摘要——目前,大多数工业物联网(IIoT)应用仍然依赖于基于卷积神经网络(CNN)的神经网络。尽管基于Transformer的大模型(LMs),包括语言、视觉和多模态模型,已经在AI生成内容(AIGC)中展示了令人印象深刻的能力,但它们在工业领域(如检测、规划和控制)中的应用仍然相对有限。在工业环境中部署预训练的大模型往往面临稳定性与可塑性之间的挑战,这主要是由于任务的复杂性、数据的多样性以及用户需求的动态性。为了应对这些挑战,预训练与微调策略结合持续学习已被证明是一种有效的解决方案,使模型能够适应动态需求,同时不断优化其推理和决策能力。本文综述了大模型在工业物联网增强的通用工业智能(GII)中的集成,重点关注两个关键领域:大模型赋能GII和GII环境下的大模型。前者侧重于利用大模型为工业应用中的挑战提供优化解决方案,而后者则研究在涉及工业设备、边缘计算和云计算的协同场景中,持续优化大模型的学习和推理能力。本文为GII的未来发展提供了洞见,旨在建立一个全面的理论框架和研究方向,从而推动GII向更加通用和适应性强的未来发展。 关键词——通用工业智能、大语言模型、持续学习、工业物联网、边缘计算。
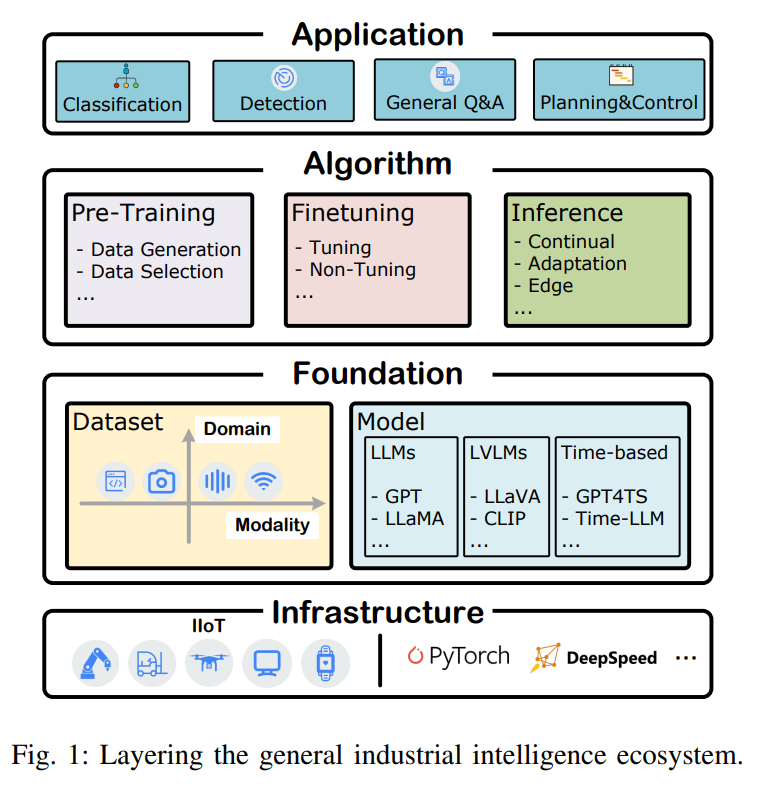
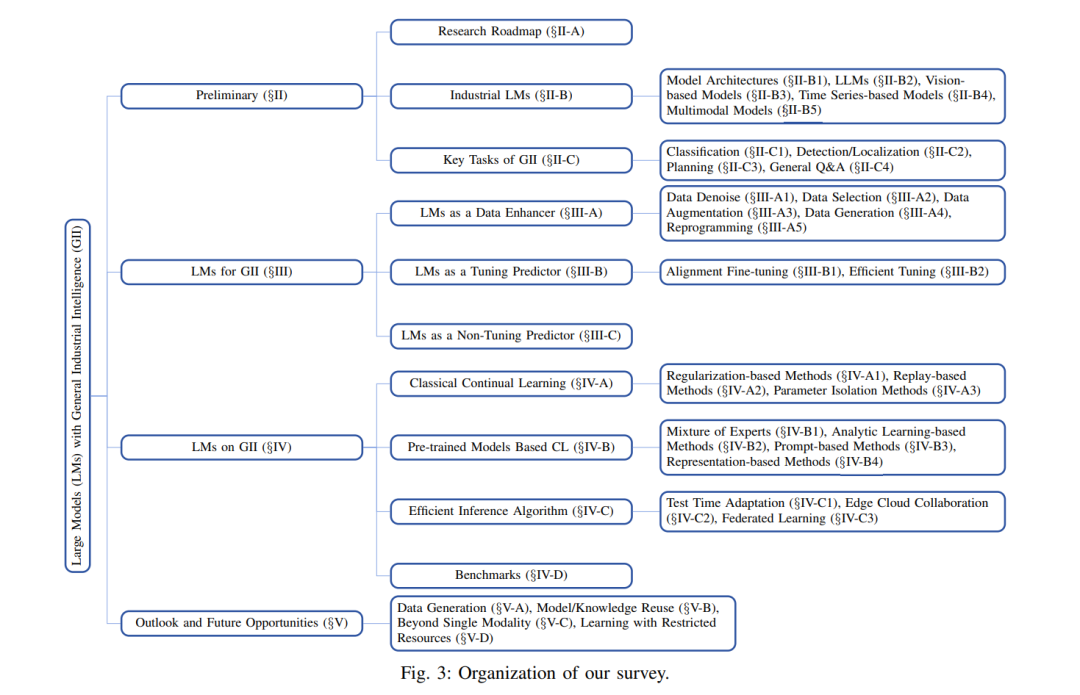
工业5.0将网络-物理-社会元素集成到制造业中,强调数字与物理系统的交互以及人机协作,通过互联网有效地连接设备、物体和人[1]。随着物联网(IIoT)的快速发展[2]-[4]、通信技术[5], [6]、AI生成内容(AIGC)[7]、机器人和数字孪生技术[8]-[10],现代工业系统变得越来越复杂。这些系统不仅生成高频的单模态数据,还包括文本、图像、视频、代码和音频等多模态数据类型。工业大数据可以用于创建数字化制造工作流程和工业流程,极大地推动了工业5.0和网络-物理-社会系统中生产力、效率和效能的提升。 