

扩散模型已经成为一种突出的生成模型,在样本质量和训练稳定性方面超过了之前的方法。最近的工作显示了扩散模型在改进强化学习(RL)解决方案方面的优势,包括作为轨迹规划器、表达性策略类、数据合成器等。本综述旨在概述这一新兴领域的进展,并希望激发新的研究途径。首先,研究了当前强化学习算法遇到的几个挑战。根据扩散模型在强化学习中发挥的作用,对现有方法进行了分类,并探索了如何解决现有挑战。进一步概述了扩散模型在各种强化学习相关任务中的成功应用,同时讨论了当前方法的局限性。最后,总结了综述,并对未来的研究方向提出了见解,重点是提高模型性能和将扩散模型应用于更广泛的任务。我们正在积极维护一个GitHub存储库,用于存储在RL中应用扩散模型的论文和其他相关资源。
https://www.zhuanzhi.ai/paper/5b2f904982b924f5734c5543cb19945c
扩散模型已成为一类强大的生成模型,近年来引起了广泛关注。这些模型采用了一种去噪框架,可以有效地逆转多步去噪过程以生成新数据[Song等人,2021]。与早期的生成模型如变分自编码器(VAE) [Kingma和Welling, 2013]和生成对抗网络(GAN) [Goodfellow等人,2014]相比,扩散模型在生成高质量样本方面表现出优越的能力,并显示出增强的训练稳定性。因此,他们在包括计算机视觉在内的不同领域取得了显著的进步并取得了实质性的成功[Ho等人,2020;Lugmayr等人,2022;,自然语言处理[Austin等人,2021;Li等人,2022],音频生成[Lee和Han, 2021;Kong等人,2020]和药物发现[Xu等人,2022;Schneuing等人,2022]等。
强化学习(RL) [Sutton和Barto, 2018]专注于通过最大化累积奖励来训练智能体来解决连续决策任务。虽然RL在各个领域取得了显著的成功[Kober等人,2013;Kiran等人,2021],有一些长期的挑战。具体来说,尽管离线强化学习因克服在线强化学习中的低样本效率问题而获得了相当大的关注[Kumar等人,2020;Fujimoto and Gu, 2021],传统的高斯策略可能无法拟合具有复杂分布的数据集,因为它们的表达能力有限。同时,虽然利用经验回放来提高样本效率[Mnih et al., 2013],但在高维状态空间和复杂交互模式的环境中仍然存在数据稀缺问题。在基于模型的强化学习中,学习到的动态模型的一个常见用法是规划[Nagabandi等人,2018;Schrittwieser等人,2020;Zhu et al., 2021],但perstep自回归规划方法受到复合误差问题的影响[Xiao et al., 2019]。一个理想的强化学习算法应该能够学习单个策略来执行多个任务,并泛化到新环境中[Vithayathil Varghese和Mahmoud, 2020;Beck等,2023]。然而,现有工作在多任务泛化方面仍然很困难。
