论文题目:CKnowEdit: A New Chinese Knowledge Editing Dataset for Linguistics, Facts, and Logic Error Correction in LLMs
本文作者:Jizhan Fang, Tianhe Lu, Yunzhi Yao, Ziyan Jiang, Xin Xu, Huajun Chen, Ningyu Zhang
发表会议:ACL 2025
论文链接:https://arxiv.org/abs/2409.05806
代码链接:https://zjunlp.github.io/project/CKnowEdit/
欢迎转载,转载请注明出处****

在当前大模型快速发展的背景下,模型固有知识的更新能力成为研究焦点。尽管已有大量知识编辑研究集中于英语及其维基百科语料,但中文作为具有深厚文化底蕴和复杂语言结构的语言系统,在知识编辑研究中仍显不足。 本文介绍发表于ACL 2025的研究成果——CKnowEdit,这是专为面向中文语言的的知识编辑数据集,涵盖中文语言的语言性、事实性与逻辑性错误。 一、背景与动机
当前主流的大语言模型(LLMs)由于其基于静态训练语料,缺乏显式知识结构,往往会产生幻觉(hallucination)、偏见、甚至不当输出。在面对中文语境时,模型能力瓶颈尤为明显,原因在于:
- 语言复杂性:中文字形、音、义结合紧密,语法灵活,诗词、成语等语言结构远超英文复杂度。
- 文化性事实:涉及特定历史、地理文化背景的信息难以用英语语料迁移。
- 逻辑结构差异:中文偏重话题优先、隐含连接词、上下文逻辑推理,常与英语基于谓语结构的逻辑体系不符。
**
**
二、数据集设计:三大类十子类
CKnowEdit数据类型 CKnowEdit从上述三个挑战出发,将知识错误划分为三大类,共十个子类,涵盖语言现象、事实知识与逻辑误判:
一、语言类(Linguistic)
- 拼音(Pinyin):多音字歧义,如“六”读作“liù”与“lù”。
- 古诗(Ancient Poetry):格律、用字精确,模型难以记忆。
- 文言文(Classical Chinese):语义漂移严重,需上下文判断。
- 成语(Idiom):字面与实际含义相悖,误解常见。
- 谚语(Proverb):需隐喻理解,难以类比应用。
二、事实类(Fact)
