【综述】多智能体强化学习算法理论研究
深度强化学习实验室
作者:刘浚嘉
编辑:DeepRL

虽然目前多智能体强化学习 MARL 在很多领域取得了不错的结果,但很少有相关的理论分析。本综述挑选并汇总了拥有理论支撑的 MARL 算法,主要是以下两种理论框架:
Markov / stochastic games 马尔可夫/随机博弈
extensive-form games 形式广泛的游戏
并关注以下三种类型的任务:
fully cooperative
fully competitive
a mix of the two
此外,本文还给出了一些MARL理论的新观点,包括 extensive-form games, decentralized MARL with networked agents, MARL in the mean-field regime, (non-)convergence of policy-based methods for learning in games, etc
1 Introduction
MARL 算法的面临以下问题
-
由于所有agent同时根据自己的利益改进其策略,每个agent所面对的环境变得 non-stationary。这打破了single agent环境中大多数理论分析的基本框架并使之无效。 -
随着agent数量的增长而呈指数增加的联合行动空间可能会导致可扩展性问题,这被称为 the combinatorial nature of MARL (Hernandez-Leal et al.,2018)。 -
The information structure (即 who knows)在MARL中也很重要,因为每个agent对他人观察的访问均受到限制,从而导致本地决策规则可能欠佳。
2 MARL Background
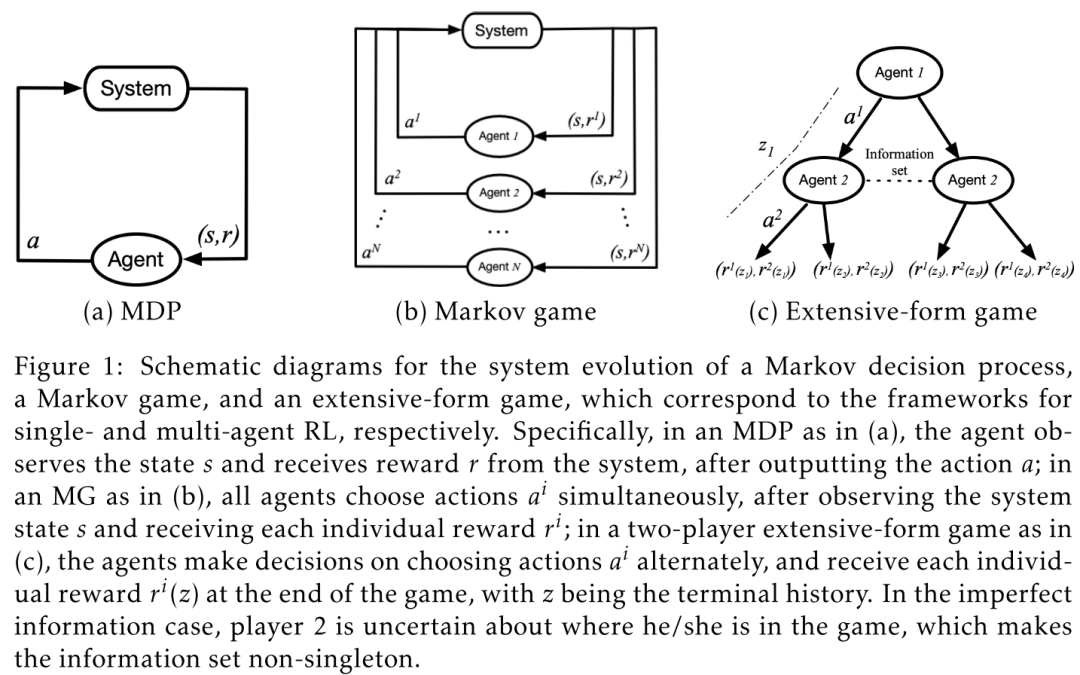
2.1 Markov/Stochastic Games
Definition 2.1. Markov Games 由五元组 