如图1所示,数据集和模型构成了GII生态系统的基础要素,推动了更高层次算法和应用的快速发展。这些应用包括智能控制系统、预测性维护[11]、故障诊断[12], [13]和异常检测[14],这些都高度依赖于对IIoT数据的提取和分析。GII的成功特别依赖于其从这些IIoT数据集中高效学习和提取有价值特征的能力。基于Transformer的大模型(LMs),例如大语言模型(LLMs)[16]–[18]、视觉模型[19], [20]、时间序列模型[21]以及多模态模型[22], [23],由于其独特优势,受到广泛关注。通过在大规模数据集上进行预训练,这些拥有数十亿到数万亿参数的模型积累了广泛的知识,极大地推动了数据处理的自动化和多样化,同时减少了对人类专业知识的依赖。
在工业领域,大模型的精度和可扩展性使其在提高工业流程的准确性方面非常有效。然而,在工业环境中部署预训练大模型时,需要根据具体任务架构、动态数据分布和用户偏好进行谨慎的适配。尽管大模型在多任务泛化、小样本学习和推理方面具有优势,但在这些环境中平衡稳定性和适应性仍然是一个显著挑战。受到大模型在自然语言处理(NLP)中成功的启发,工业界越来越多地探索其在GII中的潜力。一种方法是从头构建行业特定的基础模型[24],但特定领域数据规模的限制通常阻碍了涌现能力的发展。另一种方法是通过大数据集上的预训练,然后进行特定任务的微调,这已显示出在构建稳健的工业模型方面的巨大潜力,显著提高了各类任务的性能。这种方法有效地应对了特定领域数据匮乏的挑战,同时加速了工业应用中先进能力的发展。
为工业任务调整大模型是一个重要的研究方向[25]。这些模型在跨任务泛化、零样本/小样本学习和推理能力方面的优势,为解决知识迁移、数据稀缺性和解释性问题提供了新的途径。 ****持续大模型(CLMs)****在维持和发展这些工业模型的能力方面发挥了关键作用。CLMs在大规模数据集上进行预训练,并由Transformer架构驱动,设计用于持续学习和适应,确保工业大模型在满足GII不断变化的需求时仍然保持相关性和有效性。
