我们精心挑选了22种开源自动机器学习库,你pick谁?

更多干货内容请关注微信公众号“AI 前线”(ID:ai-front)
典型的机器学习项目包含不同的步骤:收集原始数据、合并数据源、清理数据、特征工程、模型构建、超参数调整、模型验证和部署。数据科学家可以为模型构建阶段贡献自己的聪明才智,但有趣的是,最耗时的机器学习部分似乎是特征工程和超参数调整。因此,很多模型并不是最优的,由于受到时间限制,它们过早地从实验阶段进入到生产环境,或者因为花了太多时间调优导致到生产环境的部署被延迟。
自动机器学习(AutoML)框架减少了数据科学家的负担,他们可以花更少的时间进行特征工程和超参数调整,花更多的时间用于试验模型架构。快速探索解决方案空间不仅让数据科学家可以快速地评估数据集,还为模型改进提供了基线性能。
我们调研了一些开源框架,它们可以用于自动化机器学习管道的一个或多个部分。机器学习管道的这些部分可以通过自动框架进行模型构建、特征工程和超参数优化,因此我们对声称可以优化这些任务的成熟框架进行了分析。我们选择能够让数据科学团队以最少的工作量把它们包含在机器学习管道中的库。我们的评估标准包括:库要实现的目标、库实现的统计方法,以及在决定是否将其与新项目或现有项目进行集成时需要考虑的主要因素。
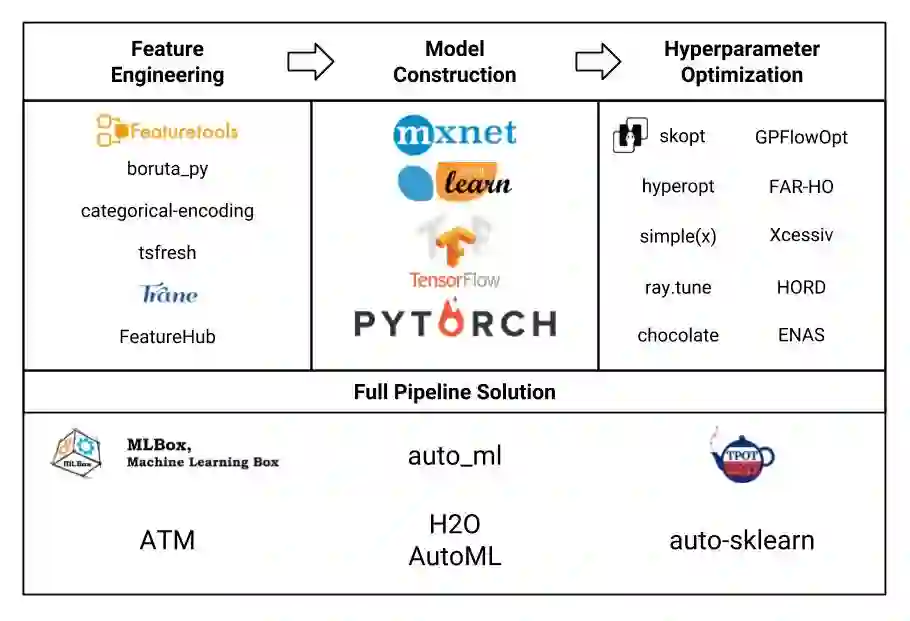
一些 AutoML 解决方案解决了数据科学管道的单个部分。它们不提供端到端的解决方案,一般侧重于实现最前沿的方法来解决特定问题,或被用在具有独特约束的特定环境中。
项目地址:https://github.com/Featuretools/featuretools
Star:1,347
Fork:139
最新发布:2018 年 5 月 30 日(0.1.21)
featuretools 是一个旨在通过利用关系数据库数据集中的模式来解决特征工程问题的开源库。它使用了深度特征合成(DFS)算法,这个算法会遍历关系数据库模式所描述的数据关系路径。DFS 在遍历这些路径时,通过应用于数据的操作(如 sum、average、count)来生成合成特征。例如,它可以对来自给定客户 ID 的事务列表进行 sum 操作。不过这是一个深度操作,算法可以遍历更深层的特征。featuretools 的最大优势在于它的可靠性以及在使用时间序列数据时处理信息泄漏的能力。
项目地址:https://github.com/scikit-learn-contrib/boruta_py
Star:318
Fork:82
最新发布:2017 年 3 月 5 日(0.1.5)
boruta-py 是 brouta 特征消减策略的一种实现,其中问题是以“完全相关”的方式进行构建,算法将保留对模型有显著贡献的所有特征。这与其他很多特征消减算法所使用的“最小化最优”特征集相反。
boruta 通过创建由目标特征的随机排序值组成的合成特征来确定特征重要性,然后在原始特征集上训练基于简单树的分类器和在合成特征中替换目标特征的特征集。所有特征的性能差异被用于计算相关性。
项目地址:https://github.com/scikit-learn-contrib/categorical-encoding
Star:494
Fork:115
最新发布:2018 年 1 月 22 日(1.2.6)
这个库扩展了很多实现 scikit-learn 数据转换器接口的分类编码方法,并实现了常见的分类编码方法,例如单热编码和散列编码,也有更利基的编码方法,如基本编码和目标编码。这个库对于处理现实世界的分类变量来说很有用,比如那些具有高基数的变量。这个库还可以直接与 pandas 一起使用,用于计算缺失值,以及处理训练集之外的变换值。
项目地址:https://github.com/blue-yonder/tsfresh
Star:2,781
Fork:340
