隐藏着的因果关系,如何让相同的机器学习模型变得不同
选自inference.vc
作者:Ferenc Huszár
机器之心编译
参与:李诗萌、刘晓坤
本文是 Ferenc Huszár 关于因果推理系列的第二篇文章,他在第一篇中阐述了监督学习和因果推理如何在因果图的框架下统一。在本文中,作者将通过几个简单的案例对比,展示当存在变量干预时,相同的联合分布如何受到因果关系的影响而出现截然不同的行为。
在这篇文章中,我将介绍在南非斯泰伦博斯大学的机器学习夏季学院讲课中,用来解释因果干预的几个简单的例子。我将其称之为三个脚本的 toy example。
三个脚本
假设你在教授编程课程,你让学生写一个 Python 脚本,这个脚本是要从均值和方差都确定的 2D 高斯分布中采样。因为从高斯分布中抽样的方法有很多种,可能会出现非常不同的方法。例如,下面是三个可以实现相同的、正确的采样行为的脚本:
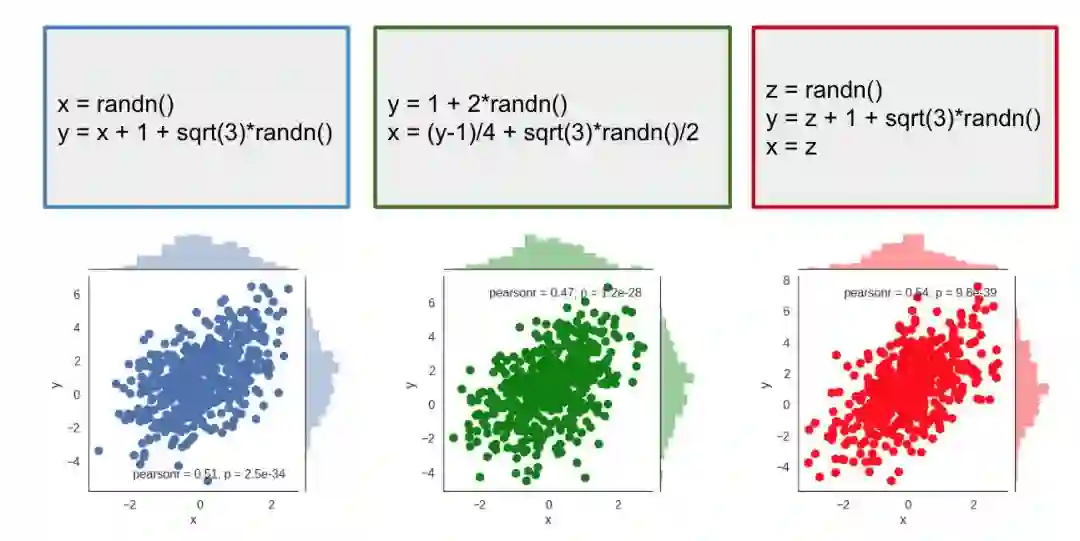
我通过反复执行这些脚本绘制了样本点。如你所见,这三个脚本在 x - y 坐标图上生成了相同的联合分布。你可以将这些分布馈送到 two-sample test 中,然后你就会发现它们确实很难区分。
根据联合分布,这三个脚本是不可区分的。
干预
尽管这三个脚本产生了相同的分布,但却不尽相同。例如,当我们干预时,它们的行为会有所差异。
做个思想实验:我是一个黑客,可以在 Python 解释器中添加代码。对这些代码片段的每一行来说,我都可以插入一行我自己选择的代码。假设我在每一行代码后都插入了一行 x=3,然后实际执行的代码是这样的:

