
论文题目:KAG: Boosting LLMs in Professional Domains via Knowledge Augmented Generation
本文作者:Lei Liang, Zhongpu Bo, Zhengke Gui, Zhongshu Zhu, Ling Zhong, Peilong Zhao, Mengshu Sun, Zhiqiang Zhang, Jun Zhou, Wenguang Chen, Wen Zhang, Huajun Chen
发表会议:WWW 2025
论文链接:https://dl.acm.org/doi/abs/10.1145/3701716.3715240
代码链接:https://github.com/OpenSPG/kag
欢迎转载,转载请注明出处****

一、动机
传统的 RAG 方法依赖基于相似性和共现的检索与生成方式,这种方式在处理法律、医学等需要复杂逻辑推理的专业领域任务时存在明显不足。人类通常依靠语义类型和关键词之间的清晰关系进行推理,而不是仅仅依赖相似性。KAG 正是为了解决这一问题而提出的,旨在更精准地表达知识,并提升专业领域问答系统的准确性。 二、方法
KAG 的核心理念是:**将知识图谱的结构化语义能力与大语言模型的自然语言处理优势深度融合 **,实现从“模糊匹配”到“精准推理”的跃迁。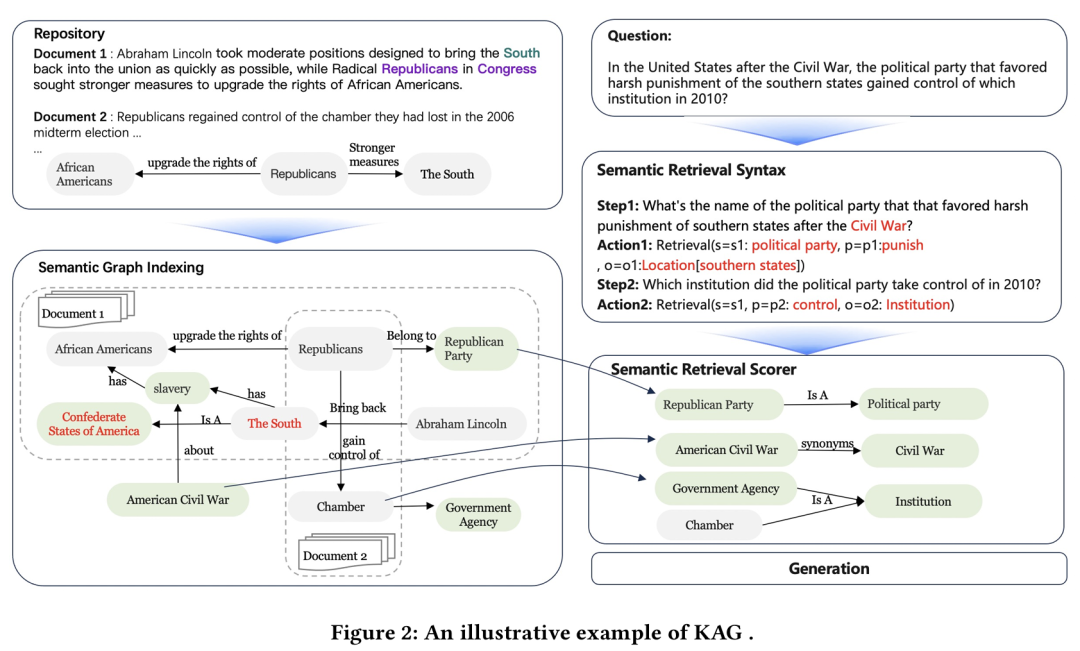
- 本体标注(Ontology Labeling):为每个实体打上类型标签,如“张三”→“Person”,“养老保险”→“SocialSecurity”。
- 上位词生成(Hyper-concept Generation):建立概念层级,例如“视觉障碍者” → “残疾人” → “特殊群体”。
- 同义词连接(Synonym Connection):打通表述差异,如“医保”=“医疗保险”。
- 常识关系注入(Concept Connection):引入通用常识,如
(战争, 导致, 伤亡)、(政府官员, 隶属, 政党)。
