

Transformer模型在各类人工智能领域取得了显著进展,包括自然语言处理、计算机视觉和音频处理。这一成功自然引起了学术界和工业界研究人员的广泛关注。因此,许多Transformer变体(通常称为X-former)被开发用于这些领域。然而,针对这些特定模态转换的全面而系统的审查仍然缺乏。模态转换涉及将数据从一种表示形式转化为另一种形式,模仿人类整合和解释感官信息的方式。本文对应用于文本、视觉和语音等主要模态的基于Transformer模型进行了全面回顾,讨论了它们的架构、转换方法和应用。通过综合模态转换领域的文献,这篇综述旨在强调Transformer在推动AI驱动的内容生成和理解中的多样性和可扩展性。
人工智能(AI)受人类感知能力的启发,例如视觉、听觉和阅读,并试图复制这些能力。通常,模态与特定的传感器相关联,形成一个独特的通信通道,如视力、语音和书面语言。人类在感官感知中具有一种基本过程,能够通过整合来自多个感官模态的数据,在动态和不受约束的情况下高效地与世界互动。每个模态作为信息的独立来源,具有其独特的统计特征。例如,一张描绘“大象在水中嬉戏”的照片通过无数像素传递视觉信息,而类似的文字描述则使用不同的词语来传达这一场景。同样,声音可以通过频谱图或语音特征来传达相同的事件。数据转换AI系统必须接收来自特定模态的输入,处理、理解并以不同的模态再现其内容,模仿人类的感知方式。模态转换(MC)是一种广泛的方法,用于构建能够从一种表示模态中提取并转换信息到另一种模态的人工智能模型。
基于Transformer的(TB)技术通过利用其先进的注意力机制,准确地表示和转换各种形式的输入,极大地改变了数据从一种模态转换到另一种模态的过程。这些模型在将文本转换为语音、语音转换为文本、语音转换为图像、图像转换为文本,甚至跨模态翻译(如从文本生成图像)等任务中表现出色。Transformer通过捕捉各种数据模态间的复杂依赖关系和上下文交互,促进了顺畅且高度精确的转换。由于其适应性和可扩展性,它们在扩展自然语言处理、计算机视觉和多模态数据集成的应用中起到了关键作用,推动了AI驱动的内容生产和理解的进步。