近年来,已有一系列将扩散模型应用于序列决策任务的研究,其中尤以离线决策学习为著。作为一项代表性工作,Diffuser [Janner等人,2022]拟合了用于离线数据集上轨迹生成的扩散模型,并通过引导采样规划所需的未来轨迹。已经有许多后续工作,其中扩散模型在强化学习管道中表现为不同的模块,例如取代传统的高斯策略[Wang等人,2023],增强经验数据集[Lu等人,2023b],提取潜在技能[Venkatraman等人,2023]等。我们还观察到,由扩散模型促进的规划和决策算法在更广泛的应用中表现良好,如多任务强化学习[He等人,2023a]、模仿学习[Hegde等人,2023]和轨迹生成[Zhang等人,2022]。更重要的是,扩散模型由于其强大而灵活的分布建模能力,已经为解决强化学习中长期存在的挑战提供了思路。
本文关注于扩散模型在强化学习中的应用,并额外考虑了将扩散模型纳入轨迹生成和模仿学习背景中的方法,主要是因为这些领域之间存在明显的相互关系。第2节阐述了上述RL挑战,并讨论了扩散模型如何帮助解决每个挑战。第3节提供了扩散模型基础的背景知识,还涵盖了在强化学习相关应用中特别重要的两类方法:引导采样和快速采样。第4节说明了扩散模型在强化学习中在现有工作中发挥的作用。第5节讨论了扩散模型在不同RL相关应用中的贡献。在第6节中,指出了应用扩散模型时的局限性,并将其与基于transformer的方法进行了比较。第7节总结了调查与讨论新兴的新主题。
扩散模型的基础
本节提供扩散模型的基础。提出了两个著名的表述:去噪扩散概率模型(DDPM) [Ho等人,2020]和基于分数的生成模型[Song等人,2021]。DDPM由于其简单性而被广泛使用,而基于分数的公式将其扩展到包含连续时间扩散过程。此外,引导采样方法在将扩散模型集成到RL框架中起着关键作用。根据指导采样过程的方法,这些方法可以分为两大类:分类器指导[Dhariwal和Nichol, 2021],这需要一个额外的分类器,以及无分类器指导[Ho和Salimans, 2022],这将指导条件作为模型输入的一部分。此外,为了提高采样速度,特别是在在线交互过程中,在强化学习相关任务中使用扩散模型时采用了快速采样技术[Kang等人,2023;王志军,2023。简要介绍了在扩散模型的禁食采样研究方面的一些代表性工作,包括基于学习的方法和无学习的方法。
**在RL中扩散模型的角色 **
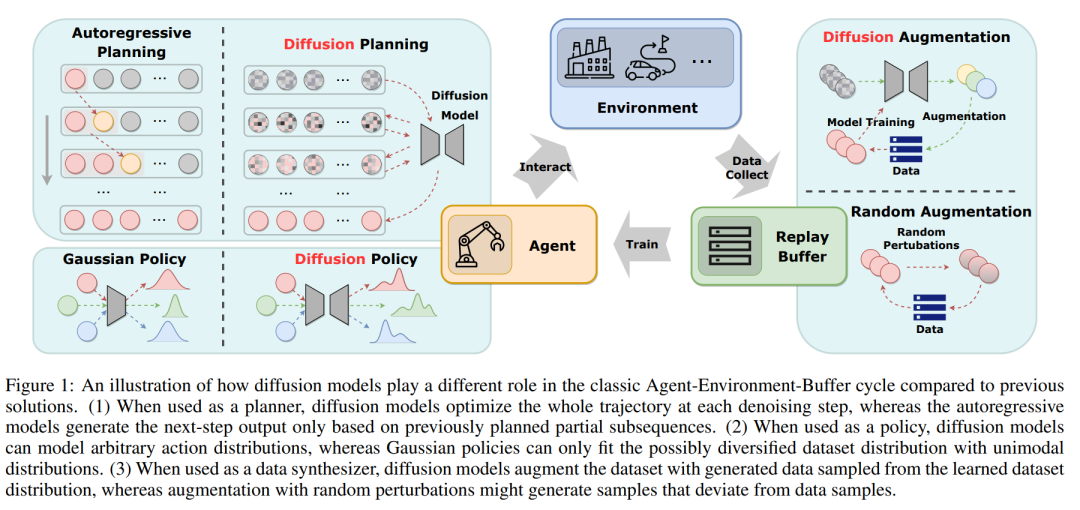
扩散模型已证明了其生成多样化数据和建模多模态分布的能力。考虑到第2节中介绍的长期存在的挑战,使用扩散模型改善RL算法的性能和样本效率是足够的。在图1中,我们说明了扩散模型在RL中与以前的解决方案相比扮演的不同角色。当前应用扩散模型于RL的工作主要分为四个类别:使用扩散模型作为规划器,作为策略,用于数据增强,以及在潜在表示上。以下小节将为每个类别说明整体框架和代表性的论文。