最新发布:2017 年 10 月 14 日(0.11.0)
这个库专注于基于时间序列数据生成特征,由德国零售分析公司开源,并提供支持。它从时间序列数据中提取描述时间序列趋势的特征列表。这些特征包括像方差一样简单的特征和与近似熵一样复杂的特征。这个库能够从数据中提取趋势,让机器学习算法更容易地解释时间序列数据集。它通过假设检验来获取大量生成的特征集,并将其消减到最能解释趋势的特征。tsfresh 与 pandas 和 sklearn 兼容,从而可以插入到现有的数据科学管道中。Tsfresh 的主要功能是它的可伸缩数据处理能力,并已在具有大量时间序列数据的生产系统中得到了验证。
项目地址:https://github.com/HDI-Project/Trane
Star:4
Fork:1
最新发布:2018 年 2 月 5 日(0.1.0)
这个库是麻省理工学院 HDI 项目的产品。Trane 可以处理存储在关系数据库中的时间序列数据,用于表述时间序列问题。数据科学家可以通过指定数据集元信息让这个引擎表述数据库的时间序列数据的监督问题。这个过程通过 json 文件进行描述,数据科学家将在这个文件中描述列和数据类型。这个框架会处理这个文件,并生成可能的预测问题,而这些问题又可用于修改数据集。这个项目可用于以半自动化的方式生成其他特征。
项目地址:https://github.com/HDI-Project/FeatureHub
Star:32
Fork:5
最新发布:2018 年 5 月 9 日(0.3.0)
来自麻省理工学院 HDI 实验室的另一个项目,FeatureHub 建立在 JupyterHub 之上,可以让数据科学家在开发特征工程方法时进行协作。FeatureHub 会自动给生成的特征“打分”,以确定模型的总体价值。
项目地址:https://scikit-optimize.github.io/
Star:880
Fork:340
最新发布:2011 年 3 月 25 日(0.5.2)
Skopt 是一个超参数优化库,包括随机搜索、贝叶斯搜索、决策森林和梯度提升树。这个库提供了可靠的优化方法,不过这些模型在给定较小的搜索空间和良好的初始估计值时表现最佳。
项目地址:https://github.com/hyperopt/hyperopt-sklearn
Star:2,161
Fork:473
最新发布:2016 年 11 月 20 日(0.1)
Hyperopt 是一个超参数优化库,可以调整“笨拙”的条件或受约束的搜索空间。它支持跨多台机器的并行化,使用 MongoDb 作为存储超参数组合结果的中心数据库。这个库通过 hyperopt-sklearn 和 hyperas 来实现,而这两个模型选择和优化库又分别是基于 scikit-learn 和 keras 构建的。
项目地址:https://github.com/chrisstroemel/Simple
Star:362
Fork:22
最新发布:处于实验阶段,需要手动安装
simple(x) 是一个优化库,是贝叶斯优化算法的一个替代方案。与贝叶斯搜索一样,simple(x) 尝试使用尽可能少的样本进行优化,并将计算复杂度从 n³降低到 log(n),因此对大型搜索空间非常有用。这个库使用单形(n 维三角形)而不是超立方体(n 维立方体)对搜索空间进行建模,这样做可以避免计算成本高昂的高斯过程。
项目地址:https://github.com/ray-project/ray/tree/master/python/ray/tune
Star:3,435
Fork:462
最新发布:2018 年 3 月 27 日(0.4.0)
Ray.tune 是一个超参数优化库,主要针对深度学习和强化学习模型。它结合了很多尖端的算法,如超频(最低限度地训练可用于确定超参数效果的模型的算法)、基于人口的训练(在共享超参数的同时调整多个模型的算法)、响应面算法和中值停止规则(如果模型的性能低于中值就将其停止)。这一切都运行在 Ray 分布式计算平台之上,这使得它具有极高的可扩展性。