值函数 




因此,MG的解决方案不同于MDP,因为每个agent的最佳性能不仅受其自身策略的控制,而且还受博弈中所有其他玩家的选择的控制。这方面最重要的理论就是纳什均衡。
Definition 2.3. Nash equilibrium of Markov Games 是一个服从下述不等式的联合策略 


纳什均衡 描述了一个均衡策略 


Cooperative Setting
在完全合作的设定中,所有agents通常共享一个reward function,
。该模型每一个 agent 的值函数和Q函数均相同,因此可以将其看作一个决策智能体并应用single agent RL算法。显然这样做的全局合作最佳状态就能够达到博弈纳什均衡。
另一种合作模型是 team-average reward,
。平均奖励模型,它允许agent商之间存在更多的异质性。此外还可以保护agents之间的隐私,并促进 decentralized MARL 算法的发展。这种异质性必须将通信协议communication protocols整合到MARL中,并需要对通信的效率 communication-efficie MARL 进行分析。、


Competitive Setting
完全竞争的MARL一般被建模为 zero-sum Markov games 马尔可夫零和博弈 , 
Mixed Setting
混合设定一般也被称作general-sum一般和博弈,其对agents的目标和关系没有任何限制。每个agent都是自私的,他们的奖励可能与他人的利益冲突。博弈论中的均衡解决方案概念,例如Nash均衡,对为此通用设置开发的算法具有最重要的影响。
此外,还有一些研究包同时含 fully cooperative and com- petitive agents 的设置,例如,两个零和 competitive 团队,每个团队中都有 coorperative agent的情况。
2.2 Extensive-Form Games
马尔可夫博弈的问题在于:只能处理完全观察到的情况,每个智能体对整个系统的状态和动作都有很清晰的认识。将马尔可夫博弈扩展到部分可观测的情况可能是适用的,但是即使在合作环境下,这也具有挑战性。
相反,extensive-form games 框架就可以处理信息不完备的多智能体决策问题。该框架植根于计算博弈论,并已被证明可以在温和条件下允许多项式时间复杂度的算法
Definition 2.4. extensive-form games 定义为
是被称为chance or nature 的特殊 agent,它具有固定的随机策略,该策略指定环境的随机性。
是所有可能的 history,每个历史记录都是从博弈开始就采取的一系列操作。
表示在非终止历史记录
之后可用的一组动作。
在所有历史中,
是代表博弈结束的terminal histories的子集。
是 identification function,指定在每个历史记录中哪个agent采取的动作。如果
,那么 chance agent 根据它的策略
采取动作。
S中的元素称为 information states。








部分可观测反映在智能体无法区分同一信息集中的历史记录。此外,我们始终假设博弈是回忆完备的 perfect recall,即每个agent都记住 information states 和导致其当前信息状态的动作的顺序。更重要的是,根据著名的库恩定理 Kuhn’s theorem,在这样的假设下,找到纳什均衡集,就足以将推导约束为 behavioral policies 集,后者将每个信息集



agents 的联合策略由 


它指定当所有agent都遵循π时创建h的概率。类似地,我们将信息状态 s 在π 下的到达概率定义为 


Definition 2.5. 



Various Settings
Extensive-form games 一般用于建模 non-cooperative settings。更重要的是,不同信息结构的设置也可以通过extensive-form game来表征。特别是,一个信息完备的博弈是每个信息集都是一个单例的博弈,即对于任何 

