模块化、反事实推理、特征分离,「因果表示学习」的最新研究都在讲什么?
机器之心分析师网络
本文精选了 几篇因果表示学习领域的最新文献, 并细致分析了不同方法的基本架构,希望能帮助感兴趣的你对因果学习应用于机器学习的方向和可能一探究竟。


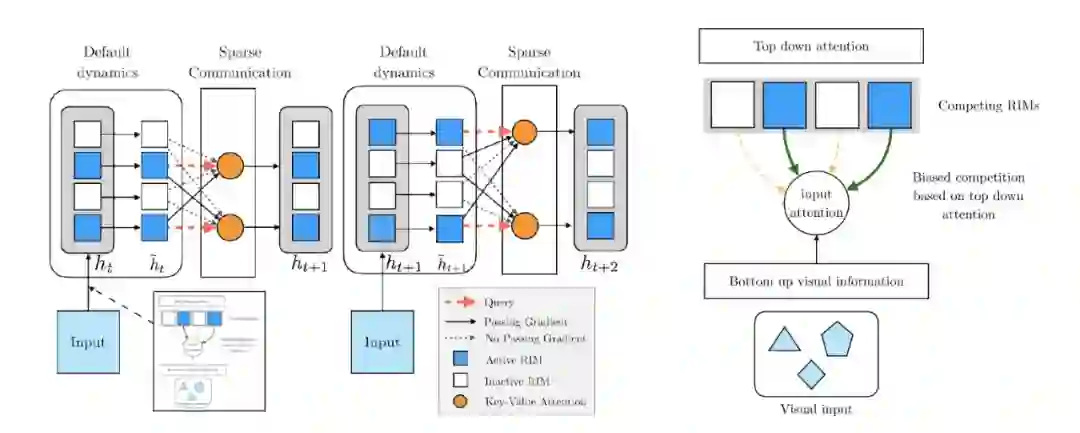
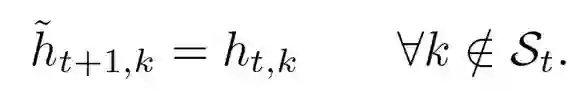
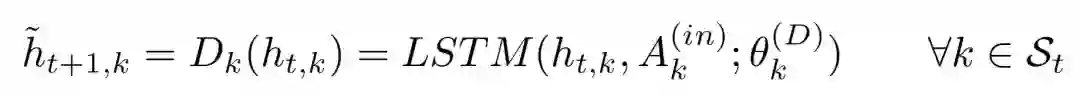
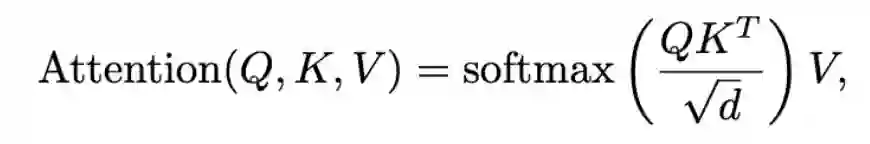
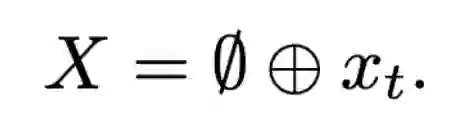
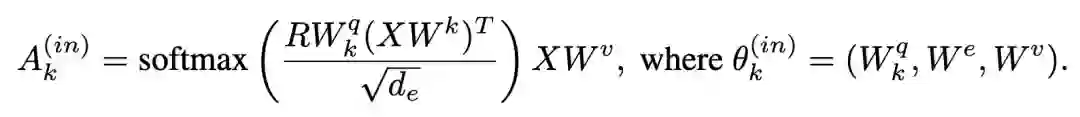
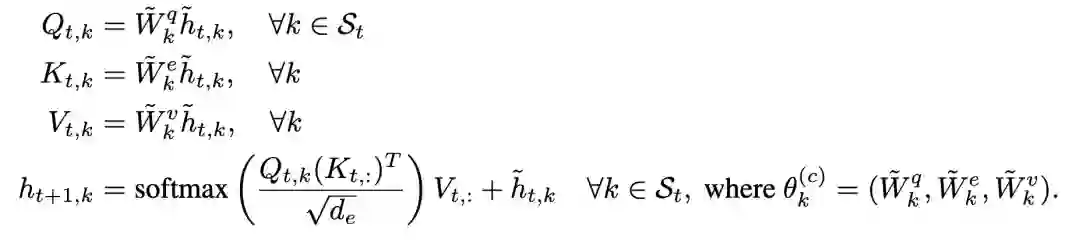