项目地址:https://github.com/AIworx-Labs/chocolate
Star:26
Fork:26
最新发布:处于实验阶段,需要手动安装
Chocolate 是一种分散的(支持没有中央主节点的并行计算集群)超参数优化库,它使用公共数据库来联合各个任务的执行,支持网格搜索、随机搜索、准随机搜索、贝叶斯搜索和协方差矩阵自适应进化策略。它的独特的功能包括支持受约束的搜索空间和优化多个损失函数(多目标优化)。
项目地址:https://github.com/GPflow/GPflowOpt
Star:102
Fork:27
最新发布:2017 年 9 月 11 日(0.1.0)
GpFlowOpt 是一个基于 GpFlow 的高斯过程优化器,GpFlow 是一个使用 Tensorflow 在 GPU 上运行高斯过程任务的库。如果需要贝叶斯优化并且具有可用的 GPU 计算资源,那么 GpFlowOpt 会是一个理想的优化器。
项目地址:https://github.com/lucfra/FAR-HO
Star:22
Fork:5
最新发布:处于实验阶段,需要手动安装
FAR-HO 是一个包含了一组在运行在 Tensorflow 上的基于梯度的优化器。这个库的目的是提供对 Tensorflow 中基于梯度的超参数优化器的访问,允许在 GPU 或其他针对张量优化的计算环境中进行模型训练和超参数优化。
项目地址:https://github.com/reiinakano/xcessiv
Star:1,055
Fork:76
最新发布:2017 年 8 月 20 日(0.5.1)
Xcessiv 是一个用于大规模模型开发、执行和集成的框架。它的强大之处在于能够通过单个 GUI 来管理大量机器学习模型的训练、执行和评估。它还提供了多个集成工具,用于组合这些模型以实现最佳性能。它提供了一个贝叶斯搜索参数优化器,支持高水平的并行,并且还支持与 TPOT 的集成。
项目地址:https://github.com/ilija139/HORD
Star:52
Fork:8
最新发布:处于实验阶段,需要手动安装
HORD 是一种用于超参数优化的独立算法。它为黑盒模型生成一个代理函数,并使用代理函数来生成可能接近理想的超参数,以消减对完整模型的评估。与 parzen estimator、SMAC 和高斯过程相比,它始终表现出更高的一致性和更低的错误率。它特别适用于具有极高维度的情况。
项目地址:https://github.com/ilija139/HORD
Star:848
Fork:135
最新发布:处于实验阶段,需要手动安装
ENAS-pytorch 使用 pytorch 实现了高效的神经架构搜索。它通过共享参数来实现最快的网络,非常适用于深度学习架构搜索。
这些解决方案要么与前面提到的解决方案很相似,要么仍在开发当中。在这里列在供参考:
Gpy/GpyOpt(高斯过程超优化库)
auto-keras(Keras 架构和超参数搜索库)
randopt(实验管理和超参数搜索库)
随着机器学习的不断发展,很多公司如雨后春笋般涌现,以解决整个数据科学过程中出现的各种问题。以下是一些 AutoML 公司列表。由于我们没有对这些解决方案进行基准测试,因此不对它们的功效或特性进行评论。
H2O 无人驾驶 AI(全管道)
Mljar(全管道)
DataRobot(全管道)
MateLabs(全管道)
SigOpt(超参数优化)
项目地址:https://github.com/HDI-Project/ATM
Star:251
Fork:56
最新发布:处于实验阶段,需要手动安装