Connection to Markov Games
 时agent
时agent
 设置为
设置为
 ,extensive-form game 简化为具有 state-dependent 的动作空间的马尔可夫博弈。
,extensive-form game 简化为具有 state-dependent 的动作空间的马尔可夫博弈。
3 Challenges
3.1 Non-Unique Learning Goals 目标不唯一
不同智能体间,学习的目标不唯一。被设计为收敛到NE的学习动力对于实际的MARLagent来说可能是不合理的。Instead, the goal may be focused on designing the best learning strategy for a given agent and a fixed class of the other agents in the game。
用 convergence(达到平衡点)作为MARL算法分析的主要性能标准还存在争议。因为 Zinkevich et al. (2006) 证实基于价值的MARL算法无法收敛到一般性和马尔可夫博弈的平稳NE,这激发了 cyclic equilibrium 的新解决方案概念。在该概念下,agent 通过一系列 stationary policies(即不收敛到任何NE策略)严格循环。或者,将学习目标分为 stable 和 relational 两个方面,前者在给定预定义的、有针对性的对手算法的情况下,确保算法收敛,而后者则要求在其他主体保持稳定时收敛到 best-response。如果所有agent都既稳定又理性,则在这种情况下自然会融合到NE
此外,regret 的概念为捕捉 agent 的 rationality 引入了另一个角度,与 the best hindsight static strategy 相比,它衡量了算法的性能(Bowling和Veloso,2001;Bowling,2005)。渐近平均零后悔的 No-regret algorithms 保证了某些博弈的均衡收敛性(Hart和Mas-Colell,2001;Bowling,2005;Zinkevich等,2008),这从根本上保证了该 agent 不会被其他 agent 利用。
Kasai等(2008),Foerster等(2016),Kim等(2019)研究了 learning to communicate 的方式,以便 agents 更好地进行协调。对通信协议的这种关注自然激发了最近对高通信效率的MARL的研究(Chen等,2018; Lin等,2019; Ren和Haupt,2019; Kim等,2019)。其他重要目标包括如何在不过度拟合某些 agent 的情况下进行学习(He等人,2016; Lowe等人,2017; Grover等人,2018),以及如何在恶意/对抗性或失败/功能失调的情况下稳健学习。(Gao等,2018; Li等,2019; Zhang等,2019)。
3.2 Non-Stationarity 非平稳
很明显,由于多智能体动作结果的相互影响,agent 需要考虑其他 agents 的 action 并相应地适应 joint action,导致了单智能体的马尔可夫假设不适用。
关于这方面的知识,可见 Hernandez-Leal 2017年的综述,该文章中特别概述了如何通过最新的 MARL 学习算法对其进行建模和解决。
3.3 Scalability Issue 可扩展性
为了处理非平稳性,每个 agent 都可能需要考虑联合动作空间,然而联合行动的规模会随着智能体的增加而成倍的增加。这也被称为MARL的 combinatorial nature(Hernandez-Leal et al.,2018)。
一种可能的补救措施是,另外假设关于动作依赖的价值或奖励函数的因式分解结构。
参见Guestrin(2002a,b);Kok和Vlassis(2004)提出了原始的启发式思想,以及最近的 Sunehag et al. (2018); Rashid et al. (2018) 等。直到最近才建立了相关的理论分析**(Qu and Li,2019)**,该模型考虑了一种特殊的依赖结构,并开发了一种可证明的基于模型的收敛算法(不是RL)。
