KDD 2019 | 自动探索特征组合,第四范式提出新方法AutoCross
机器之心专栏
作者:罗远飞、王梦硕、周浩、姚权铭
涂威威、陈雨强、杨强、戴文渊
特征组合是提高模型效果的重要手段,但依靠专家手动探索和试错成本过高且过于繁琐。于是,第四范式提出了一种新型特征组合方法 AutoCross,该方法可在实际应用中自动实现表数据的特征组合,提高机器学习算法的预测能力,并提升效率和有效性。目前,该论文已被数据挖掘领域顶会 KDD 2019 接收。
论文简介
论文:AutoCross: Automatic Feature Crossing for Tabular Data in Real-World Applications

论文链接:https://arxiv.org/pdf/1904.12857.pdf
本文提出了一种在实际应用中自动实现表数据特征组合的方法 AutoCross。该方法可以获得特征之间有用的相互作用,并提高机器学习算法的预测能力。该方法利用集束搜索策略(beam search strategy)构建有效的组合特征,其中包含尚未被现有工作覆盖的高阶(两个以上)特征组合,弥补了此前工作的不足。
此外,该研究提出了连续小批量梯度下降和多粒度离散化,以进一步提高效率和有效性,同时确保简单,无需机器学习专业知识或冗长的超参数调整。这些算法旨在降低分布式计算中涉及的计算、传输和存储成本。在基准数据集和真实业务数据集上的实验结果表明,AutoCross 可以显著提高线性模型和深度模型对表数据的学习能力和性能,优于其他基于搜索和深度学习的特征生成方法,进一步证明了其有效性和效率。
背景介绍
近年来,机器学习虽然已在推荐系统、在线广告、金融市场分析等诸多领域取得了很多成功,但在这些成功的应用中,人类专家参与了机器学习的所有阶段,包括:定义问题、收集数据、特征工程、调整模型超参数,模型评估等。
而这些任务的复杂性往往超出了非机器学习专家的能力范围。机器学习技术使用门槛高、专家成本高昂等问题成为了制约 AI 普及的关键因素。因此,AutoML 的出现被视为提高机器学习易用性的一种最有效方法,通过技术手段减少对人类专家的依赖,让更多的人应用 AI,获得更大的社会和商业效益。
众所周知,机器学习的性能很大程度上取决于特征的质量。由于原始特征很少产生令人满意的结果,因此通常要对特征进行组合,以更好地表示数据并提高学习性能。例如在新闻推荐中,若只有新闻类型、用户 ID 两类特征,模型只能分别预测不同新闻类型或不同用户 ID 对点击率的影响。通过加入新闻类型 x 用户 ID 组合特征,模型就可学习到一个用户对不同新闻的偏好。再加入时间等特征进行高阶组合,模型就可对一个用户在不同时间对不同新闻的偏好进行预测,提升模型的个性化预测能力。
特征组合作为提高模型效果的重要手段,以往大多需要构建庞大的数据科学家团队,依靠他们的经验进行探索和试错,但繁琐、低效的过程令科学家十分痛苦,且并非所有企业都能承受高昂的成本。
