文本生成已经变得比以往任何时候都更容易接触,并且对这些系统,特别是使用大型语言模型的系统的兴趣日益增加,这也促使了相关出版物数量的不断增加。我们提供了一份系统文献综述,涵盖了2017年至2024年间精选的244篇论文。该综述将文本生成的研究工作分为五个主要任务:开放式文本生成、摘要、翻译、改写和问答。对于每个任务,我们回顾了其相关特性、子任务和具体挑战(例如,多文档摘要的缺失数据集、故事生成中的连贯性以及问答中的复杂推理)。此外,我们评估了当前用于评估文本生成系统的方法,并确定了现有指标的问题。我们的研究表明,最近文本生成出版物中所有任务和子任务普遍存在的九个主要挑战:偏见、推理、幻觉、误用、隐私、可解释性、透明度、数据集和计算。我们对这些挑战、潜在解决方案以及仍需社区进一步参与的空白进行了详细分析。该系统文献综述面向两个主要受众:希望了解该领域概况和有前景的研究方向的初级自然语言处理研究人员,以及寻求任务、评估方法、开放挑战和最新缓解策略的详细视图的资深研究人员。
当模型具备了对自然语言进行建模的能力,特别是使用大型语言模型生成与人类写作水平相当的文本时,AI领域取得了重大突破【38, 186, 197】。结合先进的深度学习架构、大规模数据和日益廉价的计算基础设施,这揭示了大规模训练AI助手的新范式。现在,任何人只要能够访问互联网,就可以拥有自己的AI助手,以自动化诸如起草电子邮件、填写表格或开发软件等繁琐且耗时的任务。虽然这种乌托邦式的情景会让大多数人感到意外,但这不过是多年来来自AI、工程、统计、语言学和自然语言处理(NLP)等领域的研究人员和实践者之间不断、协作和逐步努力的结果。
从早期的分布式语义学【71】、基于规则的问答系统【130】、第一个神经概率语言模型(LM)【16】到GPT-4【3】、LLaMA【185】和Gemini【182】,NLP一直是推动AI快速进步的关键角色。如今,语言模型以文本到文本的方式解决问题,以可信且令人信服的自然语言进行接收和回应。这种问题解决方法的灵感来自于人类通过将答案表述为一系列具有特定意义的词来解决各种问题的方式,这一过程被称为文本生成。一般而言,文本生成是创建自然语言文本的过程。在文本生成的早期阶段,模型会使用结构化数据、语法规则和模板来构建文本【130, 209】。如今,大多数方法使用神经网络来估计词序列中下一个词的概率【16】。
文本生成解决方案高度多样且强大,能够执行多种任务,例如生成故事【19】或执行类似人类的推理【99】。广泛的应用范围和显著的研究与开发兴趣使得那些参与资金、研究和产品开发的人们对其全面理解有所减弱,这些人直接或间接地影响社会。对提出的研究模型、任务、数据集和开放挑战的持续反思和评估是实现可持续发展和负责任地造福人类的方法的关键。因此,系统文献综述和综述对于根据特殊兴趣浓缩和组织现有相关工作,回顾性地讨论这些机会和风险,并为未来研究提出建议至关重要。
在本文中,我们概述了2017年1月至2023年8月期间的最新文本生成研究,因为它渗透了NLP中与文本生产相关的大多数活动(例如翻译【92】、摘要【108】)。我们的系统文献综述主要关注三个方面:任务和子任务(第3节)、评估指标(第4节)和挑战(第5节)。具体而言,我们提出了以下关键问题来组织我们的研究:
1. 什么构成了文本生成任务?主要的子任务是什么?
2. 如何评估文本生成系统?其伴随的局限性是什么?
3. 文本生成中有哪些开放挑战?
4. 文本生成中的重要研究方向是什么?