3.4 Various Information Structures 不同的信息结构
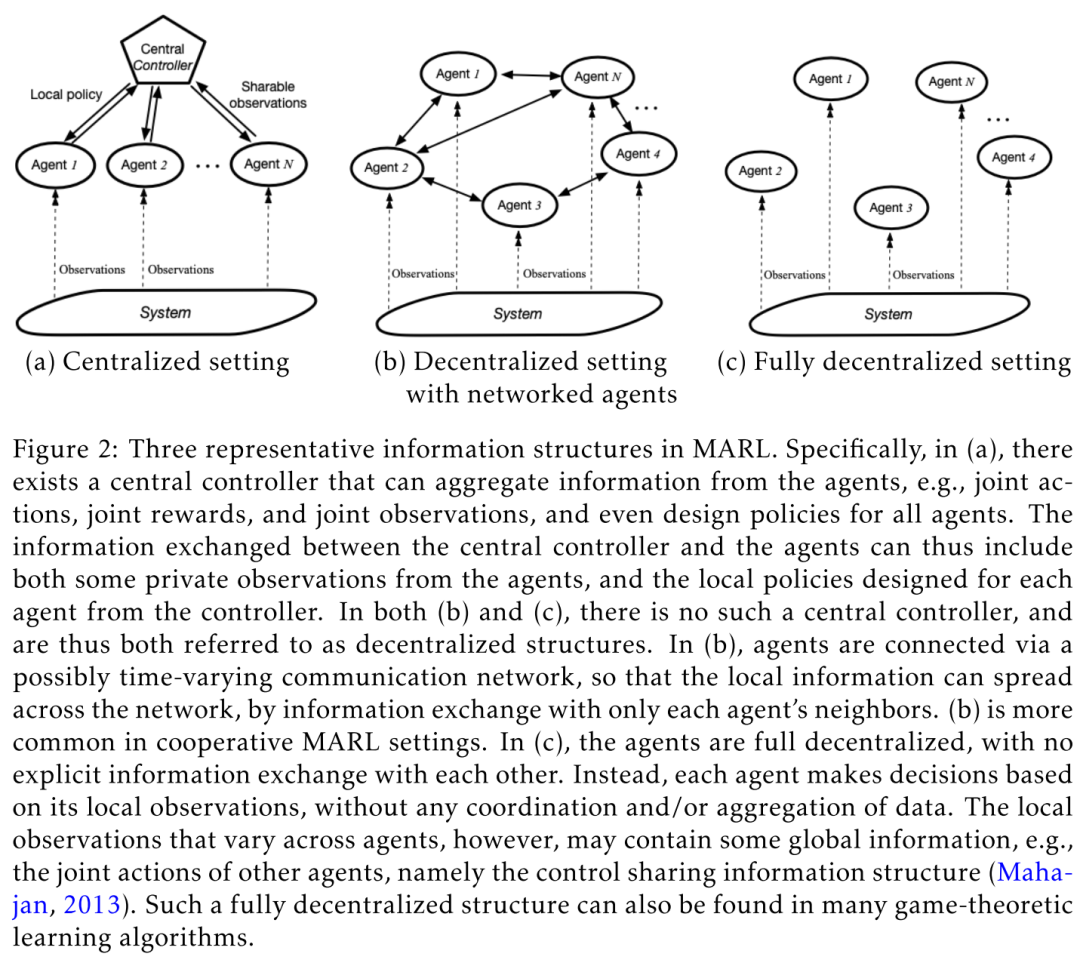
中心化 MARL:大量工作都假设存在一个 centralized controller,该中央控制器可以收集信息,例如联合动作,联合奖励和联合观察,甚至为所有agent设计策略。(Hansen et al., 2004; Oliehoek and Amato, 2014; Lowe et al., 2017; Foerster et al., 2017; Gupta et al., 2017; Foerster et al., 2018; Dibangoye and Buffet, 2018; Chen et al., 2018; Rashid et al., 2018)。这种结构催生了流行的集中学习,分散执行 centralized-learning-decentralized-execution 的学习方案,该方案源于为部分观察的环境进行规划的工作,即Dec-POMDP。然而,通常这种中央控制器在许多应用中并不存在,除了那些可以轻松访问模拟器的应用之外,例如 video games 和 robotics。
完全去中心 MARL:为了解决独立学习中的收敛问题,通常允许agents通过通信网络与邻居交换/共享本地信息。(Kar et al., 2013; Macua et al., 2015, 2017; Zhang et al., 2018,a,b; Lee et al., 2018; Wai et al., 2018; Doan et al., 2019; Suttle et al., 2019; Doan et al., 2019; Lin et al., 2019)。我们将此设置称为 a decentralized one with networked agents。这样一来,就可以在这种情况下进行收敛的理论分析,其难度介于 SARL 和通用MARL算法之间。
4 MARL Algorithms with Theory
本文仅聚焦 Cooperative Setting 的情况下的详细理论,如果想了解 Competitive Setting 和 Mixed Setting,可以自行阅读标题下的链接。由于 Homogeneous Cooperative Agent 的情况过于 naive,本文就不提了,我比较感兴趣的是Decentralized Paradigm with Networked Agents,这也是最符合实际的模型。
Decentralized Paradigm with Networked Agents
在许多实际的multi-agent系统中,coorperative agents 并不总是同质的。
Agents可能有不同的偏好,即奖励函数,这时要让团队的平均回报 
这种设定常出现于诸如传感器网络(Rabbat和Nowak,2004),智能电网(Dall'Anese等,2013;Zhang等,2018a),智能交通系统(Adler和Blue,2002)和机器人技术(Corke等人,2005)等场景。
如果使用 central controller 的方式,上述大多数MARL算法都可直接适用,因为 central controller 可以收集平均奖励,并将信息分发给所有 agents。但是由于成本、可扩展性或健壮性方面的考虑,在大多数上述应用中可能都不存在这种控制器(Rabbat和Nowak,2004;Dall’Anese等,2013;Zhang等,2019)。
取而代之的是,agents 可以通过随时间变化且稀疏的通信网络与邻居共享/交换信息。
Learning Optimal Policy
如何仅通过网络访问本地和邻近信息来达到最优的联合策略。具有网络 agents 的MARL 想法可以追溯到Varshavskaya et al.(2009)。第一个可证明收敛的MARL算法是Kar等人提出的(2013),将 consensus + innovation 的思想纳入标准的Q学习算法,产生了具有以下更新的 QD-learning 算法