规划器
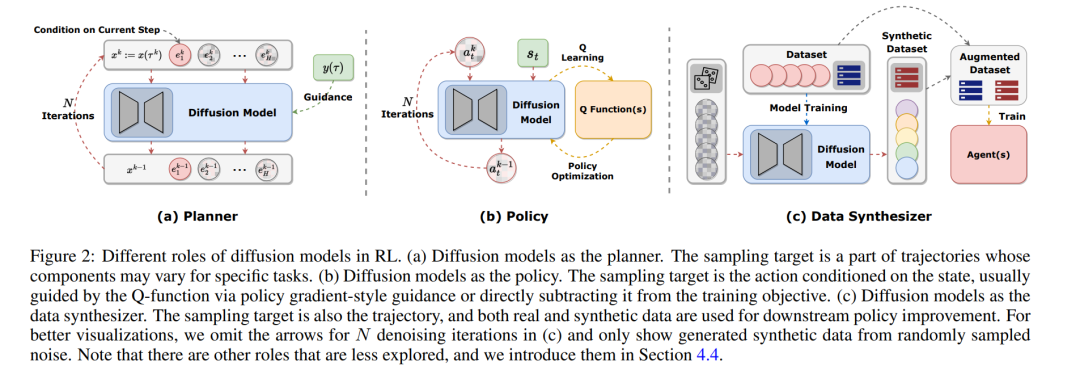
在RL中的规划指的是在一个假想的环境中决策应采取的行动的过程,然后选择最佳行动以最大化累积奖励信号。这个过程通常模拟或探索不同的行动和状态序列,预测其决策的结果,从而从更长时间范围的角度产生更好的行动。因此,规划通常应用于MBRL框架中。然而,用于规划的决策序列是自回归生成的,这可能导致严重的累积误差,尤其是在离线设置中,由于数据支持有限。扩散模型提供了一个可能的解决方案,因为它们可以同时生成整个序列。扩散模型作为规划器的一般框架显示在图2(a)中。
策略
与传统的RL分类相比,传统分类大致将RL算法分为MBRL和无模型RL,使用扩散模型作为规划器类似于MBRL,并专注于捕捉环境动态。相反,将扩散模型视为策略遵循无模型RL的框架。第2.1节阐述了离线策略学习框架的主要缺点:过于保守和在多样化数据集上的能力较差。凭借其对多模态分布的出色表达能力,许多工作利用扩散模型作为策略来解决这些问题。
**数据合成器 **
除了适应多模态分布外,扩散模型的一个简单且常见的用途是生成更多的训练样本,这在计算机视觉中得到了广泛应用并得到了验证。因此,将扩散模型作为RL数据集上的数据合成器是自然的,因为如第2.2节所述,数据稀缺是RL的实际挑战。为了保证合成数据与环境动态的一致性,RL中的先前数据增强方法通常在现有状态和动作中添加小的扰动 [Sinha等,2021]。相比之下,图2(c)说明扩散模型从整个数据集D学习数据分布,并能在保持一致性的同时生成高度多样化的数据。Lu等[2023b]研究了扩散模型作为数据合成器在离线和在线设置中的能力。它直接从离线数据集或在线回放缓冲区训练扩散模型,然后生成更多的样本以改进策略。分析显示,扩散模型生成的数据质量在多样性和准确性上高于明确数据增强生成的数据。有了合成数据,离线策略的性能和在线策略的样本效率都得到了显著提高。He等[2023a]部署扩散模型来增强多任务离线数据集的数据,并获得了比单任务数据集更好的性能。它声称在多个任务上进行拟合可能会实现任务之间的隐式知识共享,这也受益于扩散模型的多模态特性。
结论
本综述提供了一个全面的概述,关于扩散模型在RL领域的应用的现代研究努力。根据扩散模型所扮演的角色,我们将现有的方法分类为使用扩散模型作为规划器、策略、数据合成器,以及其他不太受欢迎的角色,如价值函数、潜在表示模型等。通过与传统解决方案进行比较,我们可以看到扩散模型是如何解决RL中一些长期存在的挑战,即,受限的表达性、数据稀缺、累积误差和多任务泛化。尽管有这些优点,但必须承认在RL中使用扩散模型存在不容忽视的局限性,这是由于扩散模型的训练和采样中的一些固有属性。值得强调的是,将扩散模型融入RL仍然是一个新兴领域,还有很多研究课题值得探索。在这里,我们概述了四个前景研究方向,即结合Transformer、增强生成的检索、整合安全约束和组合不同的技能。

