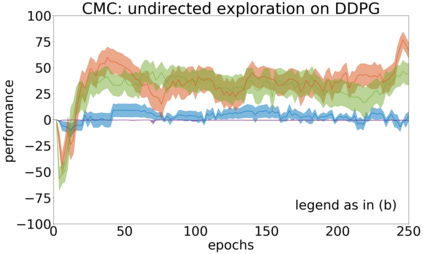
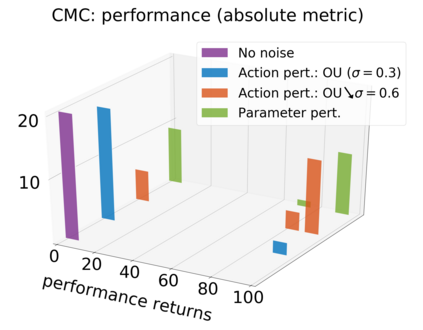
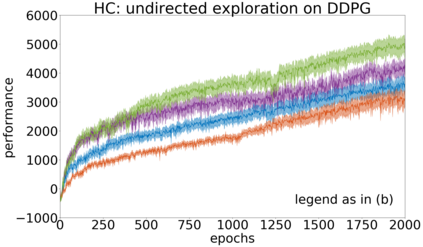
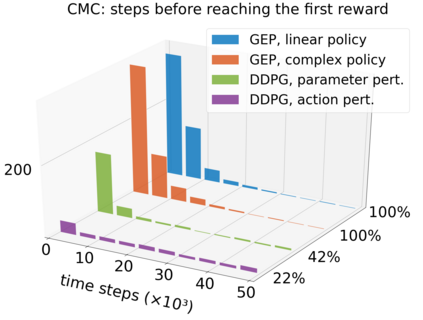
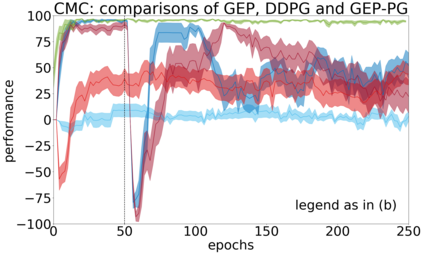
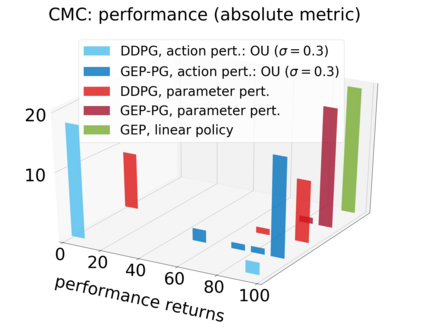
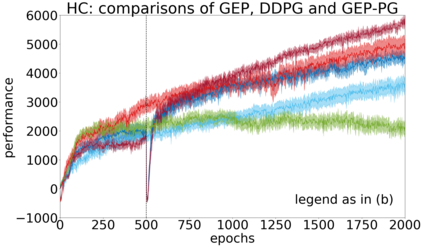
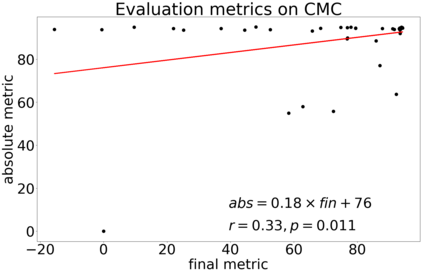
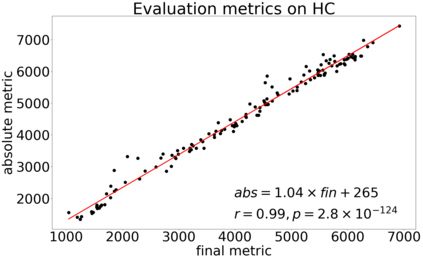
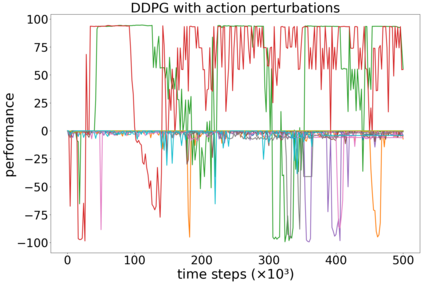
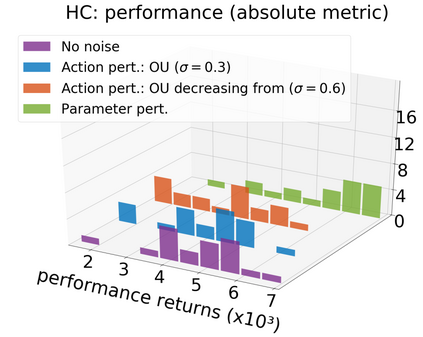
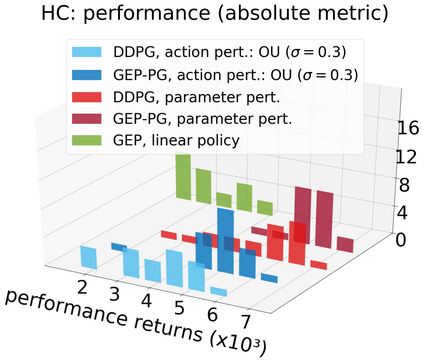
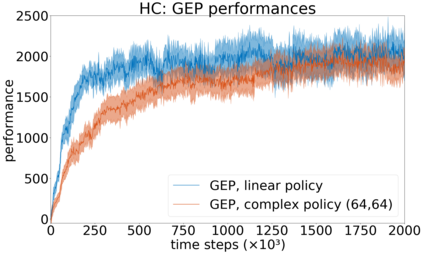
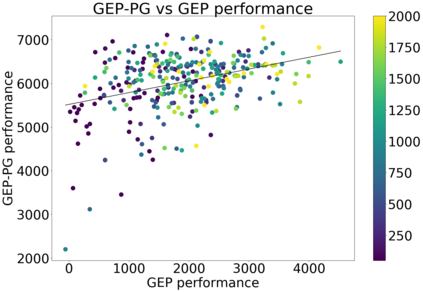
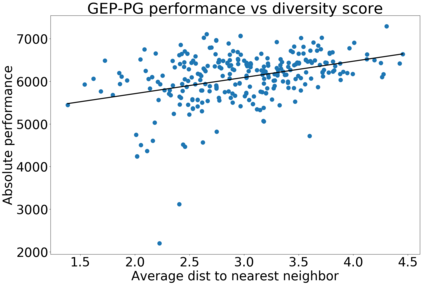
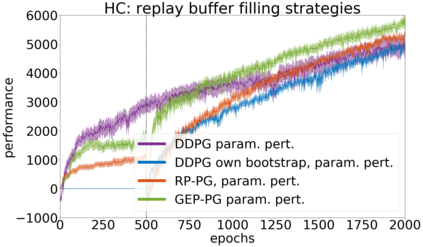
In continuous action domains, standard deep reinforcement learning algorithms like DDPG suffer from inefficient exploration when facing sparse or deceptive reward problems. Conversely, evolutionary and developmental methods focusing on exploration like Novelty Search, Quality-Diversity or Goal Exploration Processes explore