

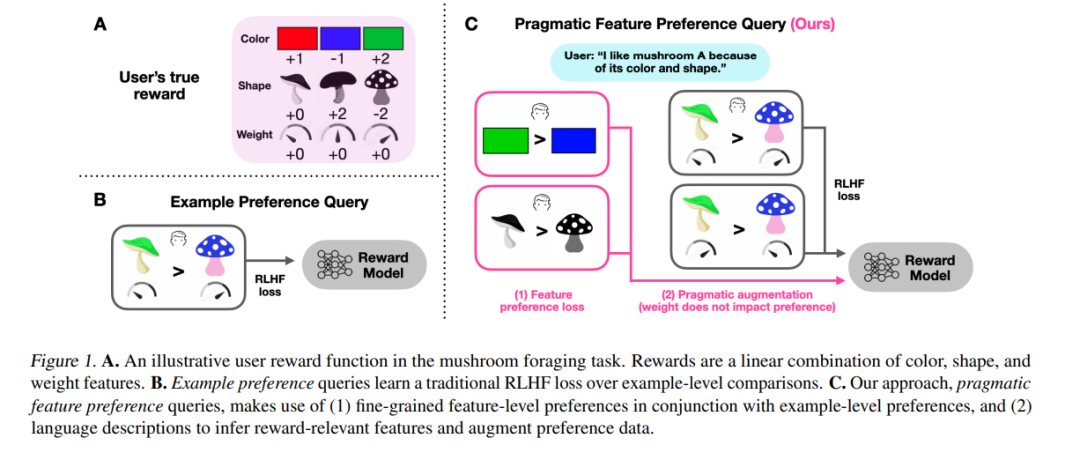
人类使用社会背景来指定对行为的偏好,即他们的奖励函数。然而,从偏好数据中推断奖励模型的算法并未考虑这种社会学习视角。受到人类语用交流的启发,我们研究了如何提取关于为什么一个示例被偏好的细粒度数据,这对于学习更准确的奖励模型是有用的。我们提出丰富二元偏好查询,不仅询问(1)给定示例中的哪些特征是更可取的,还询问(2)示例之间的比较。我们推导了一种从这些特征级别的偏好中学习的方法,无论用户是否指定哪些特征与奖励相关。我们在视觉和语言领域的线性强盗设置中评估了我们的方法。结果支持我们的方法能够通过更少的比较迅速收敛到准确的奖励,而不是仅依靠示例标签。最后,我们通过蘑菇觅食任务的行为实验验证了其现实世界的适用性。我们的研究结果表明,结合语用特征偏好是一种更高效的用户对齐奖励学习的有前途的方法。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日