通过人工神经网络等获得的预测具有很高的准确性,但人类经常将这些模型视为黑盒子。对于人类来说,关于决策制定的洞察大多是不透明的。在医疗保健或金融等高度敏感领域,对决策的理解至关重要。黑盒子背后的决策要求它对人类来说更加透明、可问责和可理解。这篇综述论文提供了基本的定义,概述了可解释监督机器学习(SML)的不同原理和方法。我们进行了最先进的综述,回顾过去和最近可解释的SML方法,并根据介绍的定义对它们进行分类。最后,我们通过一个解释性的案例研究来说明原则,并讨论未来的重要方向。
https://www.zhuanzhi.ai/paper/d34a1111c1ab9ea312570ae8e011903c
目前人工智能(AI)模型的准确性是显著的,但准确性并不是最重要的唯一方面。对于高风险的领域,对模型和输出的详细理解也很重要。底层的机器学习和深度学习算法构建的复杂模型对人类来说是不透明的。Holzinger等人(2019b)指出,医学领域是人工智能面临的最大挑战之一。对于像医疗这样的领域,深刻理解人工智能的应用是至关重要的,对可解释人工智能(XAI)的需求是显而易见的。
可解释性在许多领域很重要,但不是在所有领域。我们已经提到了可解释性很重要的领域,例如卫生保健。在其他领域,比如飞机碰撞避免,算法多年来一直在没有人工交互的情况下运行,也没有给出解释。当存在某种程度的不完整时,需要可解释性。可以肯定的是,不完整性不能与不确定性混淆。不确定性指的是可以通过数学模型形式化和处理的东西。另一方面,不完全性意味着关于问题的某些东西不能充分编码到模型中(Doshi-Velez和Kim(2017))。例如,刑事风险评估工具应该是公正的,它也应该符合人类的公平和道德观念。但伦理学是一个很宽泛的领域,它是主观的,很难正式化。相比之下,飞机避免碰撞是一个很容易理解的问题,也可以被精确地描述。如果一个系统能够很好地避免碰撞,就不用再担心它了。不需要解释。
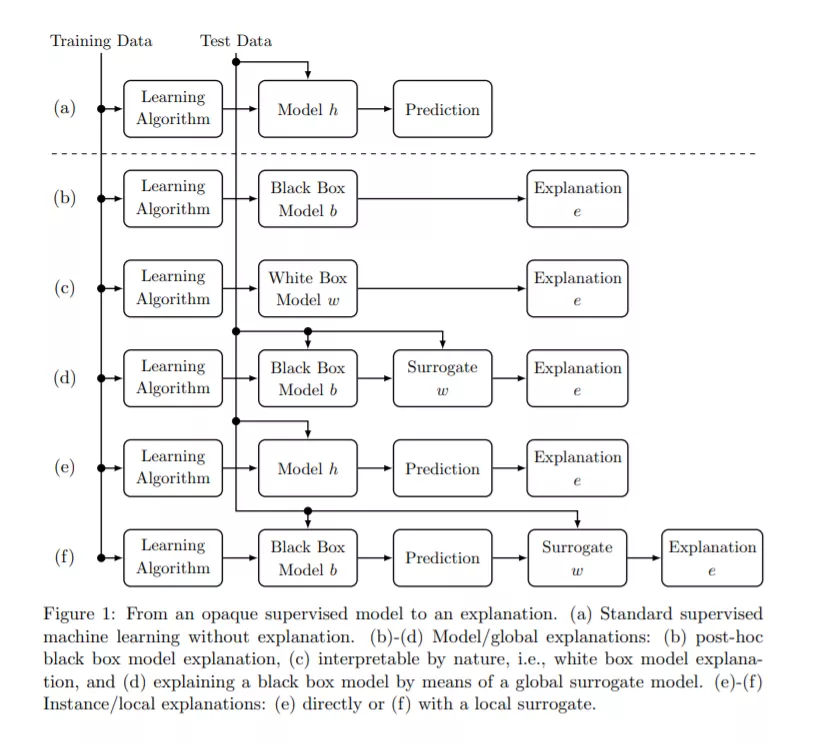
本文详细介绍了可解释SML的定义,并为该领域中各种方法的分类奠定了基础。我们区分了各种问题定义,将可解释监督学习领域分为可解释模型、代理模型拟合和解释生成。可解释模型的定义关注于自然实现的或通过使用设计原则强制实现的整个模型理解。代理模型拟合方法近似基于黑盒的局部或全局可解释模型。解释生成过程直接产生一种解释,区分局部解释和全局解释。
综上所述,本文的贡献如下:
- 对五种不同的解释方法进行形式化,并对整个解释链的相应文献(分类和回归)进行回顾。
- 可解释性的原因,审查重要领域和可解释性的评估
- 这一章仅仅强调了围绕数据和可解释性主题的各个方面,比如数据质量和本体
- 支持理解不同解释方法的连续用例
- 回顾重要的未来方向和讨论