第四范式从很早便开始关注并深耕 AutoML 领域,从解决客户业务核心增长的角度出发,构建了反欺诈、个性化推荐等业务场景下的 AutoML,并将其赋能给企业的普通开发人员,取得了接近甚至超过数据科学家的业务效果。其中,AutoCross 发挥了重要的作用。
痛点
特征组合是对从数据中提取的海量原始特征进行组合的过程,采用稀疏特征叉乘得出组合特征。在线性模型如 LR 只能刻画特征间的线性关系、表达能力受限,而非线性模型如 GBDT 不能应用于大规模离散特征场景的情况下,特征组合能够增加数据的非线性,从而提高性能。
但枚举所有组合特性,理论上很难做到,因为可能的组合特征数是指数级的,同时暴力添加特征可能会导致学习性能下降,因为它们可能是无关的或冗余的特征,从而增加学习难度。
虽然深度神经网络可自动构建高阶特征 (generate high-order features),但面对大多数以表形式呈现的业务数据,最先进的基于深度学习的方法无法有效涵盖所有高阶组合特征,且存在可解释性差、计算成本高等弊端。该论文投稿时,最先进的深度学习方法是 xDeepFM [1]。这篇论文证明了 xDeepFM 可生成的特征是 AutoCross 可生成特征嵌入(embedding)的子集。
AutoCross 的优势
高效+高阶:AutoCross 可高效构建高阶组合特征,进一步提高学习性能;
易用:AutoCross 具有高度的简单性和最小化的超参数。提出了连续的小批量梯度下降和多粒度离散化,提高了特征组合的效率和有效性,同时避免了繁琐的超参数设置;
通用性:AutoCross 生成的特征可用于传统机器学习模型或深度模型;
分布式计算:AutoCross 充分利用分布计算能力,提高特征组合的效率,并降低计算、传输和存储成本;
快速推断:AutoCross 可以大幅提高线性模型的效果,并且保留其推断速度快的优势;
可解释性:AutoCross 采用显式特征组合的方法,相比于隐式特征组合,具有高度的可解释性。
实现过程
给定训练数据 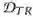
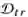
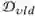
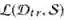
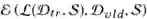
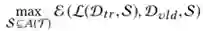
其中 F 是 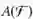
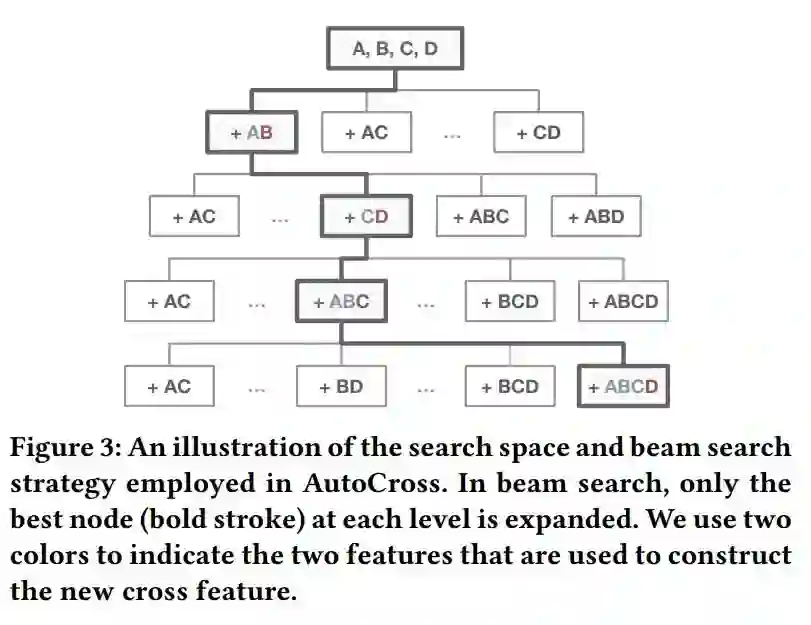