最终形成的语义图不仅包含原始文档中的显性知识,还补全了大量隐含的逻辑路径,极大增强了跨文档推理能力。 🧠 小贴士:该过程采用稀疏符号索引(知识图谱)与稠密向量索引(嵌入)相结合的混合索引策略,兼顾精确性与召回率。 ✅ 2. 语义解析与推理(Semantic Parsing & Reasoning) 面对复杂问题,KAG不会直接丢给LLM去“猜”,而是先将其拆解为一系列具有明确语义结构的逻辑形式(Logical Form, LF)。 以这个问题为例: ❓ “格林伍德实验学校所在城市何时成为《可怜的傻瓜》编剧出生州的首府?” KAG会自动将其分解为四步推理链:步骤子问题逻辑形式(LF)1谁是《可怜的傻瓜》的编剧?get_spo(s=电影[《可怜的傻瓜》], p=编剧, o=人物)2该编剧出生于哪个州?get_spo(s=人物, p=出生地, o=州)3格林伍德实验学校位于哪座城市?get_spo(s=学校[格林伍德实验学校], p=位于, o=城市)4该城市何时成为上述州的首府?get_spo(s=城市, p=成为首府时间, o=州) 每一个LF都是一个结构化查询指令,带有清晰的主语类型、谓词、宾语类型等语义信息。这种形式更易于与知识图谱对接,支持多跳、可追溯、可解释的推理过程。 此外,KAG还内置任务控制模块,管理子问题状态、历史记忆与执行终止条件,确保整个推理流程有序进行。 ✅ 3. 语义检索(Semantic Retrieval) 传统的基于向量相似度的检索,在面对“间接关联”的问题时容易失效。比如用户问“视障人士出行需要什么工具?”,如果知识库中只有“盲人 → 需要拐杖”,而没有出现“视障人士”这个词,传统方法很可能漏检。 KAG采用两种语义驱动的检索方式: (1)三元组检索(Triple Retrieval)
- 输入:逻辑形式中的实体及其类型
- 过程:利用语义图进行候选节点召回 → 一跳扩展生成候选子图 → 匹配符合条件的事实三元组
- 输出:结构化知识片段,可用于直接作答
(2)文档检索(Document Retrieval)