其中:
are stepsizes
代表 t 时刻 agent i 的邻居集


Q-learning 相比,QD-learning 在步长上增加了 innovation 项,该项捕捉了来自其邻居的Q估计值的差异。With certian conditions on the stepsizes, 算法可以保证收敛到表格形式下的最优 Q 函数。
对于 policy-based 方法可见这篇文章 Fully decentralized multi-agent reinforcement learning with networked agents,它提出了完全去中心化的 multi-agent actor-critic。每个 agent 通过某个参数 







is the stepsize
是用
计算出的局部 TD-error
第一个等式给出了标准的 TD update,第二个是邻居的加权组合
权重
由通信网络的拓扑结构决定



请注意,上述收敛保证都是渐近的,即算法随着迭代次数达到无穷大而收敛,并且仅限于线性函数近似的情况。当使用有限迭代和/或样本时,这无法量化性能,更不用说在利用诸如 DNN 之类的非线性函数时了。
当考虑更通用的函数逼近进行有限样本分析时,详见 Finite-sample analyses for fully decentralized multi-agent reinforcement learning 和 Batch reinforcement learning 的 batch RL 算法,特别是 the fitted-Q iteration (FQI) 的去中心化变体。
我们研究了FQI变体,既用于与网络代理的协作环境,也用于与两个团队的网络代理的竞争环境。在前一种设定中,所有智能体都通过将非线性最小二乘法与目标值拟合来迭代更新全局Q函数估计。
让 