- 历史与地理知识:涉及特定中国历史事件、地理名词。
三、逻辑类(Logic)
- 语音误解(Phonetic Misunderstand):多音字错解导致语义扭曲。
- 推理错误(Reasoning Error):复杂多步推理中产生逻辑错判。
- 文字游戏(Wordplay):词语歧义、分词错误导致歧解。
**
**
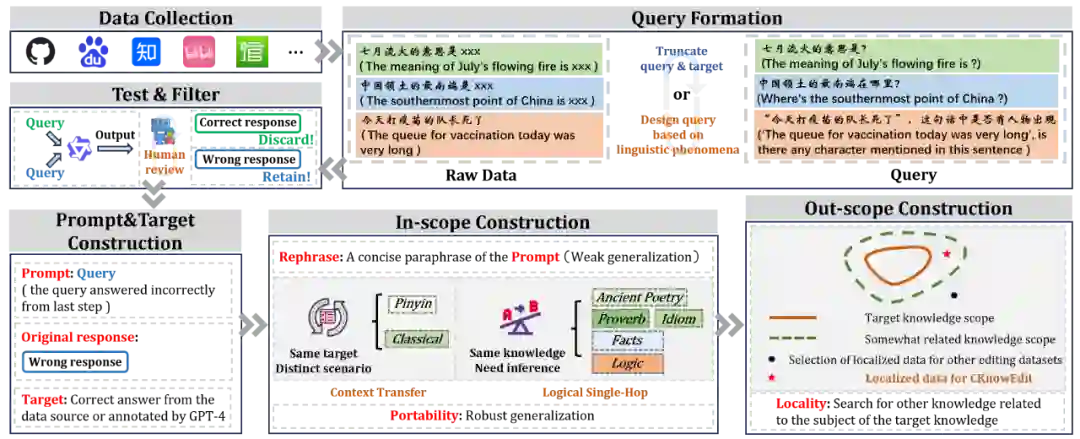
三、数据构建流程
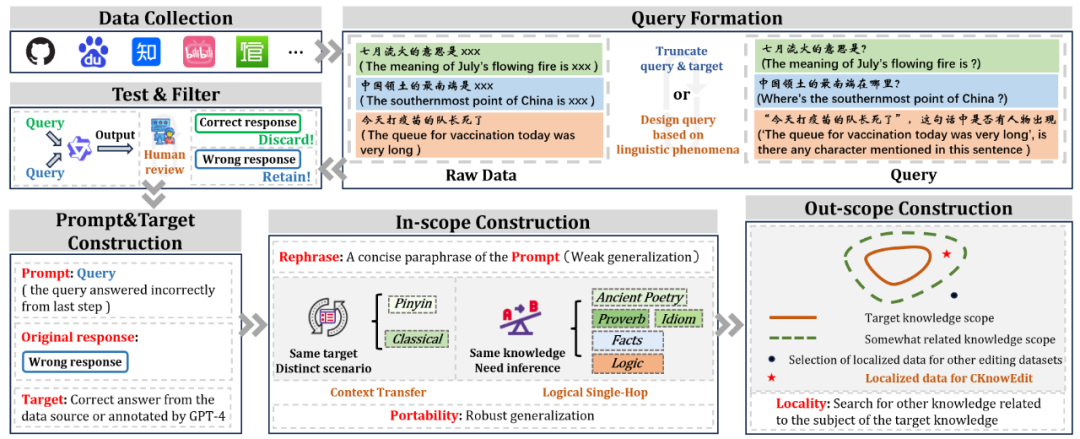
CKnowEdit构建流程
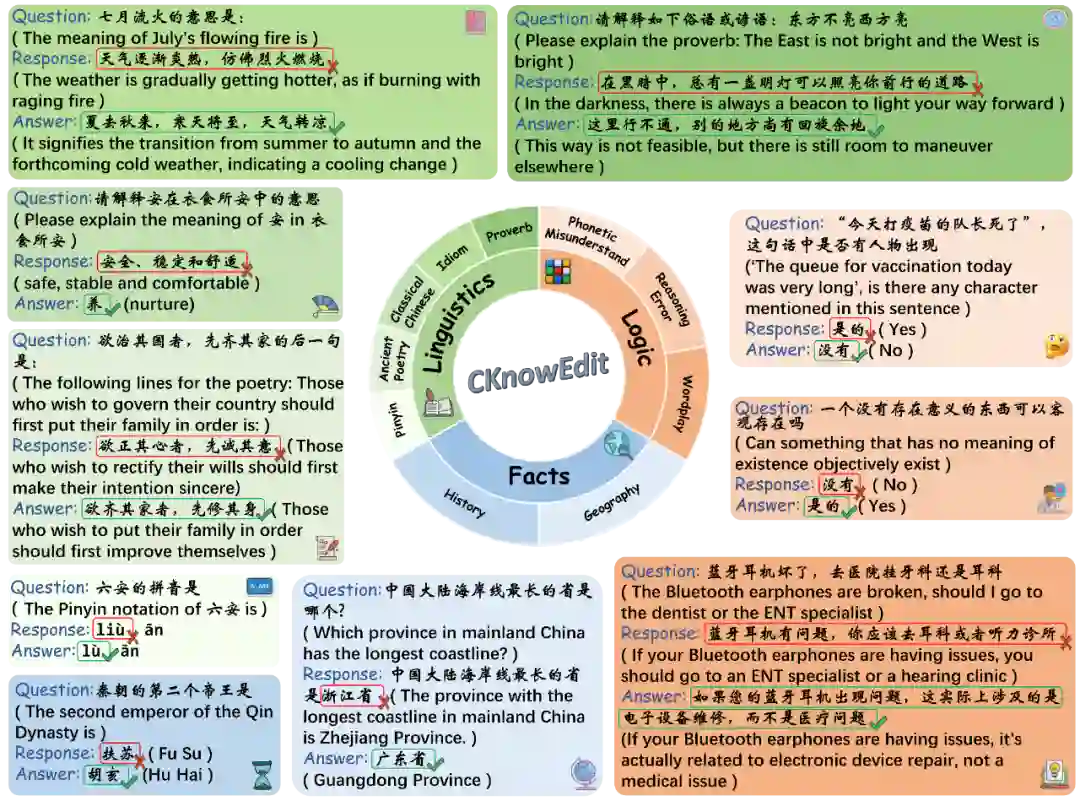
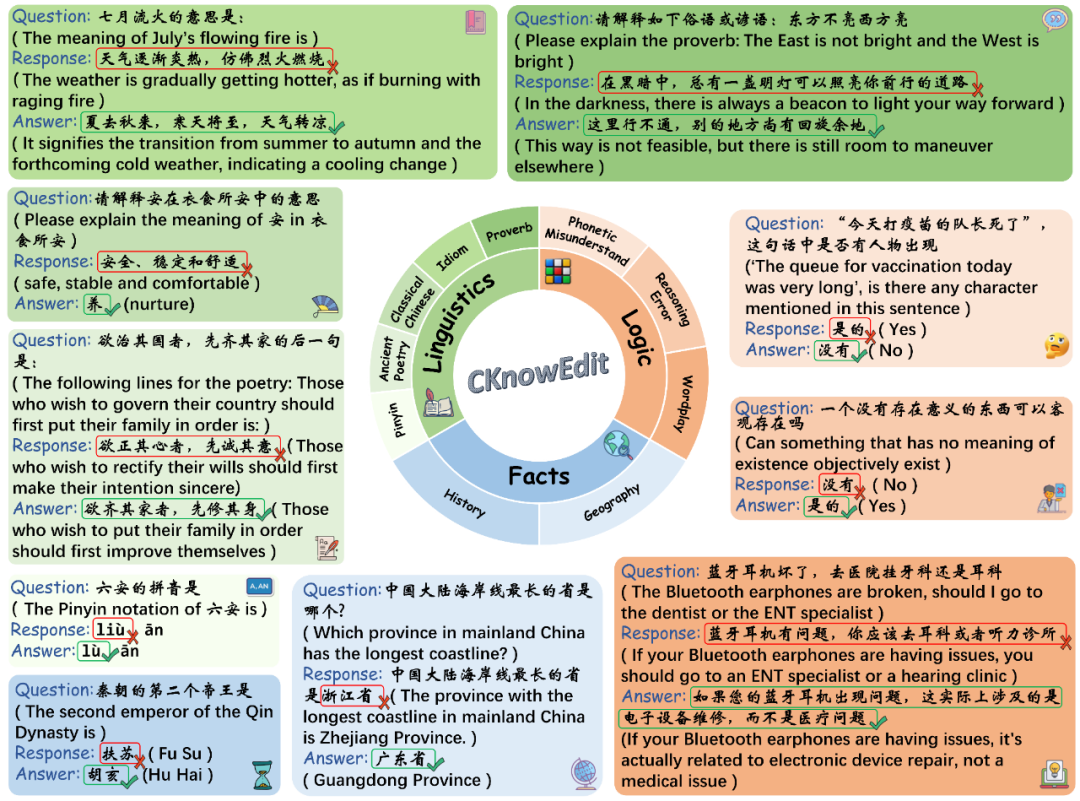
- 数据收集:涵盖古典文学、网络论坛(如百度贴吧弱智吧)等多源文本,初步获取11,981条数据。
- 筛选机制:采用Qwen-7B-Chat模型,保留其回答错误的样本,提升数据挑战性。
- 标注流程:
- 正确答案由GPT-4生成,经人工校验。
- 构建 泛化测试(Generalization) 和 局部性测试(Locality) 字段,评估编辑后的知识是否具备迁移能力或是否干扰无关知识。
