
题目: Efficient AutoML Pipeline Search with Matrix and Tensor Factorization
摘要:
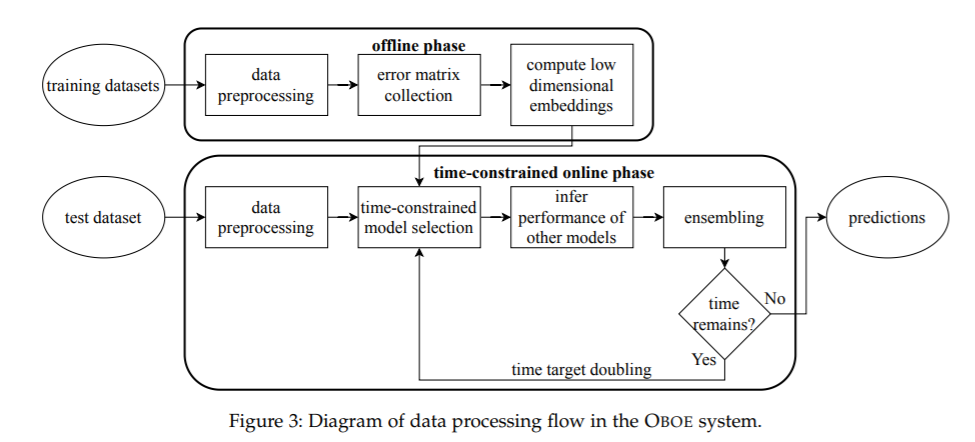
数据科学家在新的数据集上寻找一个好的监督学习模型有很多选择:他们必须对数据进行预处理,选择特征,可能减少维数,选择估计算法,并为每个管道组件选择超参数。与新的管道组件来一个组合爆炸的数量的选择。在这项工作中,文中设计了一个新的自动系统来解决这个挑战:一个自动系统来设计一个监督学习管道。系统使用矩阵和张量因子分解作为代理模型来建模组合管道搜索空间。在这些模型下,开发了贪婪实验设计协议,以有效地收集新数据集的信息。对大量真实世界分类问题的实验证明了该方法的有效性。
成为VIP会员查看完整内容
相关内容

专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
31+阅读 · 2020年5月20日
Arxiv
7+阅读 · 2018年3月26日
Arxiv
17+阅读 · 2017年12月12日

相关VIP内容
专知会员服务
99+阅读 · 2020年7月6日
专知会员服务
31+阅读 · 2020年5月20日
相关资讯
相关论文
Arxiv
7+阅读 · 2018年3月26日
Arxiv
17+阅读 · 2017年12月12日