由于 
另一个问题:由于是对分布式系统进行有限次迭代,agents之间可能无法达成共识,导致了对最优 Q 值的估计偏离了实际值。我们可以根据源于 single-agent batch RL 的 error propagation 分析,建立所提出算法的有限样本下的性能评估。例如,算法输出的精度多大程度取决于函数
5 Conclusions and Future Directions
Partially observed settings
在许多实际的MARL应用程序中,系统状态和其他agent的行为的部分可观察性是典型且不可避免的。通常,可以将这些设置建模为 partially observed stochastic game (POSG),在特殊情况下,该游戏包括具有 common reward function 的协作设定,即Dec-POMDP模型。然而,即使合作任务也是 NEXP-hard(Bernstein等,2002),难以解决。
实际上,与只需要相信状态的POMDPs相比,POSG中用于最佳决策的信息状态可能会非常复杂,并且涉及 belief generation over the opponents’ policies(Hansen等人,2004年)。
这种困难主要源于从模型中获得的自身观察结果所导致的agent异质性,这是第3节中提到的MARL固有的挑战,原因是信息结构多种多样。有可能首先将解决Dec-POMDP的 centralized-learning-decentralized-execution 方案(Amato和Oliehoek,2015; Dibangoye和Buffet,2018)推广到解决POSGs。
Deep MARL theory
使用DNN进行函数逼近可以解决MARL中的可伸缩性问题。实际上,最近在MARL中获得的大部分经验成功都来自DNN的使用(Heinrich和Silver,2016; Lowe等人,2017; Foerster等人,2017; Gupta等人,2017; Omidshafiei等人,2017)。但是,由于缺乏理论支持,我们在本章中没有包括这些算法的详细信息。最近,人们做出了一些尝试来理解几种 single agent DRL 算法的全局收敛性,例如 neural TD learning(Cai等,2019)和 neural policy optimization(Wang等,2019; Liu等2019年)。因此,有望将这些结果扩展到多智能体设定,作为迈向对DMARL的理论理解的第一步。
Model-based MARL
文献中很少有基于模型的MARL算法。据我们所知,目前仅有的基于模型的MARL算法包括Brafman和Tennenholtz(2000)中的早期算法,它解决了单控制器随机游戏,一种特殊的 zero-sum MG。后来在Brafman和Tennenholtz(2002)中对zero-sum MG进行了改进,名为R-MAX。这些算法也建立在面对不确定性时的 principle of optimism 上(Auer和Ortner,2007;Jaksch等,2010),就像前面提到的几种无模型的算法一样。考虑到基于模型的RL的最新进展,尤其是在某些情况下其优于无模型的RL的可证明优势(Tu and Recht,2018; Sun等,2019),有必要将这些结果推广到MARL以改进其 sample efficiency。
Convergence of policy gradient methods
一般MARL中的 vanilla PG 的收敛结果大部分为负,即在许多情况下甚至会避开本地NE点,这本质上与MARL中的非平稳性挑战有关。尽管已经提出了一些补救措施(Balduzzi等人,2018; Letcher等人,2019; Chasnov等人,2019; Fiez等人,2019)来稳定 general continuous games 的收敛性,但这些假设是即使在最简单的LQ设置中,也不容易在MARL中进行验证/满足(Mazumdar等人,2019),因为它们不仅取决于模型,而且还取决于策略参数化。由于这种微妙之处,探索基于策略的MARL方法的(全局)收敛可能很有趣,可能始于简单的LQ设置(即一般和LQ游戏),类似于 zero-sum counterpart 博弈。
MARL with robustness/safety concerns
考虑到多智能体会有不唯一的学习目标,我们认为在MARL中考虑稳健性和/或安全性约束是很有意义的。据我们所知,这仍然是一个相对未知的领域。实际上,safe RL已被认为是 single agent 中最重大的挑战之一(Garcia和Fernandez,2015)。由于可能存在多个目标冲突的代理,因此安全性变得更加重要,安全要求让我们必须考虑智能体间的的耦合。一种简单的模型是 constrained multi-agent MDPs/Markov games,其约束条件表征了安全性要求。在这种情况下,具有可证明的安全保证的学习并非易事,但对于一些对安全性至关重要的MARL应用(如自动驾驶(Shalev-Shwartz等,2016)和机器人技术(Kober等,2013))是必需的。
