+阅读 · 2020年12月15日