但是,假设原始特征数为 d,则上述问题中所有可能解的数量是 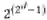
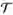
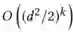

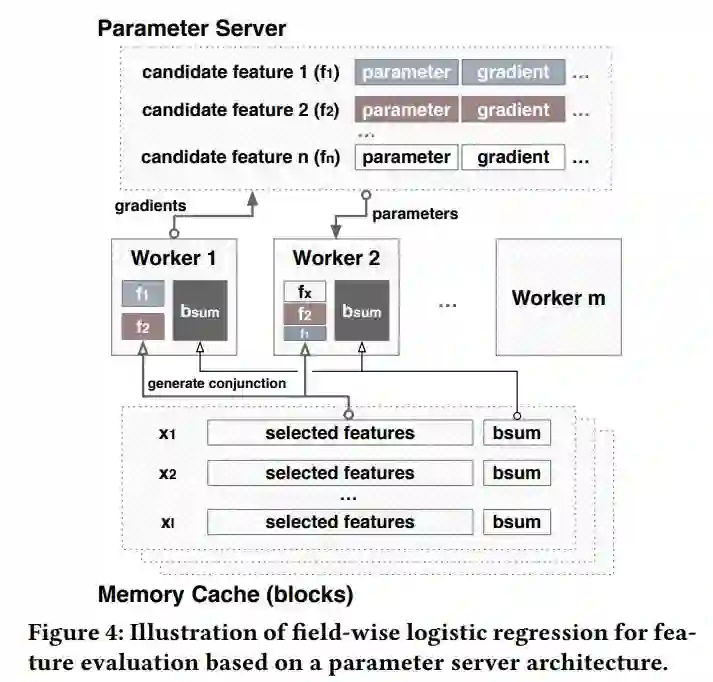
算法 1 中的一个关键步骤是评估候选特征集。最直接的方法是用每个候选特征集训练模型并评估其性能,但是这种方法计算代价巨大,难以在搜索过程中反复执行。为了提高特征集评估的效率,AutoCross 提出了逐域对数几率回归(field-wise logistic regression)和连续批训练梯度下降(successive mini-batch gradient descent)方法。
为了提高特征集评估效率,逐域对数几率回归作出两种近似。首先,用特征集在对数几率回归模型上的表现近似最终将使用这个特征集的模型上的表现;其次,在考虑
图 4 说明了如何将逐域对数几率回归部署在参数服务器架构上。逐域对数几率回归与参数服务器的结合可以提高特征集评估的存储效率、传输效率和计算效率。在逐域对数几率回归训练结束后,AutoCross 计算训练得模型的指标,并以此方法来评估每一个候选特征集。
AutoCross 采用连续批训练梯度下降方法进一步提高特征集评估的效率。该方法借鉴 successive halving 算法 [2],认为每一个候选特征集是 multi-arm bandit 问题中的一个 arm,对一个特征集用一个数据块进行权重更新相当于拉了一次对应的 arm,其回报为该次训练后的验证集 AUC。
具体算法见算法 2,算法 2 中唯一的参数是数据块的数量 N。N 可以根据数据的大小和计算环境自适应地确定。在使用连续批训练梯度下降时,用户不需要像使用传统的 subsampling 方法一样调整 mini-batch 的尺寸和采样率。

为了支持数值特征与离散特征的组合,AutoCross 在预处理时将数值特征离散化为离散特征。AutoCross 提出了多粒度离散化(multi-granularity discretization)方法,使得用户不需要反复调整离散化的粒度。多粒度离散化思想简单:将每一个数值特征,根据不同粒度划分为多个离散特征。然后采用逐域对数几率回归挑选出最优的离散特征。多个划分粒度既可以由用户指定,也可以由 AutoCross 根据数据大小和计算环境来自适应地选择,从而降低了用户的使用难度。
实验结果
该论文在十个数据集(五个公开、五个实际业务)上进行了实验。比较的方法包括:
AC+LR:AutoCross 的特征加对数几率回归模型;
AC+W&D:AutoCross 的特征作为 wide&deep 模型 wide 部分的特征;
LR:基础的对数几率回归模型;
CMI+LR:[3] 中方法生成的特征加对数几率回归模型;
