随着大语言模型(LLMs)的快速发展,基于LLM的智能体已在多个领域得到广泛应用,成为自主决策和交互任务的关键技术。然而,现有研究通常依赖于对原始LLM进行提示设计或微调的策略,这往往导致智能体在复杂环境中的效能受限或表现欠佳。尽管LLM优化技术能提升模型在通用任务中的性能,但其对智能体关键功能(如长期规划、动态环境交互和复杂决策)仍缺乏针对性优化。虽然近期大量研究探索了优化LLM智能体的多种策略,但目前仍缺乏从整体视角系统梳理和比较这些方法的综述研究。
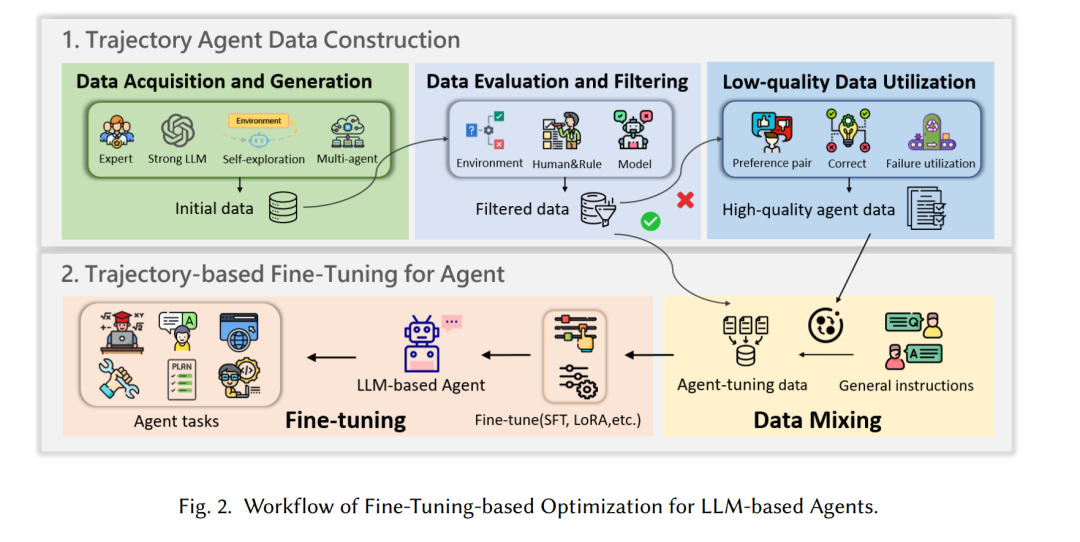
本文全面回顾了基于LLM的智能体优化方法,将其划分为参数驱动型与无参数型两大类。针对参数驱动优化,我们重点探讨了基于微调的优化、基于强化学习的优化以及混合策略,深入分析了轨迹数据构建、微调技术、奖励函数设计和优化算法等关键要素。同时简要讨论了通过提示工程和外部知识检索实现行为优化的无参数策略。最后,我们系统总结了用于评估调优的数据集与基准测试,梳理了LLM智能体的主要应用场景,并探讨了当前面临的核心挑战与未来发展方向。相关文献资源库详见:
https://github.com/YoungDubbyDu/LLM-Agent-Optimization
1 引言
自主智能体的发展一直是人工智能(AI)领域的长期追求目标。AI智能体已从早期的基于规则和专家系统的架构,演进为当前广泛应用的强化学习(RL)驱动型智能体[35]。传统RL智能体通过与环境的交互来优化策略,利用结构化奖励函数实现目标并持续提升性能。然而,这类方法通常需要大量训练、依赖明确定义的状态-动作空间,且难以实现跨任务的泛化能力。近年来,GPT-4[120]、PaLM 2[5]和Deepseek-r1[52]等大语言模型(LLMs)取得显著突破,在语言理解、推理、规划和复杂决策方面展现出卓越能力。基于这些优势,LLMs可作为智能体载体,为提升自主决策能力和实现通用人工智能(AGI)提供新路径[169]。与传统RL智能体优化显式奖励驱动的策略不同,基于LLM的智能体通过文本指令、提示模板和上下文学习(ICL)运作,具有更强的灵活性和泛化能力。这类智能体利用LLMs的理解与推理能力,通过自然语言与环境交互,执行复杂多步任务,并动态适应场景变化。现有LLM智能体采用任务分解[64]、自我反思[133]、记忆增强[210]和多智能体协作[86]等方法,在软件开发[67]、数学推理[1]、具身智能[212]、网络导航[28]等领域取得优异表现。然而,LLMs本质上并非为自主决策和长期任务设计。其训练目标聚焦于下一词元预测,而非智能体任务所需的推理、规划或交互学习,因此缺乏面向智能体任务的专门训练。这导致LLM智能体在复杂环境中面临三大挑战:1)长周期规划和多步推理能力不足,生成内容可能导致任务不一致或错误累积;2)有限记忆容量阻碍利用历史经验进行反思,影响决策质量;3)依赖预训练知识或固定上下文,适应新环境能力受限。这些局限在开源模型中尤为明显,其智能体能力显著落后于GPT-4等专有模型。此外,闭源模型的高成本与低透明度,凸显了优化开源LLM以提升智能体能力的必要性。现有技术如监督微调(SFT)[122]和人类反馈强化学习(RLHF)[121]虽在指令跟随任务中取得进展,但未能完全解决LLM智能体的决策、长期规划和适应性问题。优化LLM智能体需要更深入理解动态环境和智能体行为,开发超越传统微调与提示工程的专门技术。为此,近期研究探索了多种优化策略,使智能体能够跨环境泛化、基于反馈调整策略,并高效利用工具、记忆和检索机制等外部资源。
本文首次对LLM智能体优化研究进行系统综述,将方法划分为参数驱动型与无参数型优化策略。参数驱动型优化通过调整LLM参数提升性能, 包括:基于微调的方法(涵盖轨迹数据构建和微调策略等关键环节);基于RL的方法(分为采用Actor-Critic[147]、PPO[136]等传统RL技术的奖励函数优化,以及利用直接偏好优化(DPO)[132]实现策略与人类偏好对齐的方法);以及结合SFT与RL的混合优化策略。无参数型优化则通过提示工程、上下文学习和检索增强生成(RAG)等技术改进智能体行为,具体分为反馈驱动型、经验驱动型、工具增强型、检索增强型和多智能体协作型优化。与现有综述的差异:尽管LLM智能体研究日益活跃,但现有综述或聚焦通用LLM优化,或仅讨论规划、记忆等特定能力,未将LLM智能体优化作为独立研究领域。LLM优化综述多关注微调[115,122]和自我进化方法[150],缺乏对智能体专用优化的探讨;而智能体综述通常按架构组件(如规划[64]、记忆[210])分类,未系统总结优化行为与性能的技术。相较之下,本文是首个专注于LLM智能体优化技术的综述,为方法比较和未来研究提供清晰框架。研究范围:1)仅涵盖提升问题解决、决策等任务性能的LLM智能体优化算法;2)选录AI/NLP顶会期刊论文及arXiv高影响力预印本;3)聚焦2022年后的最新进展。全文结构:第2节介绍背景知识;第3节系统分析参数驱动型优化(含微调优化、RL优化和混合优化);第4节分类阐述无参数型优化;第5-6节总结评估数据集与应用场景;第7节展望挑战与未来方向。