

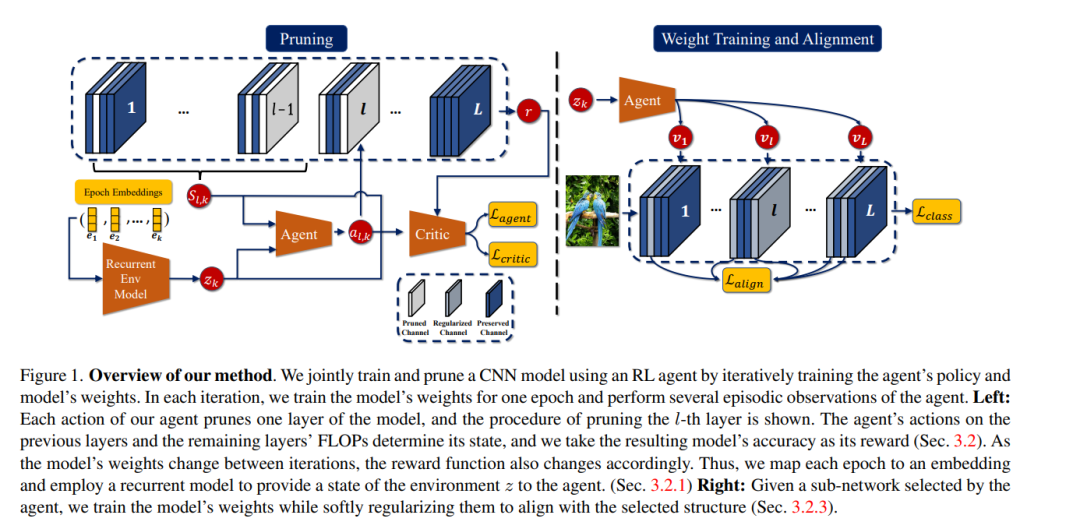
在部署到资源受限设备之前,结构模型剪枝是一种用于减少卷积神经网络(CNNs)计算成本的突出方法。然而,大多数提出的想法在剪枝前需要一个预训练的模型,这是成本高昂的。在本文中,我们提出了一种新颖的结构剪枝方法,用于共同学习权重并结构性地剪枝CNN模型的架构。我们方法的核心元素是一个强化学习(RL)代理,其行动决定了CNN模型层的剪枝比例,而得到的模型准确率作为其奖励。我们通过迭代训练模型的权重和代理的策略来进行联合训练和剪枝,并且我们规范模型的权重以与代理选择的结构对齐。不断演变的模型权重导致了一个动态的奖励函数给代理,这防止了使用假设环境稳定的著名情节性RL方法达到我们的目的。我们通过设计一种机制来解决这一挑战,该机制能够模拟奖励函数复杂变化动态,并将其表示提供给RL代理。为此,我们为每个训练时期取一个可学习的嵌入,并使用递归模型来计算变化环境的表示。我们使用解码器模型训练递归模型和嵌入,以重构观察到的奖励。这样的设计使我们的代理能够有效地利用情节性观察以及环境表示,来学习一个适当的策略,以确定CNN模型的高性能子网络。我们在CIFAR-10和ImageNet上使用ResNets和MobileNets进行的广泛实验展示了我们方法的有效性。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日