
来自MIT等最新《可解释AI: 深度神经网络内部结构解释》综述论文, (1)为现有的内在可解释性方法提供一个全面的参考资源,(2)为持续的、以安全为重点的研究提供指导方向。

在过去的十年里,机器学习的规模和能力都有了巨大的增长,深度神经网络(DNNs)正在越来越多地应用于广泛的领域。然而,DNN的内部工作原理通常很难理解,这引起了人们对使用这些系统的安全性的担忧,因为他们没有严格了解它们的功能。在这项综述中,我们回顾了解释DNN内部成分的技术,我们称之为内部可解释方法。具体而言,我们回顾了解释权重、神经元、子网和潜在表示的方法,重点关注这些技术如何与设计更安全、更值得信赖的AI系统的目标相关联。我们还强调了可解释性与模块化、对抗鲁棒性、持续学习、网络压缩和人类视觉系统研究之间的联系。最后,我们讨论了关键的挑战,并讨论了未来在人工智能安全可解释性方面的工作,重点是诊断、基准测试和鲁棒性。
https://www.zhuanzhi.ai/paper/c6db46946cd96a10ab425120dacad09a
过去十年深度学习的一个显著特征是规模和能力的急剧增长[124],[228],从2010年到2022年,机器学习系统的训练计算增长了100亿倍[227]。与此同时,深度神经网络(DNNs)越来越多地用于安全、可预测的行为至关重要的环境中。如果继续快速发展,自动化的宽领域智能有可能对社会产生高度影响[33],[51],[179],[195],[210],[239]。考虑到这些发展,从业者能够理解AI系统如何做出决策,特别是它们的失败模式是至关重要的。人工智能系统最典型的评估标准是它们在特定任务测试集上的表现。这引起了关注,因为在测试集中表现良好的黑盒并不意味着学习到的解决方案就足够了。例如,部署分布可能不同于测试分布,并且/或者任务目标的规范可能导致意外行为(例如[135],[147])。即使用户意识到不足之处,系统的黑盒特性也会使修复缺陷变得困难。因此,建立安全可靠的人工智能系统的一个重要步骤是拥有检测和解决这些缺陷的技术。为此,拥有一套多样的严格解释AI系统的技术将是有价值的(见I-A)。
我们将可解释性方法定义为可以用人类可以理解的术语描述系统行为的任何过程。这包含了DNN文献中广泛的技术,所以在本文中,我们特别关注对理解内部结构和表示有用的方法。我们称之为内部可解释方法。我们讨论了这些方法的分类,提供了文献综述,讨论了可解释性和深度学习中的其他主题之间的关键联系,并总结了继续工作的方向。我们的中心目标有两方面: (1)为现有的内在可解释性方法提供一个全面的参考资源,(2)为持续的、以安全为重点的研究提供指导方向。
可解释性技术的一个主要动机是理解模型的潜在问题。因此,可解释性方法将与构建更安全、更值得信赖的人工智能系统高度相关。
可解释性技术应通过其产生新颖、有效和可操作见解的能力来评估。这可能是困难的,而且在文献中评估常常做得很差。需要严格的测试和基准来评估解释,应该包括重新发现DNN的已知缺陷。
可解释性、模块化、对抗鲁棒性、持续学习、网络压缩和与人类视觉系统的相似性之间有许多丰富的联系。
未来工作的引人注目的方向包括使用人类输入的可扩展方法、逆向工程系统、检测潜在知识、基准测试和研究技术之间的交互。
可解释性对更安全人工智能的重要性
对于AI系统来说,它们需要正确的目标,并且需要有效地优化这些目标。主要是第二个需求,可解释性技术为构建更值得信赖的AI提供了优势[115],[180]。我们在此概述主要动机。
展示失败: 揭示为什么一个模型不能产生正确的输出,让研究人员能够洞察失败是什么样子的,以及如何检测它们。这些信息可以帮助研究人员避免这些问题,并帮助监管机构为部署的系统建立适当的规则。