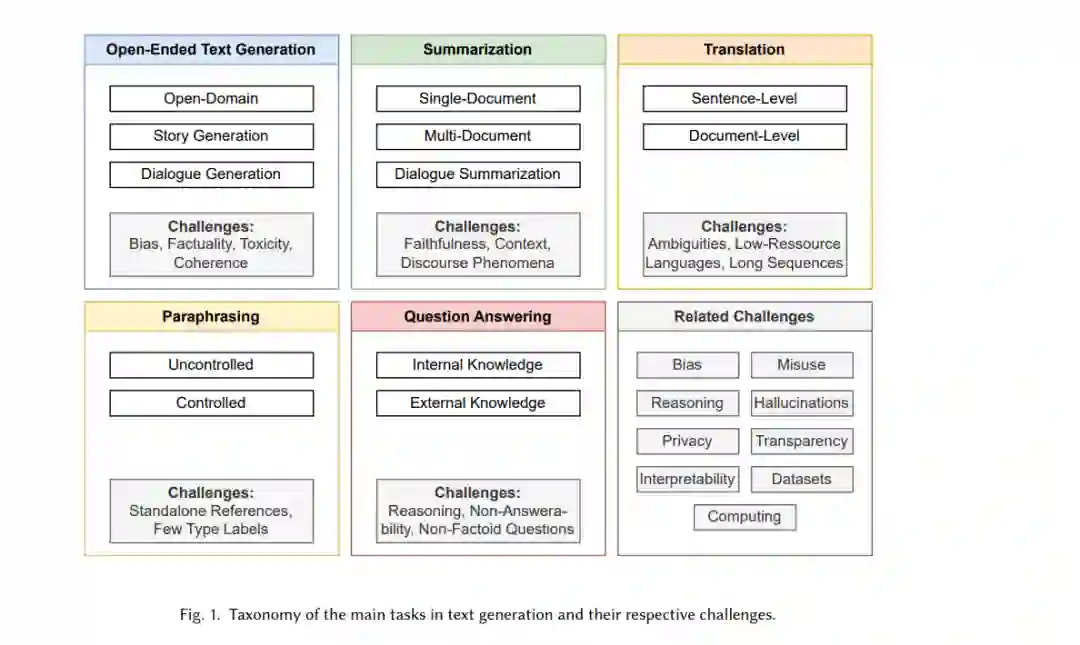
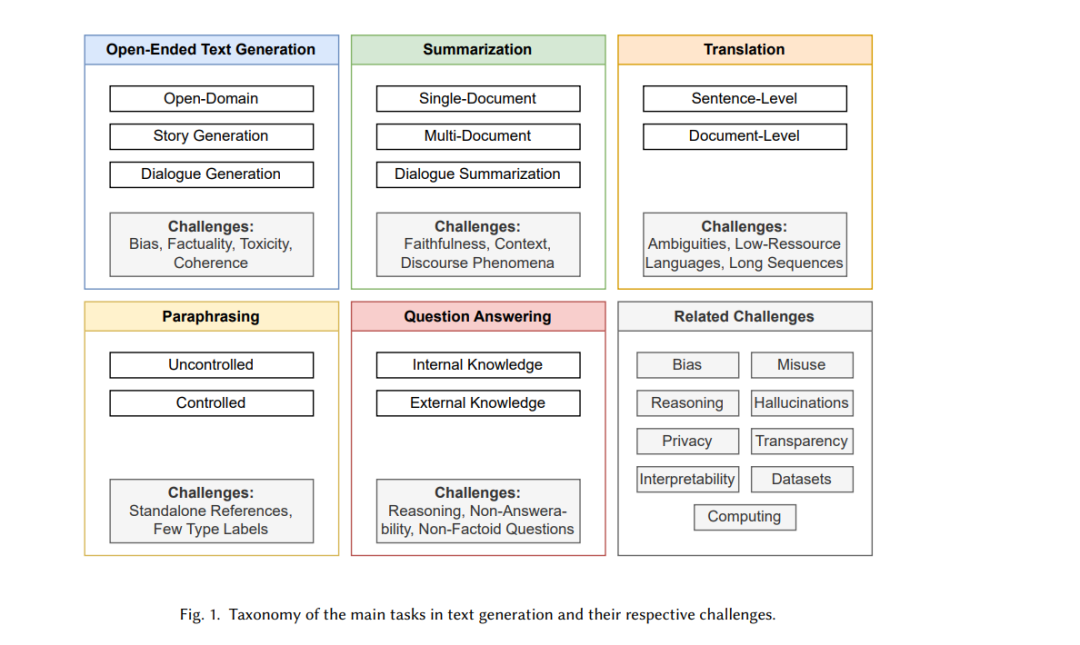
图1概述了文本生成中最突出的任务及相关挑战。我们确定了五个主要任务:开放式文本生成、摘要、翻译、改写和问答(第3节)。对于每个任务,我们回顾了其相关特性、子任务和具体挑战。接下来,我们评估了该领域中常用的评估方法(即无模型和基于模型的指标),并讨论了它们的局限性(第4节)。此外,我们还识别了最近文本生成出版物中所有任务和子任务共有的九个突出挑战:偏见、推理、幻觉、误用、隐私、可解释性、透明度、数据集和计算(第5节)。最后,我们重新审视、总结并回答了我们的研究问题(第6节)。为了重现性,我们公开分享我们方法的详细信息(例如,关键词、主观决策、排除标准、代码)以及在开放获取仓库中所考虑出版物的元数据。