【泡泡一分钟】Grad-CAM(加权梯度类激活映射):可视化解释基于梯度定位的深度网络(ICCV2017-60)
泡泡一分钟,带你精读机器人顶级会议文章
标题:Grad-CAM:Visual Explanations from Deep Networks via Gradient-based Localization
作者:Ramprasaath R. Selvaraju ,Michael ogswell,Abhishek Das,Ramakrishna Vedantam,Devi Parikh,Dhruv Batra
来源:International Conference on Computer Vision (ICCV 2017)
播音员:郭晨
编译:王健,周平(65)
欢迎个人转发朋友圈;其他机构或自媒体如需转载,后台留言申请授权

摘要

大家好,今天为大家带来的文章——Grad-CAM(加权梯度类激活映射):一种可视化解释基于梯度定位的深度网络,该文章发表ICCV 2017。
本文提出一种技术,为卷积神经网络模型的分类图像作“可视化解释”,使它们的特征区域更加明显可见。本文所用方法——加权梯度类激活映射,使任何目标特征的梯度(也就是“狗”或者描述文字的逻辑表征)经过最后一个卷积层后产生大致的局部特征图,凸显出图像中对目标预测分类重要的区域。不同于之前的方法,Grad-CAM适用于各种各样的CNN网络模型且不会改变网络结构,也不需要重新训练:(1)用于具有全连接层的CNN网路(如VGG);(2)用于结构化输出的CNN网络(如文字描述);(3)用于多输入任务的CNN网络(如视觉问答)。本文将现有的细粒度可视化方法与Grad-CAM结合产生高分辨率的分类可视化特征,并将其运用到图像分类,图像文字描述以及视觉问答,包括基于Res-Net的网络结构。在图像分类模型的背景下,本文的可视化特征(a)为这些模型中的故障模型提供了解释依据(看起来不合理的预测有了合理的解释)(b)在ILSVRC-15弱监督定位任务上优于以前的方法(c)与基础模型结合紧密(d)通过识别数据集偏差达到模型归一化。对于图像文字描述和视觉问答问题,本文的可视化特征显示,即使是非注意力机制模型也能定位输入。最后,如果Grad-CAM方法能够帮助用户对从深度网络中得到的预测建立合理的解释,并且当两种网络做出同样的预测时帮助用户区分“强”深度网络和“弱”深度网络,本文设计了一套评价标准去衡量Grad-CAM方法得到的解释信息,并指导研究人员使用。
本文网络结构如图。
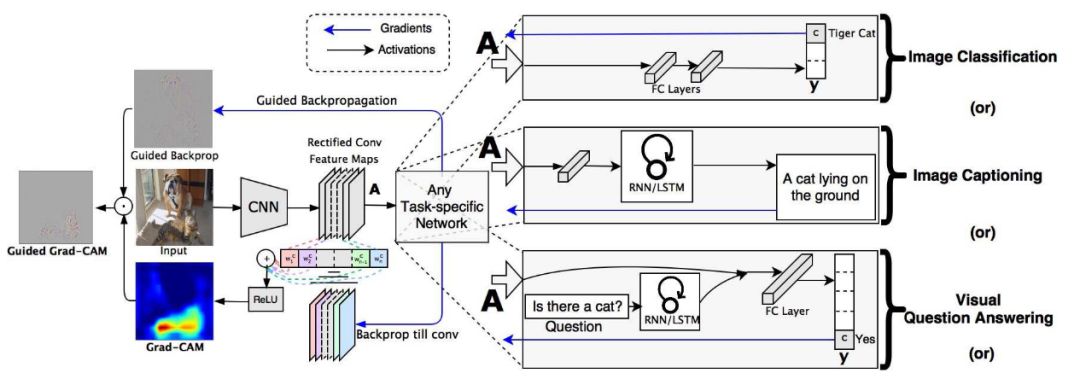
图1
给定一张图像和一个感兴趣类别(如“虎纹猫”或者其他可区分输出类别)作为输入,将图像前向传播,经过模型的CNN层,然后通过计算得到置信度分数和类别。除了期望的类别(虎纹猫)设置为1,其他所有的类均设置为0。然后信号反向传播修正感兴趣区域的卷积特征图,在这里会计算粗略的Grad-CAM定位图(蓝色热图),图显示的是模型需要判定的目标类别所在的位置。最后,将热图与反向传播逐点相乘,以获得高分辨率和特征明确的Grad-CAM可视化图。

We propose a technique for producing ‘visual explanations’ for decisions from a large class of Convolutional Neural Network (CNN)-based models, making them more transparent. Our approach – Gradient-weighted Class Activation Mapping (Grad-CAM), uses the gradients of any target concept (say logits for ‘dog’ or even a caption), flowing into the final convolutional layer to produce a coarse localization map highlighting the important regions in the image for predicting the concept. Unlike previous approaches, Grad-CAM is applicable to a wide variety of CNN model-families: (1) CNNs with fully-connected layers (e.g. VGG), (2) CNNs used for structured outputs (e.g. captioning), (3) CNNs used in tasks with multi-modal inputs (e.g. visual question an- swering) or reinforcement learning, without architectural changes or re-training. We combine Grad-CAM with existing fine-grained visualizations to create a high-resolution class-discriminative visualization, Guided Grad-CAM, and apply it to image classification, image captioning, and visual question answering (VQA) models, including ResNet-based architectures. In the context of image classification models, our visualizations (a) lend insights into failure modes of these models (showing that seemingly unreasonable predictions have reasonable explanations), (b) outperform previous methods on the ILSVRC-15 weakly-supervised localization task, (c) are more faithful to the underlying model, and (d) help achieve model generalization by identifying dataset bias. For image captioning and VQA, our visualizations show even non-attention based models can localize inputs. Finally, we design and conduct human studies to measure if Grad-CAM explanations help users establish appropriate trust in predictions from deep networks and show that Grad-CAM helps untrained users successfully discern a ‘stronger’ deep network from a ‘weaker’ one even when both make identical predictions.
如果你对本文感兴趣,想要下载完整文章进行阅读,可以关注【泡泡机器人SLAM】公众号。
作者代码下载链接:https: //github.com/ramprs/grad-cam/
欢迎来到泡泡论坛,这里有大牛为你解答关于SLAM的任何疑惑。
有想问的问题,或者想刷帖回答问题,泡泡论坛欢迎你!
泡泡网站:www.paopaorobot.org
泡泡论坛:http://paopaorobot.org/forums/


泡泡机器人SLAM的原创内容均由泡泡机器人的成员花费大量心血制作而成,希望大家珍惜我们的劳动成果,转载请务必注明出自【泡泡机器人SLAM】微信公众号,否则侵权必究!同时,我们也欢迎各位转载到自己的朋友圈,让更多的人能进入到SLAM这个领域中,让我们共同为推进中国的SLAM事业而努力!
商业合作及转载请联系liufuqiang_robot@hotmail.com




