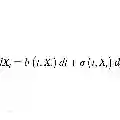摘要——扩散模型(Diffusion Models, DMs)在图像生成、文本生成图像、文本引导图像生成等多种生成任务中已取得了最先进的性能。然而,DMs越强大,它们潜在的危害也越大。最近的研究表明,DMs容易受到各种攻击,包括对抗性攻击、成员推理、后门注入以及各种多模态威胁。由于众多预训练的DMs在互联网上广泛发布,这些攻击带来的潜在威胁对社会尤其具有危害性,使得与DM相关的安全问题成为一个值得深入研究的课题。因此,在本文中,我们对DMs的安全性进行了全面的综述,重点关注针对DMs的各种攻击和防御方法。首先,我们介绍了DMs的关键知识,包括五种主要类型的DMs:去噪扩散概率模型、去噪扩散隐式模型、噪声条件评分网络、随机微分方程以及多模态条件DMs。我们进一步综述了最近一系列研究,探讨了利用DMs脆弱性的不同类型的攻击。随后,我们全面回顾了用于减轻每种威胁的潜在对策。最后,我们讨论了与DMs相关的安全性面临的开放性挑战,并展望了这一重要领域的研究方向。
关键词——扩散模型,多模态威胁,扩散模型安全性,后门攻击,成员推理,对抗性攻击。

近年来,扩散模型(Diffusion Models, DMs)[1]–[11]在广泛的生成任务中展示了卓越的能力,在深度生成模型的其他类别中如生成对抗网络(GANs)[12]、变分自编码器(VAEs)[13], [14]和基于能量的模型(EBMs)[15]中树立了新的性能标杆。通常,DMs包括两个主要过程。前向(扩散)过程逐渐向原始数据中添加噪声,以逐步将数据分布扩散到标准高斯分布中。反向(生成)过程利用一个深度神经网络(通常是UNet [16]),来反向扩散,从高斯噪声中重构数据。凭借其令人印象深刻的潜力,DMs已被广泛应用于多个领域,包括计算机视觉 [17]–[28]、自然语言处理(NLP)[29]–[34]、音频处理 [35], [36]、3D生成 [37]–[42]、生物信息学 [43], [44]以及时间序列任务 [45]–[47]。根据扩散和生成过程的不同,DMs可以分为不同的类别。第一类受到非平衡热力学理论[1]的启发,包括去噪扩散概率模型(DDPMs)[1]–[4]。DDPMs可以被视为马尔可夫层次VAE,其中扩散过程被建模为具有多个连续VAE的马尔可夫链。每个扩散步骤对应于VAE的编码过程,而每个去噪步骤可以视为相应VAE的解码操作。另一方面,去噪扩散隐式模型(DDIMs)是DDPMs的一个变体,采用非马尔可夫的方法,使模型能够在去噪过程中跳过步骤,从而在一定质量的权衡下提高生成速度。另一类DMs是噪声条件评分网络(NCSNs)[6], [7], [10],其基于评分匹配[48]训练神经网络以学习真实数据分布的评分函数(即对数似然的梯度)。该评分函数指向训练数据所在的数据空间。因此,通过跟随评分,训练良好的NCSNs可以根据真实数据分布生成新的样本。这个过程也可以看作是一种去噪过程[49]。最后一个主要类别是基于评分的随机微分方程(SDE),它将DDPMs和NCSNs纳入一个广义形式中。前向过程通过SDE将数据映射到噪声分布,而反向过程则使用逆时间SDE[50]从噪声中生成样本。此外,交叉注意力技术[51]可用于通过多模态条件(如文本和图像)约束去噪神经网络,迫使去噪过程生成符合给定条件的结果。