

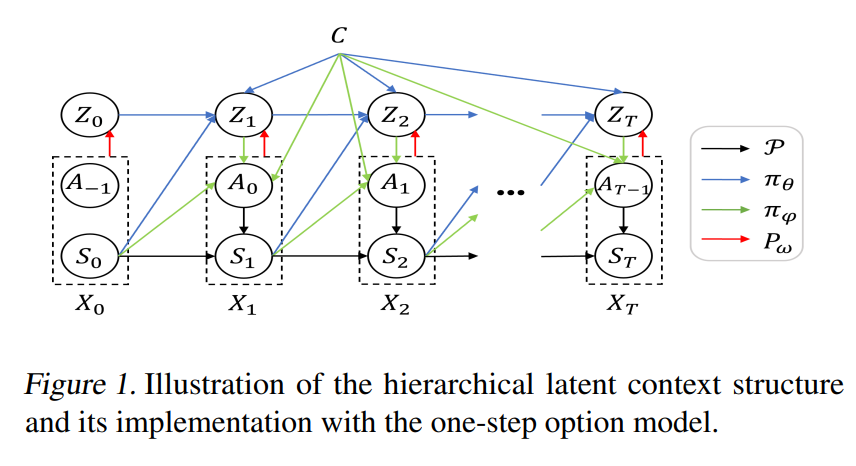
多任务模仿学习 (MIL) 旨在基于多任务专家演示训练能够执行任务分布的策略,这对通用机器人至关重要。现有的 MIL 算法在复杂长水平任务上的数据效率低下且表现不佳。我们开发了多任务层次对抗逆强化学习 (MH-AIRL) 以学习层次结构化的多任务策略,这对于具有长视野的组合任务更有利,并且通过识别和跨任务传输可重复使用的基本技能,具有更高的专家数据效率。为实现这一目标,MH-AIRL 有效地综合了基于上下文的多任务学习、AIRL (一种 IL 方法) 和层次策略学习。此外,MH-AIRL 可以应用于没有任务或技能注释的演示 (即,只有状态动作对),这在实践中更易获取。MH-AIRL 的每个模块都提供了理论依据,而在挑战性的多任务设置上的评估证明,与 SOTA MIL 基线相比,MH-AIRL 学到的多任务策略具有优越的性能和可转移性。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年7月13日
Arxiv
0+阅读 · 2023年7月11日
Arxiv
11+阅读 · 2021年2月18日

相关VIP内容
相关资讯