Deep:基础的深度学习模型;
xDeepFM:[1] 提出的模型,是该论文投稿时最先进的基于深度学习的方法。
效果比较:如下表 3 所示,AC+LR 和 AC+W&D 在大部分数据集上的排名都在前两位。这体现了 AutoCross 产生的特征不仅可以增强 LR 模型,也可以用于提高深度学习模型的性能,并且 AC+LR 和 AC+W&D 的效果都优于 xDeepFM。如之前所说,xDeepFM 所生成的特征不能完全包含 AutoCross 生成的特征。这些结果体现出显式生成高阶组合特征的效果优势。
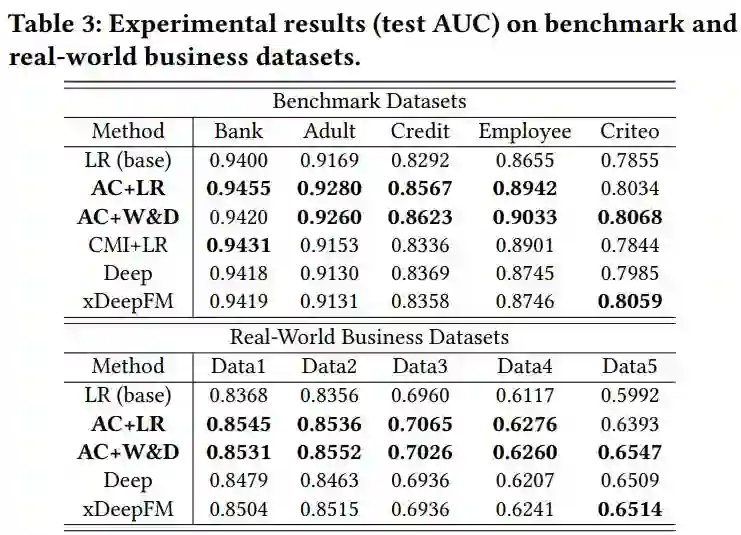
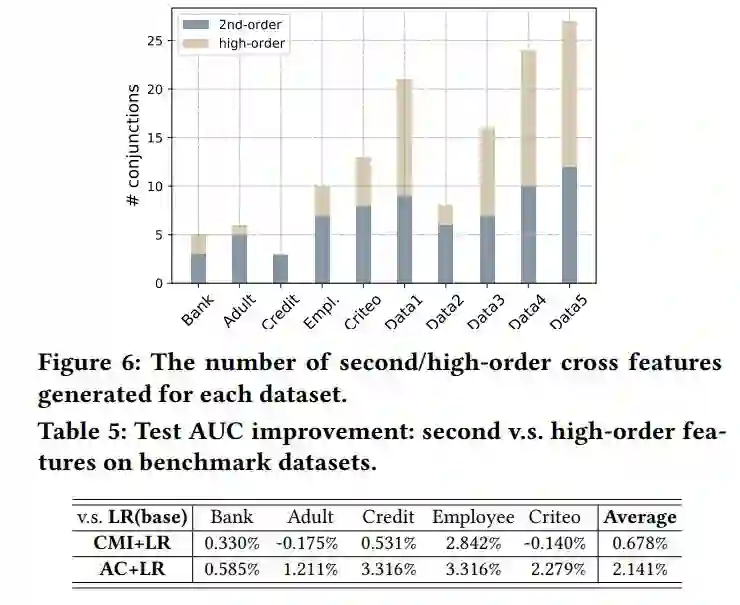
高阶特征的作用:见表 5 和图 6。从中可以得出,高阶组合特征可以有效提高模型性能。
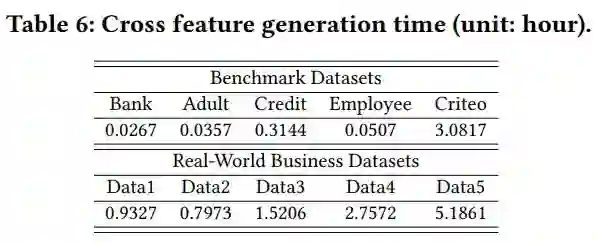
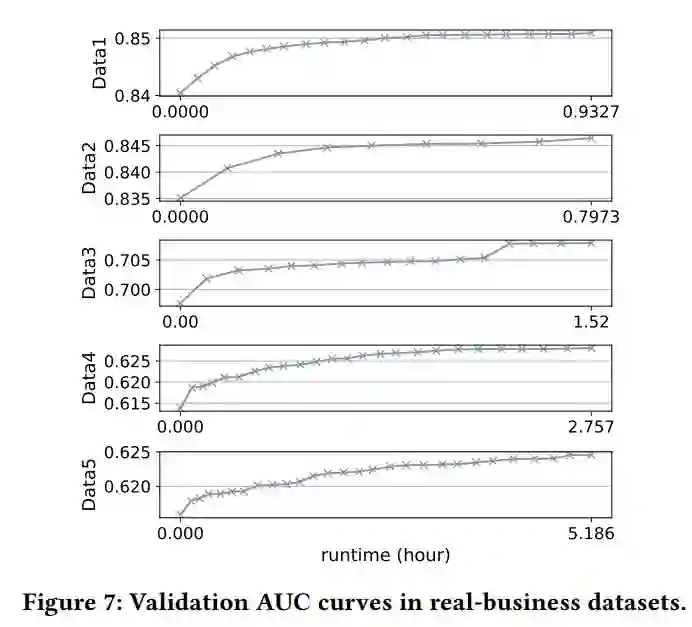
时间消耗:见表 6、图 7(主要做展示用)。
推断延迟:见表 7。从中可以得出:AC+LR 的推断速度比 AC+W&D、Deep、xDeepFM 快几个数量级。这说明 AutoCross 不仅可以提高模型表现,同时保证了很低的推断延迟。

参考文献
[1] J. Lian, X. Zhou, F. Zhang, Z. Chen, X. Xie, and G. Sun. 2018. xDeepFM: Com- bining Explicit and Implicit Feature Interactions for Recommender Systems. In International Conference on Knowledge Discovery & Data Mining.
[2] K. Jamieson and A. Talwalkar. 2016. Non-stochastic best arm identification and hyperparameter optimization. In Artificial Intelligence and Statistics. 240–248.
[3] O. Chapelle, E. Manavoglu, and R. Rosales. 2015. Simple and scalable response prediction for display advertising. ACM Transactions on Intelligent Systems and Technology (TIST) 5, 4 (2015), 61.
本文为机器之心专栏,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com