- 最终规模:共1,854条高质量编辑样本。
**
**
四、模型评估与实验结果
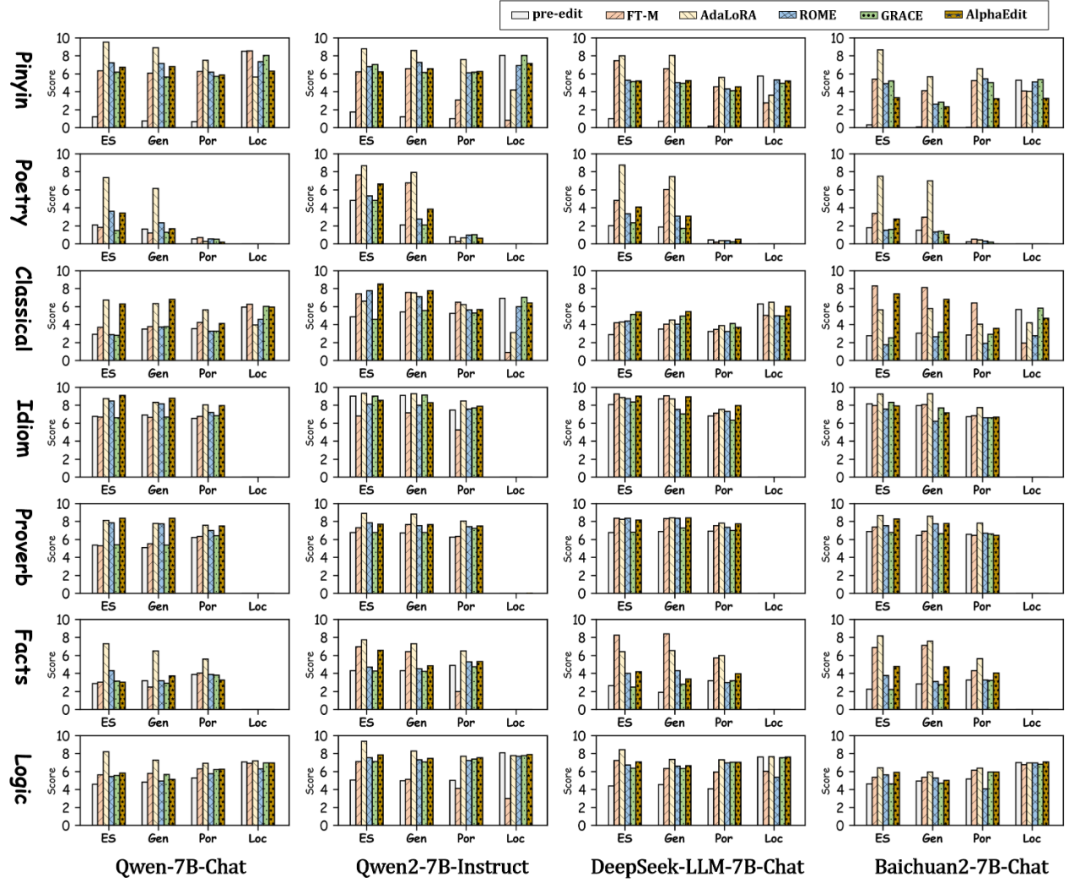
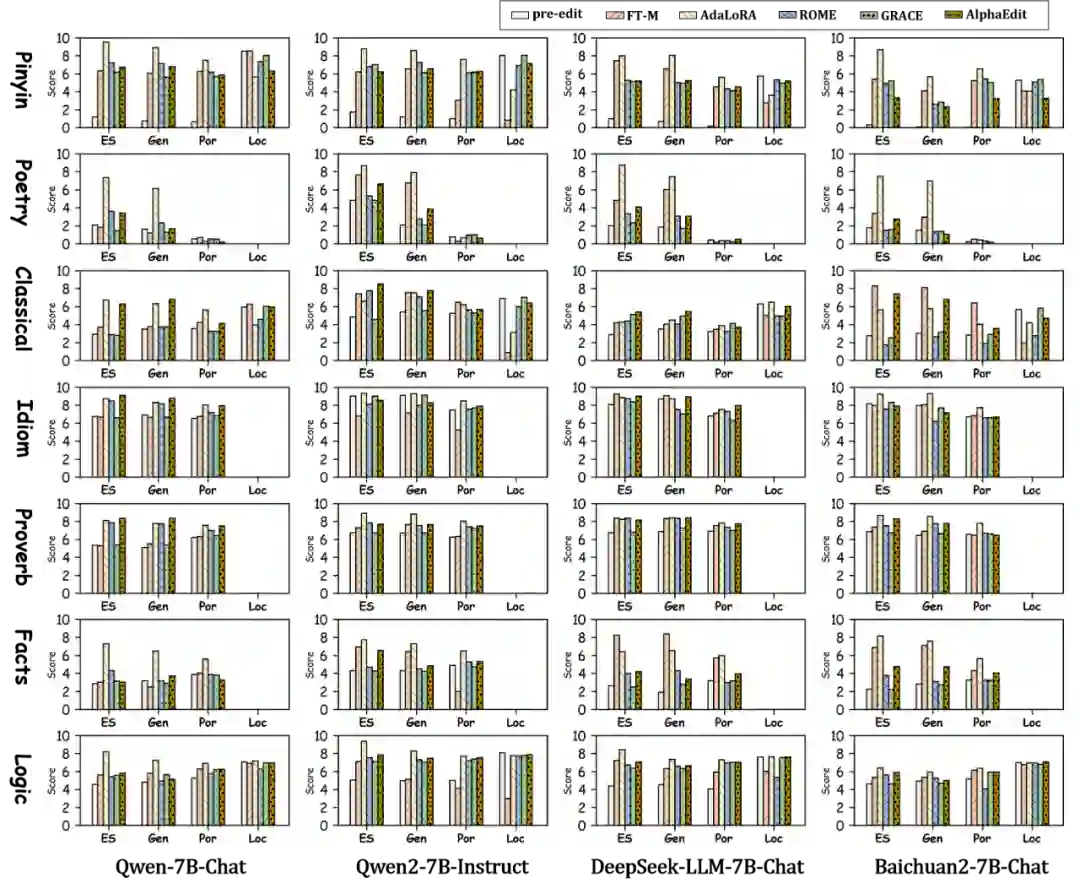
CKnowEdit实验主表
编辑方法
选用主流五种知识编辑方法(如AdaLoRA、ROME、AlphaEdit等),在四个主流中文大模型(Qwen、Qwen2、DeepSeek、Baichuan)上进行实验。
评估方式
摒弃token级评估,改用开放生成任务 + GPT-4o评分器的“LLM-as-a-judge”机制,评估维度包括:
-
编辑成功率(Edit Success, ES)
-
弱泛化能力(Generalization, Gen)
-
强泛化能力(Portability, Por)
-
局部性(Locality, Loc)
主要发现
- AdaLoRA在各指标中表现最优,尤其在长文本生成任务中效果突出。
- 对于语言类中的“古诗”“文言文”,所有模型与方法均表现不佳,说明当前模型对中文语言的记忆与理解仍存在显著短板。
- 英文翻译无法替代中文原文,特别在语言与逻辑类任务上,翻译会导致信息丢失,编辑质量下降。
**
**
五、数据集价值与意义
CKnowEdit的提出具有如下意义:
- 语言特性:为研究中文语义、语法、文化相关错误提供系统性资源。
- 评估机制:结合人类评估与GPT-4o自动评分,具备高一致性。
- 多维能力验证:支持泛化性与局部性测试,有助于发展稳健的知识编辑方法。
该数据集不仅能推动中文模型微调与校正,也为多语言知识编辑研究提供了对照样本。 六、开源信息
- 数据集与代码已开源:https://github.com/zjunlp/EasyEdit
**
**
七、关于CKnowEdit的CCKS2025评测大赛
为了更好的研究中文编辑所存在的难点和困境,我们与CCKS协会联合阿里云天池平台共同举办了以CKnowEdit为赛题数据的大模型中文知识编辑大赛。
- 比赛链接如下:CCKS2025知识编辑比赛
- 本次比赛初赛复赛使用的数据集均为CKnowEdit,初赛为
singleton edit设定,复赛为continues edit设定。
欢迎感兴趣的各位同学、老师或者是业界同行来参加我们的比赛,一起交流玩耍!