此外,当然也要考虑对抗对手的鲁棒性,特别是在分散/分布式合作MARL环境中,如Zhang等人所述 Zhang et al. (2018); Chen et al. (2018); Wai et al. (2018)。在这种情况下,对手可能以匿名方式干扰学习过程-这是分布式系统中的常见情况。在这种情况下,针对 Byzantine adversaries 的鲁棒分布式监督学习的最新发展 (Chen et al., 2017; Yin et al., 2018) 可能是有用的。
知乎地址:https://zhuanlan.zhihu.com/p/220581474
完
总结3: 《强化学习导论》代码/习题答案大全
总结6: 万字总结 || 强化学习之路
完
第80篇:强化学习《奖励函数设计》详细解读
第79篇: 诺亚方舟开源高性能强化学习库“刑天”
第77篇:深度强化学习工程师/研究员面试指南
第75篇:Distributional Soft Actor-Critic算法
第74篇:【中文公益公开课】RLChina2020
第73篇:Tensorflow2.0实现29种深度强化学习算法
第72篇:【万字长文】解决强化学习"稀疏奖励"
第71篇:【公开课】高级强化学习专题
第70篇:DeepMind发布"离线强化学习基准“
第66篇:分布式强化学习框架Acme,并行性加强
第65篇:DQN系列(3): 优先级经验回放(PER)
第64篇:UC Berkeley开源RAD来改进强化学习算法
第61篇:David Sliver 亲自讲解AlphaGo、Zero
第59篇:Agent57在所有经典Atari 游戏中吊打人类
第58篇:清华开源「天授」强化学习平台
第57篇:Google发布"强化学习"框架"SEED RL"
第53篇:TRPO/PPO提出者John Schulman谈科研
第52篇:《强化学习》可复现性和稳健性,如何解决?
第51篇:强化学习和最优控制的《十个关键点》
第50篇:微软全球深度强化学习开源项目开放申请
第49篇:DeepMind发布强化学习库 RLax
第48篇:AlphaStar过程详解笔记
第47篇:Exploration-Exploitation难题解决方法
第45篇:DQN系列(1): Double Q-learning
第44篇:科研界最全工具汇总
第42篇:深度强化学习入门到精通资料综述
第41篇:顶会征稿 || ICAPS2020: DeepRL
第40篇:实习生招聘 || 华为诺亚方舟实验室
第39篇:滴滴实习生|| 深度强化学习方向
第37篇:Call For Papers# IJCNN2020-DeepRL
第36篇:复现"深度强化学习"论文的经验之谈
第35篇:α-Rank算法之DeepMind及Huawei改进
第34篇:从Paper到Coding, DRL挑战34类游戏
第31篇:强化学习,路在何方?
第30篇:强化学习的三种范例
第29篇:框架ES-MAML:进化策略的元学习方法
第28篇:138页“策略优化”PPT--Pieter Abbeel
第27篇:迁移学习在强化学习中的应用及最新进展
第26篇:深入理解Hindsight Experience Replay
第25篇:10项【深度强化学习】赛事汇总
第24篇:DRL实验中到底需要多少个随机种子?
第23篇:142页"ICML会议"强化学习笔记
第22篇:通过深度强化学习实现通用量子控制
第21篇:《深度强化学习》面试题汇总
第20篇:《深度强化学习》招聘汇总(13家企业)
第19篇:解决反馈稀疏问题之HER原理与代码实现
第17篇:AI Paper | 几个实用工具推荐
第16篇:AI领域:如何做优秀研究并写高水平论文?
第14期论文: 2020-02-10(8篇)
第13期论文:2020-1-21(共7篇)
第12期论文:2020-1-10(Pieter Abbeel一篇,共6篇)
第11期论文:2019-12-19(3篇,一篇OpennAI)
第10期论文:2019-12-13(8篇)
第9期论文:2019-12-3(3篇)
第8期论文:2019-11-18(5篇)
第7期论文:2019-11-15(6篇)
第6期论文:2019-11-08(2篇)
第5期论文:2019-11-07(5篇,一篇DeepMind发表)
第4期论文:2019-11-05(4篇)
第3期论文:2019-11-04(6篇)
第2期论文:2019-11-03(3篇)
第1期论文:2019-11-02(5篇)




