

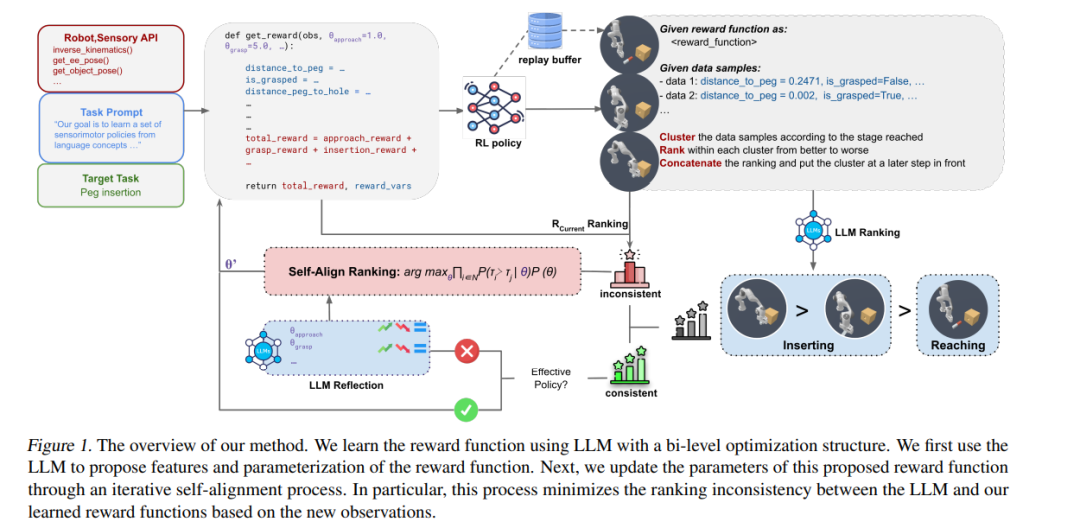
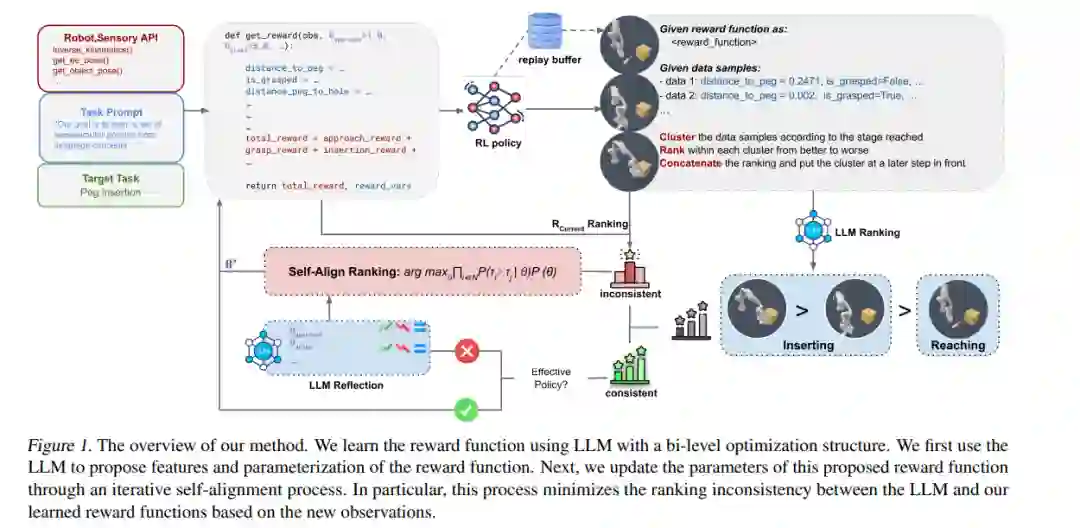
学习奖励函数仍是让机器人掌握广泛技能的瓶颈。大型语言模型(LLM)包含有价值的与任务相关的知识,这可能有助于学习奖励函数。然而,所提出的奖励函数可能不够精确,因而效果不佳,需要进一步与环境信息相结合。我们提出了一种在无人参与的情况下更高效学习奖励的方法。我们的方法包括两个组成部分:首先使用LLM提出奖励的特征和参数化,然后通过迭代的自对齐过程更新参数。特别是,该过程通过执行反馈最小化LLM与学习到的奖励函数之间的排名不一致性。该方法在9个任务和2个模拟环境中进行了验证。它展示了与训练效果和效率相比的一致性改进,同时与替代的基于突变的方法相比,消耗的GPT令牌显著减少。项目网站:https://sites.google.com/view/rewardselfalign.
成为VIP会员查看完整内容

相关内容

相关VIP内容
相关资讯
相关论文