修复bug:通过理解故障和/或生成利用它的例子,可以重新设计、微调和/或对抗性训练网络,使其更好地与用户的目标保持一致。
提高基本理解: 通过向用户提供更多关于DNN如何学习的知识,可解释性技术可以开发改进的模型或更好地预测人工智能的进展。
确定责任:具有描述失败的能力对于在误用或部署失败的情况下确定责任是至关重要的。
“显微镜式”AI: 严格理解AI系统如何完成任务可以提供额外的领域知识。这一目标被称为“显微镜”AI[115],它可以允许对更容易理解的模型进行逆向工程。这对于研究在某些领域具有超人性能的系统尤其有价值。
对于实现上述目标的可解释性技术,它们应该满足某些需求。
准确性-验证,而不是说服: 可解释性技术应该给出模型正在执行的计算的正确图像,而不仅仅是看似合理地这样做。给用户错误的安全感是非常有害的。一个常见的例子是输入归因方法,它经常对模型[4]的决策提供误导性的解释[64]。此外,解释应该伴随着不确定性估计。
人类的可理解性: 另一方面,由可解释技术产生的解释应该易于人类理解。从某种意义上说,对模型最准确的“解释”就是返回它的参数,但这对人类来说几乎总是难以理解的。因此,准确性应该与可理解性相平衡。
深度: 内部可解释性技术的“深度”指的是它解释复杂子流程的能力。很可能DNN中的某些特征或计算比其他特征更容易被人类自然理解,这就增加了对模型理解过于简单的可能性。解释不应该偏向于模型中容易解释的部分。
泛化性: 解释应该能够概括到不同的例子。这可以让他们帮助诊断发生在训练/验证分发之外的故障。
竞争力 :可解释性技术不应导致竞争力的显著下降,如性能下降、计算需求增加或难以在现代深度学习框架中使用。竞争缺陷也可能导致“价值侵蚀”,即不采用更安全的人工智能实践,而采用更具竞争力的模型。
产生可操作的见解:可解释性方法的最终目标应该是产生有用的见解。关键是解释可以用来对模型做出和验证可测试的预测。有两种方法可以做到这一点:使用解释来指导新的对手的设计,或者手动微调模型来诱导可预测的变化。这与准确性密切相关;可解释性方法的结果应该能够明确地洞察模型的行为。在第VI节中,我们讨论了可操作的见解的重要性,以及现有的工作如何典型地无法证明它们。
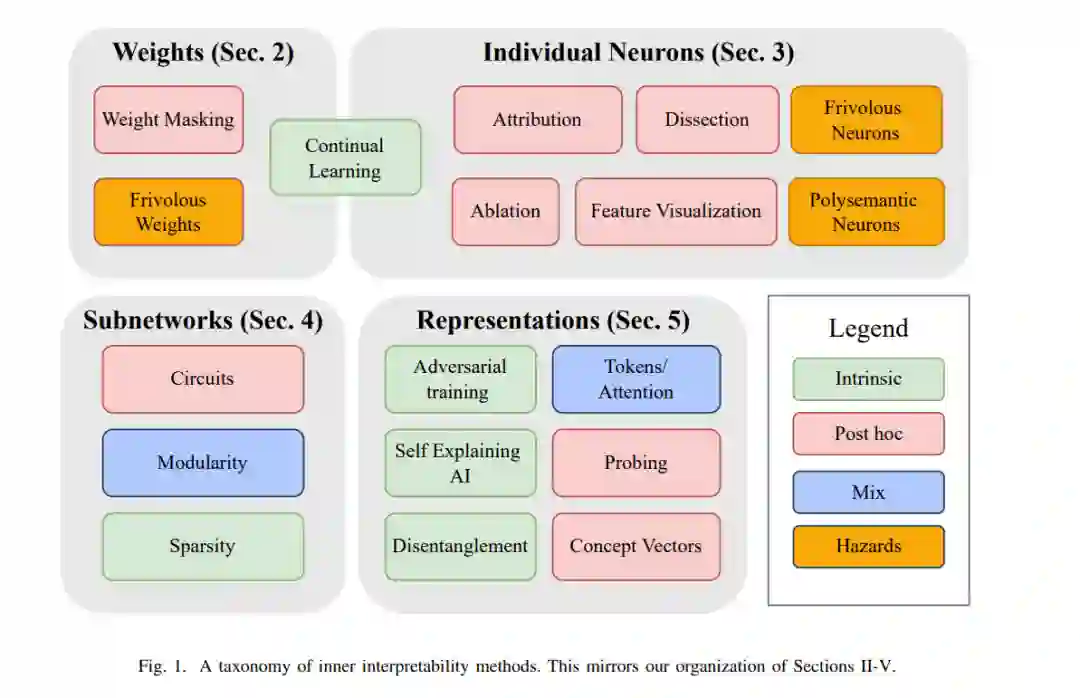
我们的重点是DNN的内部可解释性方法。值得注意的是,模型无关技术、黑箱技术、输入归因方法、神经符号方法和“优秀的老式AI”超出了本次综述的范围。这并不是说它们在构建安全人工智能方面的价值低于我们所关注的方法——我们相信多样化的技术是至关重要的。然而,我们专注于内部可解释性方法(1),因为该综述的可跟踪范围,(2) 因为它们对某些目标(如理解如何修改模型、反向工程解决方案,以及检测通常不会出现在系统部署行为中的潜在知识)有很好的装备。也请参阅之前对可解释性工作的一些调查和评论,它们与我们的[3],[58],[60],[68],[95],[118],[136],[173]-[175],[208],[215],[218],[219]有重叠。然而,这项综述的不同之处在于其对内部可解释性、人工智能安全以及可解释性和其他几个研究范式之间的交叉的关注。参见我们在第VI节的讨论。在接下来的章节中,我们根据DNN的计算图解释的部分来组织我们对技术的讨论: 权重、神经元、电路或表示。图1描述了内部方法是如何这样组织的。除了这种分解,可解释性技术还可以按照它们是在模型训练期间使用还是在模型训练之后使用来划分。内在可解释性技术包括训练模型,使其更容易学习或具有自然的解释。Post hoc技术的目的是在模型经过训练后对其进行解释。我们在分段层次上根据方法是内在的还是事后的来划分方法。这两种方法并不相互排斥。