我们现在可以在被黑的解释器中运行脚本,并观察干预是如何改变 x 和 y 的分布的:
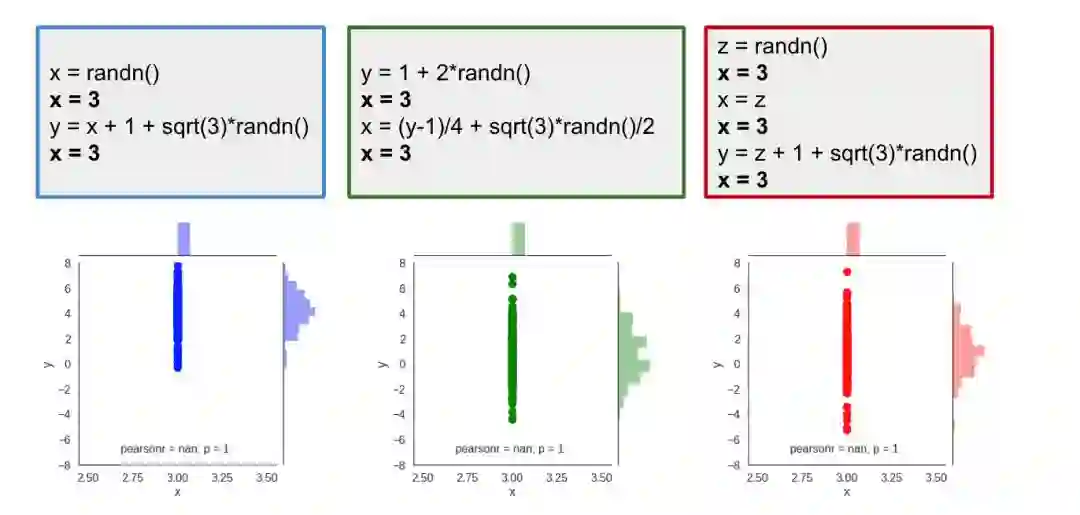
当然,我们可以看到,x 的值不再是随机的了,它被设置为 3,这就导致所有的样本都是沿着 x=3 的垂线排列的。但有趣的是,在不同的脚本中,y 的分布是不同的。在蓝色的脚本中,y 的均值在 5 左右,而绿色和红色的脚本中 y 的分布是以 1 为中心的。下图可以更好地观察到干预行为下的 y 的边缘分布。
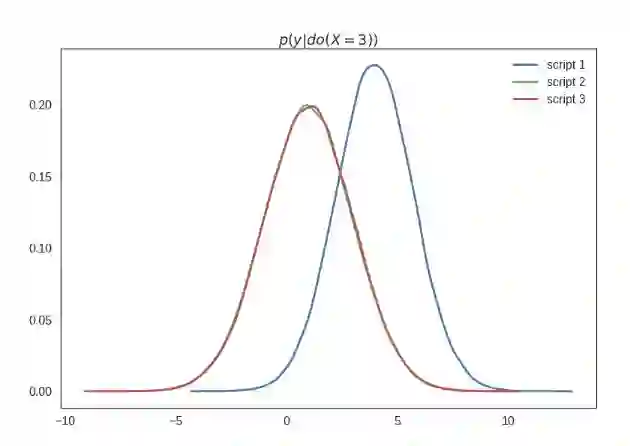
我将这个图标记为 p(y|do(X=3)),从语义上讲这是指在将 x 的值设置为 3 的干预下的 y 的分布。一般这和条件分布 p(y|x=3) 是不同的,当然这三个脚本都是一样的。下面我将展示这些条件——请原谅这里的估计误差比较多,因为我真的懒得做这些图了,但请相信我从技术上来讲它们都是相同的:
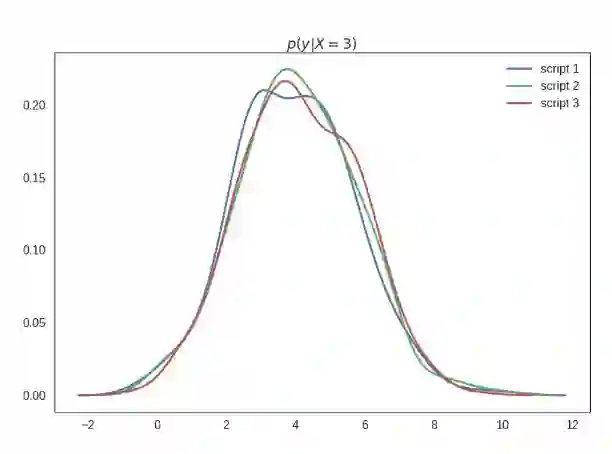
这里的重点是:脚本在干预下会产生不同的行为。
你只查看脚本产生的样本的联合分布时,是很难区分脚本的,但在干预下,它们的表现会有所差异。
因此,只有数据的联合分布不足以预测干预下的行为。
因果图
如果联合分布不够充分,那什么级别的描述才能让我们预测脚本在干预下的行为呢?如果我有完整的源代码,我当然可以执行修改后的脚本(即运行实验)并直接观察它对分布的影响。