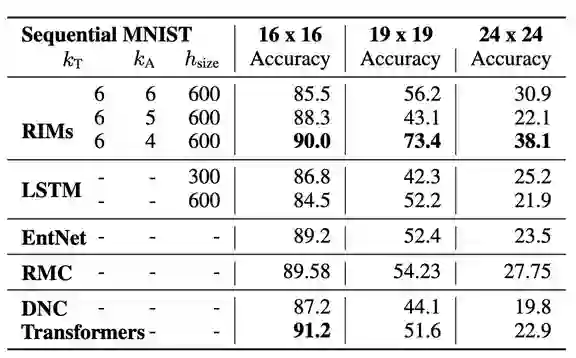


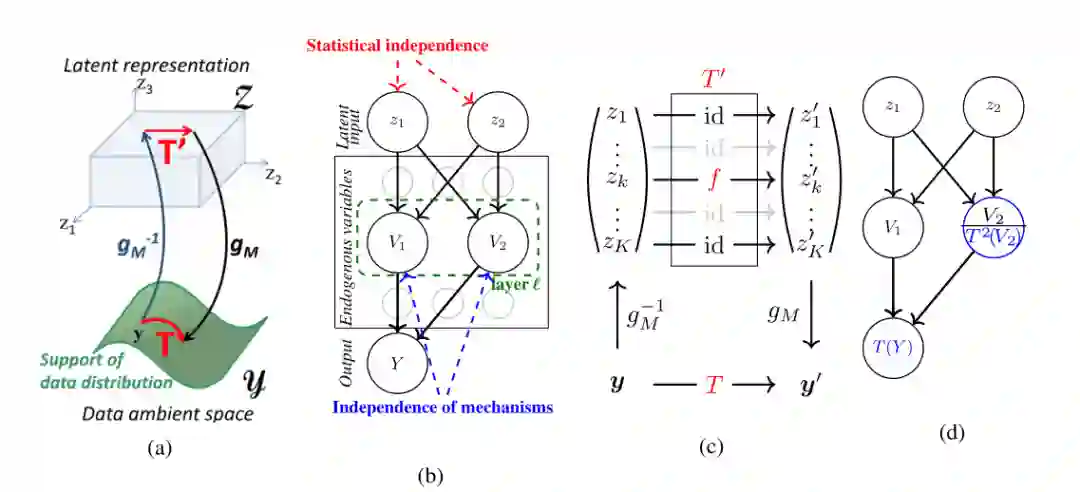
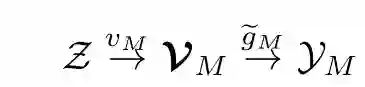
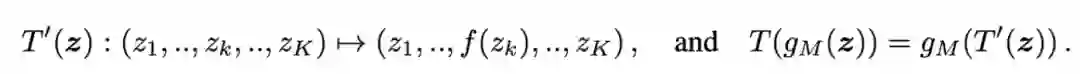
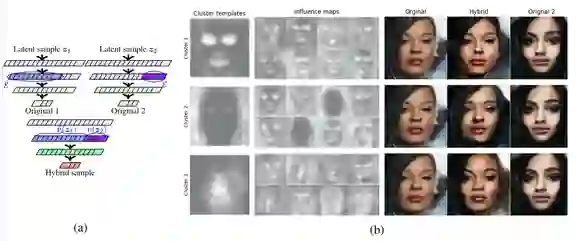
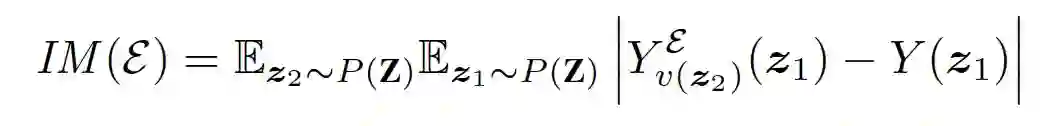



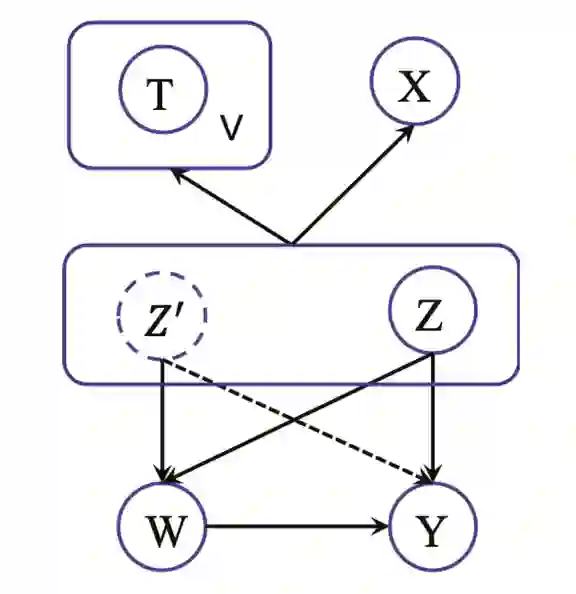
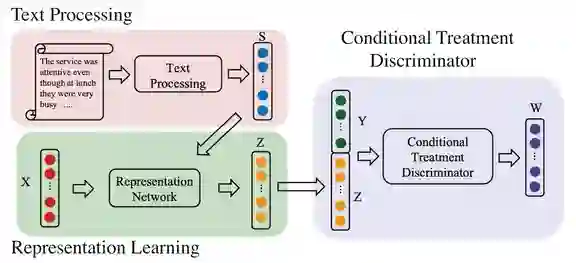
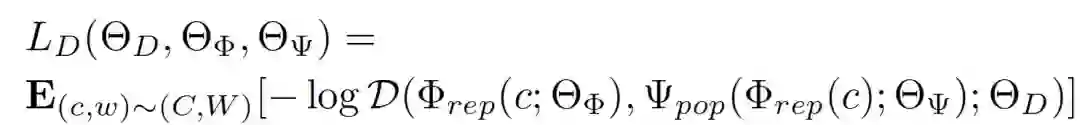
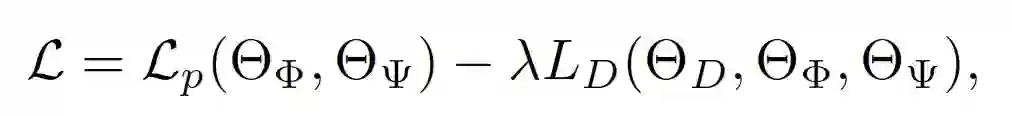