• 相关综述:许多综述已经探讨了基于Transformer(TB)模型在文本处理、计算机视觉和语音处理领域的应用。这些综述通常回顾了专注于单一模态的研究论文,处理输入数据以生成特定应用所需的输出。同时,还有一些关于数据融合的综述,旨在整合来自不同模态的数据。这些论文通常回顾了各种类型的融合模型和输入类型,如文本、视觉和语音。例如,Davis等人关于使用Transformer进行多模态学习的综述探讨了多种模态协同使用的情况,展示了在需要从多种数据源中获得全面理解的任务中所取得的显著改进。总的来说,目前还没有一篇综述全面回顾不同模态(文本、视觉和语音)间的数据转换相关的文献。
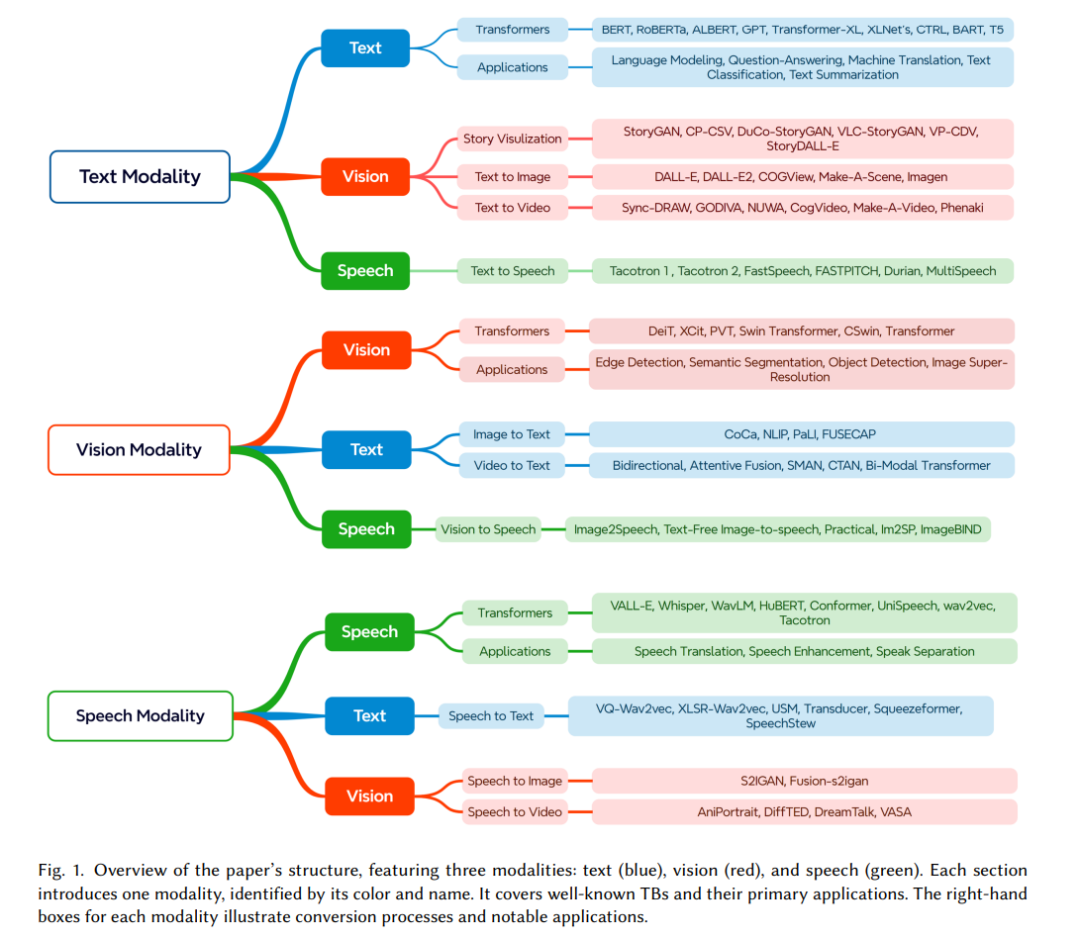
•** 论文贡献**:在本文中,我们对用于数据模态转换的基于Transformer的模型进行了全面回顾。我们重点关注三个主要模态:文本、视觉和语音。对于每个Transformer模型,输入可以是这些模态中的任何一种,而输出可以是相同或不同的模态。例如,给定文本输入,输出可以是翻译后的文本(机器翻译)、图像(故事可视化)或语音。同样,对于视觉和语音输入,输出也可以转换为其他任一模态。我们系统地回顾了所有使用基于Transformer模型进行模态转换的相关文献(见图1)。
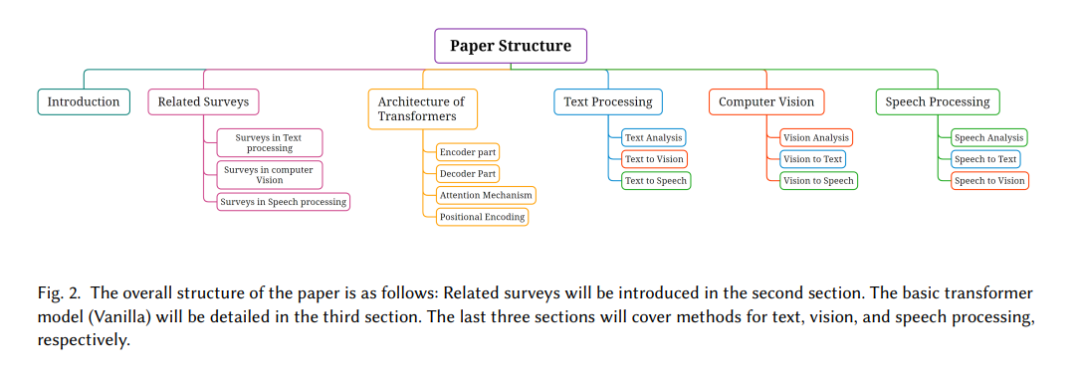
•** 范围**:我们的综述限制在2017年至2024年间发表的论文,因为Transformer技术是Vaswani等人在2017年提出的,相对较新。聚焦于这一时期使我们能够包含与模态表示和转换相关的最新和最相关的Transformer进展。引用分析显示,从2017年到2024年,共有95种方法,其中在2020年至2024年间的兴趣达到了高峰。本综述旨在通过整合这些领域中最先进的Transformer模型,为研究人员和实践者提供服务。 本综述的其余部分结构如下:第二部分汇集了所有关于TB模型的相关综述。第三部分介绍了Transformer的架构和关键组件。第四、五、六部分分别回顾了以文本、视觉和语音为输入的TB模型,其输出可以是这三种模态中的任何一种。第七部分讨论了Transformer的其他可能引起研究人员兴趣的方面,并总结了本文的内容。