但事实证明,你不需要完整的源代码。只要知道源代码对应的因果图就够了。因果图编码了变量间的因果关系,箭头从原因指向结果。这里有上述脚本的因果图:
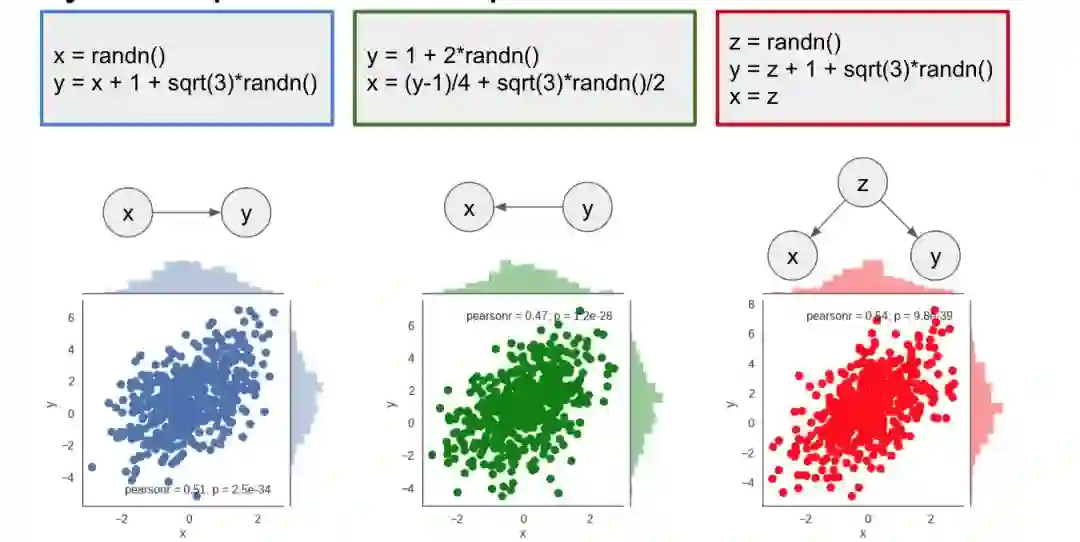
我们可以看到,即便它们产生了相同的联合分布,但脚本的因果图不同。因果结构这一附加知识使我们可以在不进行实验的情况下推断干预。为了在一般情况下做到这一点,我们可以用 do-calculus,在我之前的文章中有更详细的解释。
用图来说,为了模拟干预的影响,你要先删除指向被干预变量的所有边,对图进行变换,在本例中这个变量是 x。
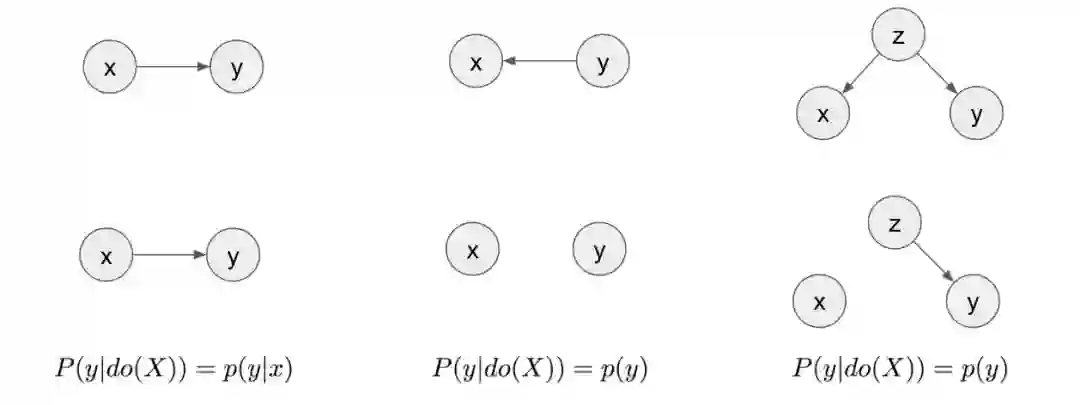
第一行的三个图描述了这三个脚本。第二行是变换后的图,在这些图中删除了所有指向 x 的边。在第一个脚本中,图在变换前后看起来是一样的。从这一点看,我们可以总结出 p(y|do(x))=p(y|x),也就是说在 x=3 时的 y 的分布和在 x=3 时的 y 的条件分布是一样的。在第二个脚本中,在变换后 x 和 y 中不再有任何连接,因此它们是相互独立的。从这一点看,我们可以总结出 p(y|do(X=3))=p(y)。改变 x 的值对 y 的值不会产生影响,所以无论你将 x 设置为多少,y 都只是从它的边际分布中抽样得到的。这一点也适用于第三张因果图。
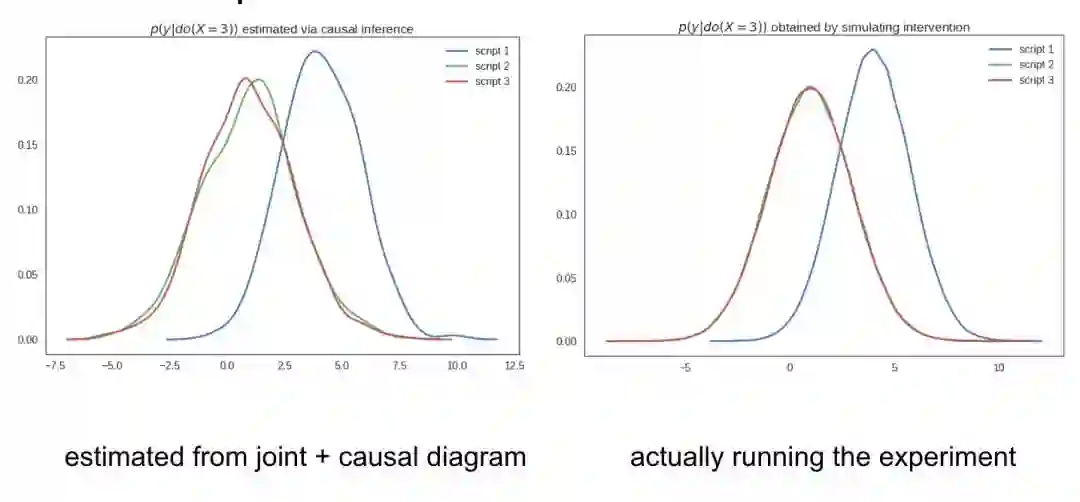
它的意义在于:只通过查看因果图,我们就可以预测脚本在 x=3 的干预下的行为。我们可以在正常(无干预)条件下用观察数据来计算并绘制出这三个脚本的 p(y|do(X=3)),而不需要进行实验或模拟干预。