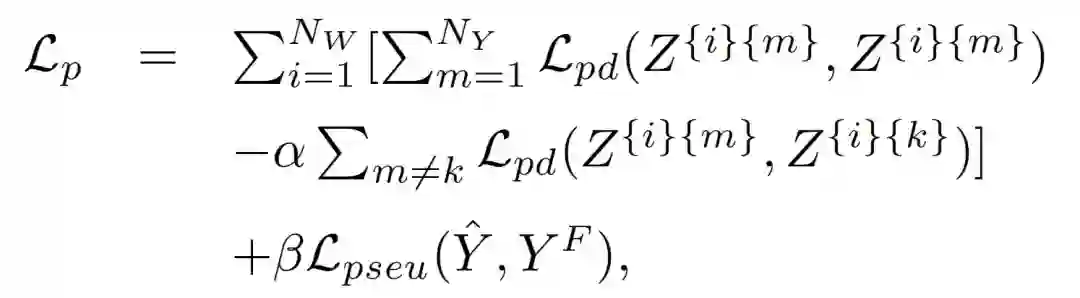
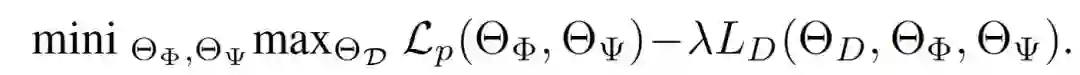
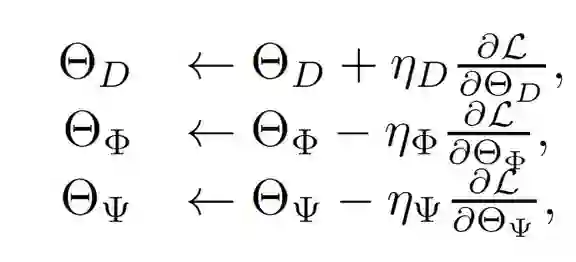
登录查看更多
相关内容
专知会员服务
13+阅读 · 2020年4月16日
专知会员服务
48+阅读 · 2019年12月13日
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
4+阅读 · 2018年5月8日
Arxiv
5+阅读 · 2018年2月22日


相关VIP内容
专知会员服务
13+阅读 · 2020年4月16日
专知会员服务
48+阅读 · 2019年12月13日
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
4+阅读 · 2018年5月8日
Arxiv
5+阅读 · 2018年2月22日