使用 Bert 预训练模型文本分类(内附源码)
(给数据分析与开发加星标,提升数据技能)
作者:GjZero,转自:数据派(ID:datapi)
Bert介绍
Bert模型是Google在2018年10月发布的语言表示模型,Bert在NLP领域横扫了11项任务的最优结果,可以说是现今最近NLP中最重要的突破。Bert模型的全称是Bidirectional Encoder Representations from Transformers,是通过训练Masked Language Model和预测下一句任务得到的模型。关于Bert具体训练的细节和更多的原理,有兴趣的读者可以去看在[arXiv](https://arxiv.org/abs/1810.04805)上的原文。本篇文章从实践入手,带领大家进行Bert的中文文本分类和作为句子向量进行使用的教程。
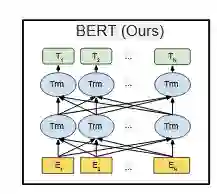
对于文本分类任务,一个句子中的N个字符对应了E_1,…,E_N,这N个embedding。文本分类实际上是将BERT得到的T_1这一层连接上一个全连接层进行多分类。
准备工作
1. 下载bert
在命令行中输入
git clone
https://github.com/google-research/bert.git2. 下载bert预训练模型
Google提供了多种预训练好的bert模型,有针对不同语言的和不同模型大小的。对于中文模型,我们使用[Bert-Base, Chinese](https://storage.googleapis.com/bert_models/2018_11_03/chinese_L-12_H-768_A-12.zip)。为了下载该模型,可能需要使用梯子。如果需要下载其他的模型(英文以及其他语言),可以在[Bert](https://github.com/google-research/bert)里的Pre-trained models找到下载链接。
3.(可选项)
安装bert-as-service,这是一个可以利用bert模型将句子映射到固定长度向量的服务。
在命令行中输入
pip install bert-serving-server # server
pip install bert-serving-client # client, independent of 'bert-serving-server'该服务要求tensorflow的最低版本为1.10。
准备数据
数据格式
作为中文文本分类问题,需要先将数据集整理成可用的形式。不同的格式对应了不同的DataProcessor类。可以将数据保存成如下格式:
game APEX是个新出的吃鸡游戏。
technology Google将要推出tensorflow2.0。
一行代表一个文本,由标签加上一个tab加上正文组成。
将文本分割为三个文件,train.tsv(训练集),dev.tsv(验证集),test.tsv(测试集);然后放置在同一个data_dir文件夹下。
编写DataProcessor类
在bert文件夹下的“run_classifier.py**中的”def main(_):”函数中将processors的内容增加为
python
processors = {
"cola": ColaProcessor,
"mnli": MnliProcessor,
"mrpc": MrpcProcessor,
"xnli": XnliProcessor,
"mytask": MyTaskProcessor,
}实现如下的“MyTaskProcessor
(DataProcessor)”类,并将这一段代码放置在“run_classifier.py”和其他Processor并列的位置。
“\_\_init\_\_(self)”中的self.labels含有所有的分类label,在这个例子中我们将文本可能分为3类:game, fashion, houseliving。
python
class MyTaskProcessor(DataProcessor):
"""Processor for the News data set (GLUE version)."""
def __init__(self):
self.labels = ['game', 'fashion', 'houseliving']
def get_train_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
return self._create_examples(
self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
return self.labels
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev sets."""
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text_a = tokenization.convert_to_unicode(line[1])
label = tokenization.convert_to_unicode(line[0])
examples.append(
InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples如果数据格式并不是一个label,一个tab,一段文本;则需要更改“_create_examples()”的实现。
编写运行脚本
新建一个运行脚本文件名为“run.sh”,将文件内容编辑为:
bash
export DATA_DIR=/media/ganjinzero/Code/bert/data/
export BERT_BASE_DIR=/media/ganjinzero/Code/bert/chinese_L-12_H-768_A-12
python run_classifier.py \
--task_name=mytask \
--do_train=true \
--do_eval=true \
--data_dir=$DATA_DIR/ \
--vocab_file=$BERT_BASE_DIR/vocab.txt \
--bert_config_file=$BERT_BASE_DIR/bert_config.json \
--init_checkpoint=$BERT_BASE_DIR/bert_model.ckpt \
--max_seq_length=128 \
--train_batch_size=32 \
--learning_rate=2e-5 \
--num_train_epochs=3.0 \
--output_dir=/mytask_output其中DATA_DIR是你的要训练的文本的数据所在的文件夹,BERT_BASE_DIR是你的bert预训练模型存放的地址。task_name要求和你的DataProcessor类中的名称一致。下面的几个参数,do_train代表是否进行fine tune,do_eval代表是否进行evaluation,还有未出现的参数do_predict代表是否进行预测。如果不需要进行fine tune,或者显卡配置太低的话,可以将do_trian去掉。max_seq_length代表了句子的最长长度,当显存不足时,可以适当降低max_seq_length。
进行预测
运行脚本
bash
./run.sh可以得到类似如下样式的结果
***** Eval results *****
eval_accuracy = 0.845588
eval_loss = 0.505248
global_step = 343
loss = 0.505248
如果出现了这样的输出,就是运行成功了。在“run.sh”里指定的output_dir文件夹下可以看到模型的evaluation结果和fine-tune(微调)之后的模型文件。
以句子向量的形式使用Bert
如果想要将bert模型的编码和其他模型一起使用,将bert模型作为句子向量使用很有意义(也就是所谓的句子级别的编码)。我们可以使用bert-as-service来完成这个目标。
安装完bert-as-service以后,就可以利用bert模型将句子映射到固定长度的向量上。在终端中用一下命令启动服务:
bash
bert-serving-start -model_dir /media/ganjinzero/Code/bert/chinese_L-12_H-768_A-12 -num_worker=4model_dir后面的参数是bert预训练模型所在的文件夹。num_worker的数量应该取决于你的CPU/GPU数量。
这时就可以在Python中调用如下的命令:
python
from bert_serving.client import BertClient
bc = BertClient()
bc.encode(['一二三四五六七八', '今天您吃了吗?'])最好以列表的形式,而非单个字符串传给”bc.encode()”参数,这样程序运行的效率较高。
参考文档
[Github:bert]
(https://github.com/google-research/bert)
[arXiv:bert]
(https://arxiv.org/pdf/1810.04805.pdf)
[Github:bert-as-service]
(https://github.com/hanxiao/bert-as-service)
推荐阅读
(点击标题可跳转阅读)
看完本文有收获?请转发分享给更多人
关注「数据分析与开发」加星标,提升数据技能

喜欢就点一下「好看」呗~