因果图允许我们在没有任何干预的情况下预测模型在干预下的行为。
这证明可以在正常情况(无介入行为)下只用从脚本中获得的样本估计干预试验下 y 的观测值的分布。这就是所谓的观测数据的因果推断。
简言之,干预因可以改变果,干预果不能改变因,就像在函数中我们也需要区分自变量和因变量。
文章主旨
本文主旨总结在下面的图片中:
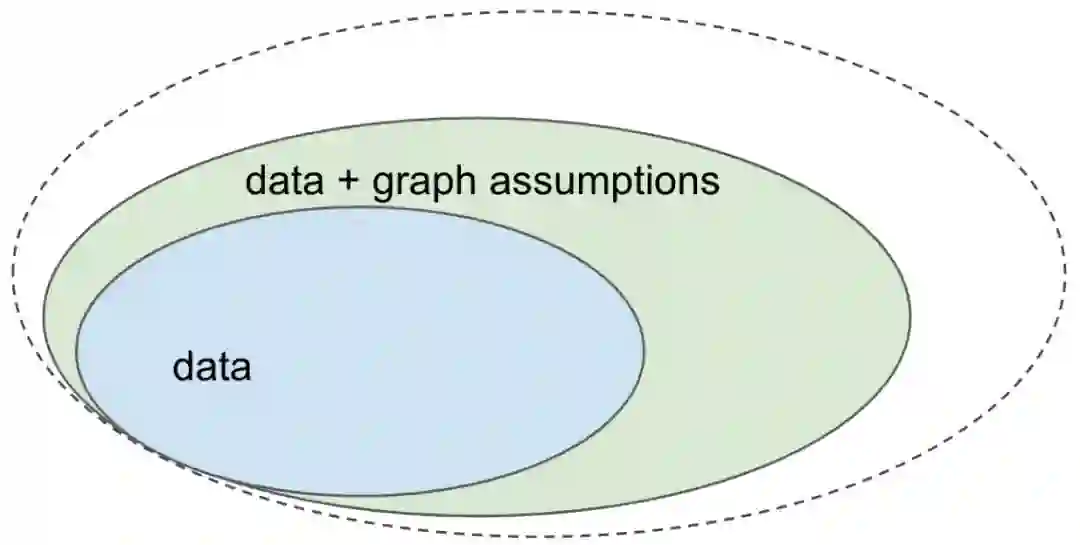
让我们考虑一下在给定数据(来自联合分布的独立同分布样本)的情况下求解机器学习问题的场景。只要从联合分布中抽样,就可以求解很多机器学习问题。例如,你可以通过逼近 p(y|x) 做有监督的机器学习,然后用它来执行图像分类、语音识别等任务。这些问题共同组成了蓝色集合。
但是,我们知道有些问题不是只用数据或联合分布就能解决的。值得注意的是,你通常无法根据现有数据预测出系统在某些干预下会做出什么样的行为。这类问题不在蓝色集合之内。
但是,如果你用因果图(有向无环图,图中的节点代表变量)中编码的因果假设来补充数据,那么你就可以利用这些额外的假设来回答这些问题,如绿色集合所示。
我还展示了更大的问题集合,但我在此不对它们进行叙述,将它们留在日后的帖子中。
(因果)图来自哪里
我最常被问到的问题是:如果我不知道图是什么样的怎么办?如果我得到的图是错误的怎么办?解决方法有很多。