Auto-Tune Models 是由麻省理工学院的“人与数据交互”项目(与 featuretools 相同)开发的框架,用于快速培训机器学习模型,而且工作量很小。它使用穷举搜索和超参数优化来执行模型选择。ATM 仅支持分类问题,并支持 AWS 上的分布式计算。
项目地址:https://github.com/AxeldeRomblay/MLBox
Star:504
Fork:115
最新发布:2017 年 8 月 25 日(0.5.0)
MLBox 是一个自动化机器学习框架,其目标是为自动机器学习提供更新的途径。除了现有框架已经实现的特征工程之外,它还提供数据收集、数据清理和训练测试漂移检测。它使用 Tree Parzen Estimator 来优化所选模型类型的超参数。
项目地址:https://github.com/ClimbsRocks/auto_ml
Star:793
Fork:146
最新发布:2017 年 9 月 11 日(2.7.0)
auto_ml 是一种旨在不需要做太多工作就能从数据中获取价值的工具。这个框架使用基于进化网格搜索的方法完成特征处理和模型优化。它通过利用高度优化的库(如 XGBoost、TensorFlow、Keras、LightGBM 和 sklearn)来提高速度。最多 1 毫秒的预测时间是它的亮点。这个框架可快速洞察数据集,如特征重要性,并创建初始预测模型。
项目地址:https://github.com/automl/auto-sklearn
Star:2,271
Fork:438
最新发布:2018 年 1 月 5 日(0.3.0)
auto-sklearn 使用贝叶斯搜索来优化机器学习管道中使用的数据预处理器、特征预处理器和分类器。多个管道经过训练并整合成一个完整的模型。这个框架由弗莱堡大学的 ML4AAD 实验室开发。它的优化过程使用由同一研究实验室开发的 SMAC3 框架来完成。顾名思义,这个模型实现了 sklearn。auto-sklearn 的主要特点是一致性和稳定性。
项目地址:https://github.com/h2oai/h2o-3
Star:3,132
Fork:1,217
最新发布:2018 年 6 月 7 日(3.20.0.1)
H2O 是一个使用 Java 开发的机器学习平台,它在与机器学习库(如 sklearn)类似的抽象级别上运行。它还提供了一个自动机器学习模块,这个模块利用自身包含的算法来创建机器学习模型。该框架对内置于 H2O 系统的预处理器执行详尽搜索,并使用笛卡尔网格搜索或随机网格搜索来优化超参数。H2O 最大的优势在于它能够形成大型计算机集群,从而能够进行大规模伸缩。它还支持与 python、javascript、tableau、R 和 Flow(web UI)集成。
项目地址:https://github.com/EpistasisLab/tpot
Star:4,130
Fork:705
最新发布:2017 年 9 月 27 日(0.9)
TPOT(基于树的管道优化工具)是一种用于查找和生成最佳数据科学管道代码的遗传编程框架。TPOT 从 sklearn 中获取算法,与其他自动机器学习框架一样。TPOT 最大的优势在于其独特的优化方法,可以提供更多独特的管道。它还提供了一个将训练好的管道直接转换为代码的工具,这对于希望进一步调整生成模型的数据科学家来说是一个很大的好处。
这些框架为常见的数据科学问题提供了有价值的解决方案,它们能够显著提高数据科学团队的工作效率,这样他们就可以减少花在实现算法上的时间,并花更多的时间思考理论。
英文原文:
https://medium.com/georgian-impact-blog/automatic-machine-learning-aml-landscape-survey-f75c3ae3bbf2

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!