more robustly but are less efficient at fine-tuning policies using gradient descent. In this paper, we present the GEP-PG approach, taking the best of both worlds by sequentially combining a Goal Exploration Process and two variants of DDPG. We study the learning performance of these components and their combination on a low dimensional deceptive reward problem and on the larger Half-Cheetah benchmark. We show that DDPG fails on the former and that GEP-PG improves over the best DDPG variant in both environments. Supplementary videos and discussion can be found at http://frama.link/gep_pg, the code at http://github.com/flowersteam/geppg.
翻译:在连续的行动领域,像DDPG这样的标准的深层强化学习算法在面临稀少或欺骗性的奖励问题时受到效率低下的探索。相反,侧重于新发现搜索、质量多样性或目标探索过程等探索的进化和开发方法更强有力地探索,但在使用梯度下降的微调政策方面效率较低。在本文中,我们介绍了GEP-PG方法,将目标探索进程与DDPG的两个变体相接轨,从而在两个世界中取得最佳效果。我们研究了这些组成部分的学习表现及其在低维度欺骗性奖励问题和较大的半切塔基准上的结合。我们表明,DDPG在前者上失败,GEP-PG在两种环境中都比最佳DDPG变体改进了。补充视频和讨论见http://frama.link/gep_pg,代码见http://githhub.com/flowsteam/geppg。