必须要接受你的分析是基于所选择的图的,你的结论在编码的假设下才是有效的。从某种程度上讲,从观测数据得到的因果推断是主观的。当你公开结果时,你必须要警告「在这些假设下,这个结果是成立的」。如果读者不同意你的假设,他们可以对此提出质疑。
至于如何获得图,根据应用的不同而不同。如果你用推荐系统这样的在线系统,就很容易画出因果图,因为它和子系统的连接以及数据馈送通路都是相对应的。在其他应用中,特别是在医疗健康领域,可能涉及到更多考虑。
最后,你可以用不同的发现因果关系的技术来尝试从数据本身识别因果图。理论上讲,一般情况下是无法通过数据恢复完整的因果图的。但是如果你添加了一些额外的平滑度或独立性假设,就能够以一定的可靠性从数据中恢复图。
总结
我们已经看到,联合分布建模的作用存在局限。如果你想预测干预的效果,也就是说计算类似于 p(y|do(x)) 的量,你就要在分析中加入因果图。
乐观的态度是,在独立同分布的环境中,画因果图并使用 do-calculus(或类似的方法)都可以显著拓宽机器学习可以解决的问题的边界。
但从悲观的角度看,如果你不了解这些,可能会一直集中于仅解决绿色区域的问题。但仅靠数据是无法为你提供这些问题的答案的。
无论如何,从观察数据进行因果推断都是一个值得注意的重要话题。

原文链接:https://www.inference.vc/causal-inference-2-illustrating-interventions-in-a-toy-example/
本文为机器之心编译,转载请联系原作者获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com