-
基于个性化PageRank(PPR)算法,在语义图上计算文档相关性得分
-
种子节点不仅来自原始查询,还包括:
-
逻辑形式中的实体
-
三元组检索生成的候选子图节点
-
查询语义增强后的新实体(如同义词、上位词)
这种方式能有效捕捉“语义近邻”而非“字面匹配”的文档,显著提升长距离推理的召回能力。 ⚖️ 策略选择:KAG优先尝试用三元组回答;失败后再启用文档检索作为兜底方案。 三、实验结果
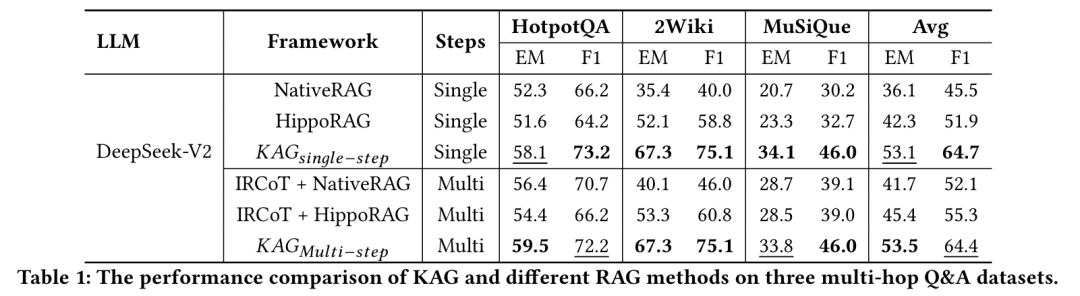
KAG 在三个多跳问答数据集(HotpotQA、2WikiMultiHopQA、MuSiQue)上的实验结果显示,其性能显著优于现有方法(如 HippoRAG): * 在单步推理任务中,KAG 平均 F1 分数比 HippoRAG 提高了 12.8% 。
- 即便在多步CoT增强下,KAG依然保持明显优势。
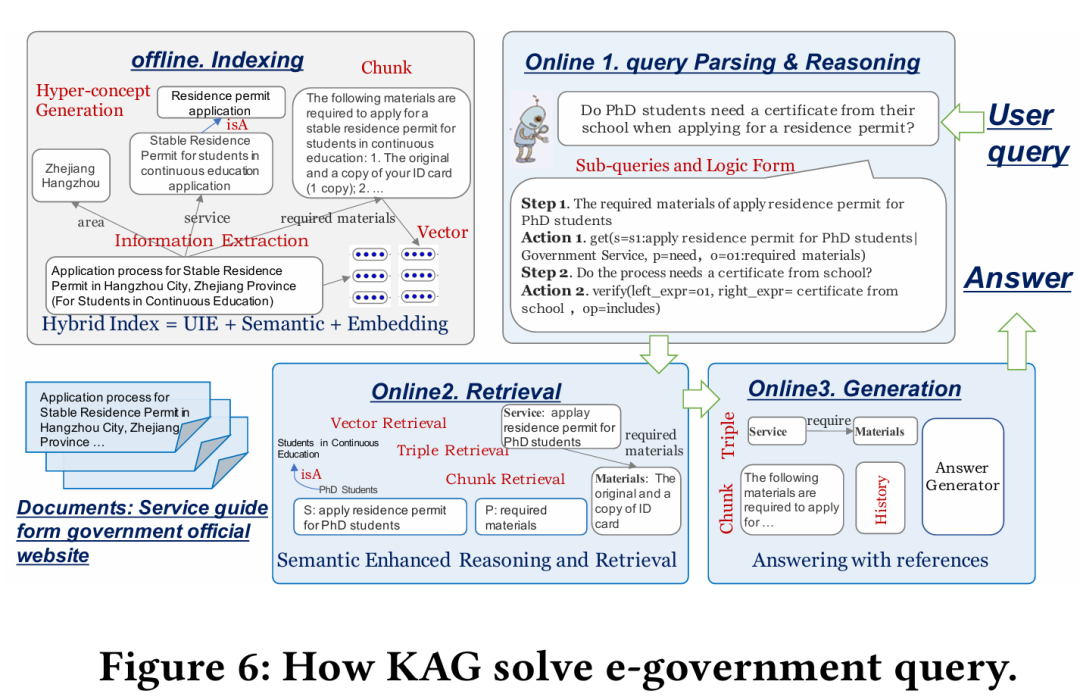
此外,KAG 在 e-Government 场景中的应用也显示了其在专业领域问答系统中的显著优势。
四、应用
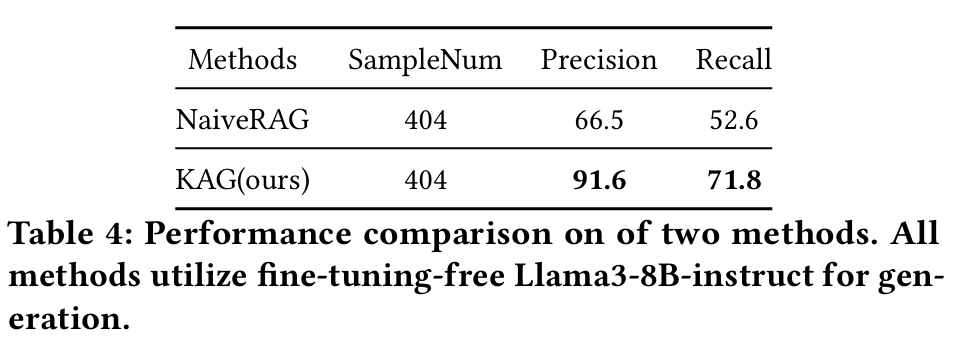
KAG 已成功应用于蚂蚁集团的实际业务场景中,包括 e-Government、E-Health、Legal Consultation 和 Risk Management 等领域。 在 e-Government 场景中,KAG 负责基于给定的知识库回答用户的行政流程问题,其准确率显著高于传统 RAG 方法(如下表)。例如,在 404 个用户问题中,KAG 的精度达到了 **91.6% **,召回率达到 **71.8% **,远超 NaiveRAG(精度 66.5%,召回率 52.6%)。
五、总结
KAG 是一个融合 LLMs 和知识图谱(KG)技术的新框架,通过在索引和检索阶段引入语义理解和推理,有效提升了复杂问答任务的表现。实验证明,KAG 不仅在学术数据集上表现出色,还在实际应用中展现了巨大潜力。