这引发了广泛的多模态生成任务,如文本生成图像和文本引导的图像生成[9]。尽管具有显著的潜力,DMs由于以下原因特别容易受到各种安全和隐私风险的影响:(i) 强大的DMs通常基于从多种开放资源收集的大规模数据进行训练,这些数据可能包含有毒数据或后门数据;(ii) 预训练的DMs在诸如HuggingFace1等开放平台上广泛发布,使得黑客更容易传播其操作过的模型。例如,通过操作训练数据和修改训练目标,攻击者可以将后门触发器嵌入DMs中以实施后门攻击[58]–[67]。因此,一旦在推理过程中向带有后门的DM输入触发器,它将始终生成攻击者指定的特定结果(例如,敏感图像或暴力文本)。即使在攻击者无法修改DMs参数的更安全设置下,他们仍可以构建DMs的输入以生成敏感内容,这被称为对抗性攻击[68]–[84]。在隐私方面,成员推理可以检测某个特定示例是否包含在DMs的训练数据集中。当训练数据高度敏感(例如,医学图像)时,这尤其危险。此外,DMs还用于各种安全应用中,如对抗性净化和稳健性认证,攻击这些应用中集成的DMs可能会使整个基于DM的安全系统失效[85], [86]。由于DMs受到广泛关注,并且各种基于DM的应用已被公众广泛使用,因此不可否认,DMs的安全性是一个重要的研究方向。然而,现有的DMs综述大多集中于其在架构改进、性能和应用方面的发展,而完全忽略了DMs的安全性。例如,文献[53]的作者综述了DMs的一系列算法改进,包括采样加速、扩散过程设计、似然优化和分布桥接方面的改进。此外,他们还回顾了DMs的各种应用,如图像/视频生成、医学分析、文本生成和音频生成。同样,综述[52]也讨论了DMs的应用和发展,特别关注高效的采样方法和改进的似然。此外,作者还深入探讨了DMs与其他深度生成模型类别如VAEs、GANs和EBMs之间的联系。在以应用为中心的综述中,也有多篇综述研究了基于DM的应用,包括计算机视觉[54]、NLP[55]、医学成像[56]和时间序列应用[57]。由于现有综述未探讨DMs的安全性方面,本文旨在填补这一空白,通过提供对该重要课题中最先进研究的系统和全面概述。通过分类不同类型的针对DMs的攻击并提出应对这些攻击的对策,我们希望本综述能为研究人员提供有益的指南,以探索和开发最先进的DMs安全方法。本文的贡献可以总结如下:
- 我们为读者提供了不同类型DMs的必要背景知识,包括DDPM、DDIM、NCSN、SDE和多模态条件DMs。我们展示了不同类别的DMs在一致的扩散原理下如何相互关联。
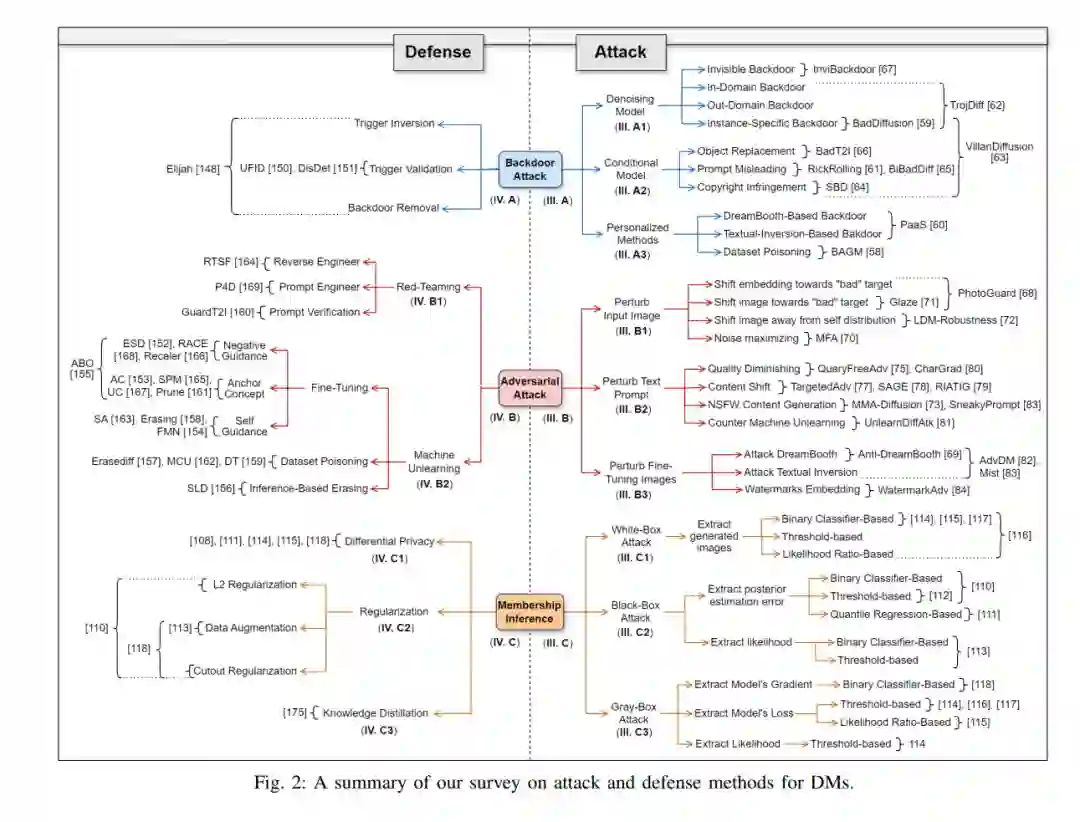
- 我们调查了针对DMs的广泛攻击,分为三个主要类别,包括后门攻击、成员推理攻击(MIAs)和对抗性攻击。每种攻击进一步根据相应的方法/应用分为子类别。
- 我们综述了基于该领域最先进研究的各种针对DMs攻击的对策。
- 我们讨论了该领域的多个开放性挑战,并展望了改进DMs及基于DM的应用安全性的一些有趣研究方向。 表I对我们工作与现有DMs相关综述进行了比较,强调了我们的贡献。本文余下部分的结构如下。第二节提供了不同类型DMs的初步知识以及DMs安全性的背景知识。第三节综述了针对DMs及基于DM的系统的最先进攻击方法。随后,第四节讨论了针对这些攻击的不同对策。第五节讨论了该领域的各种开放性挑战和未来研究方向,第六节对我们的综述进行了总结。