A. 本综述的目标
本文旨在建立一个全面的视角,并对IIoT增强的GII进行深入分析。它提出了将GII分为两个主要类别的概念:
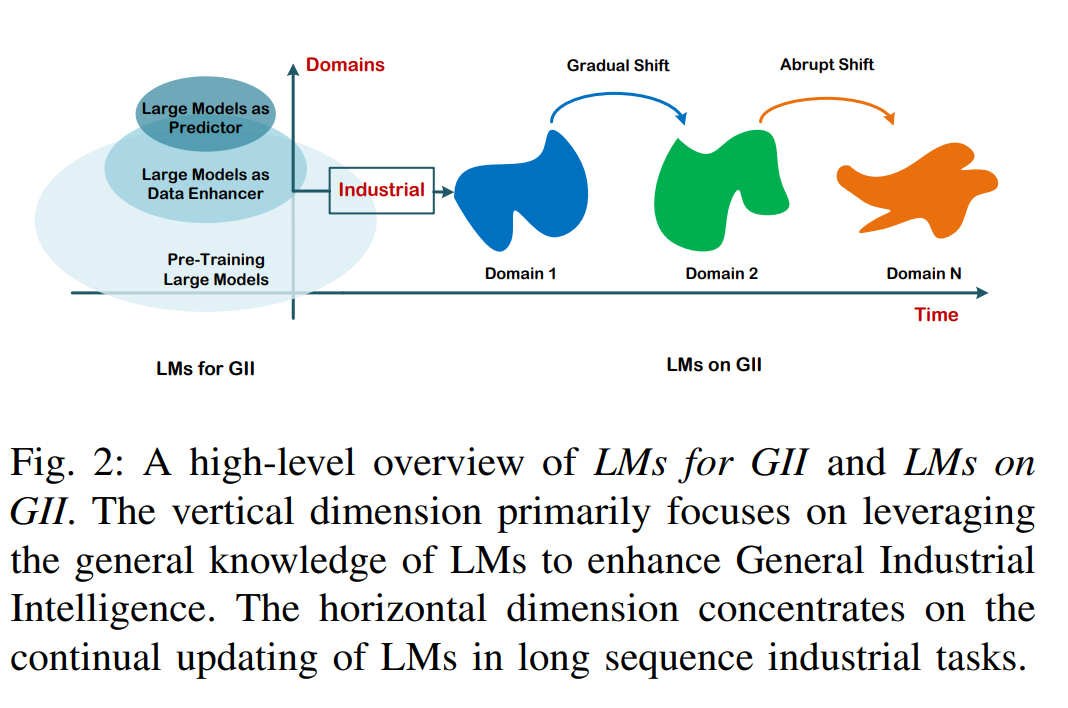
- 通用工业智能的大模型(LMs for GII):该方向重点利用大模型的高级数据处理和分析能力来解决工业应用中固有的优化问题。具体来说,LMs通过其处理实时多模态IIoT数据、执行复杂特征提取并确保精确的模式识别和结果验证的能力,提升了IIoT驱动的工业系统的智能化和运营效率,最终提高了不同工业环境中的测量精度和系统性能。
- 通用工业智能上的大模型(LMs on GII):该视角探讨了工业应用如何通过持续模型操作,在协同的IIoT设备-边缘-云环境中扩展和优化大模型的能力。通过采用持续学习(CL)和在线学习策略,模型可以适应新数据和环境变化,而无需昂贵的再训练。这种方法节省了计算资源,最小化了延迟,并高效处理了数据分布变化和性能退化,确保了动态工业场景中的稳健模型性能。
本文通过一个示意图(图2)进一步明确了这些类别的引入,帮助阐明了两种方法之间的结构性差异和操作机制。
B. 本综述的独特特征
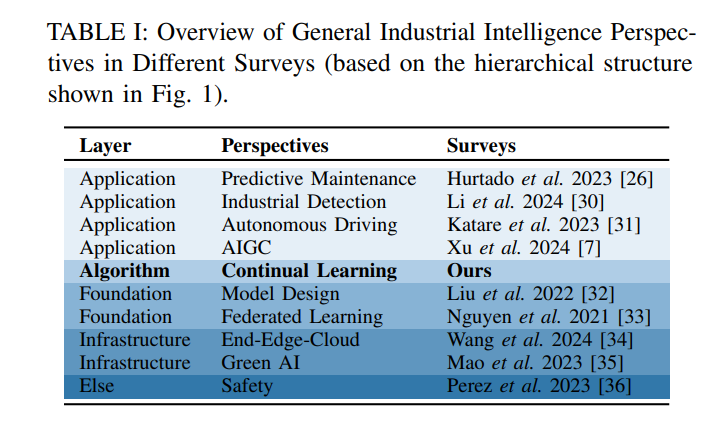
近年来,持续学习(CL)作为一个研究课题获得了显著关注,许多研究探讨了其在设备健康管理[26]、机器人[27]和流数据[28]等领域的应用。在大模型的背景下,由于这些模型的规模巨大,频繁的再训练成本高昂,因此CL已被认为是至关重要的[29]。尽管CL的文献广泛,但我们的综述独特地关注了CL在IIoT增强的工业系统中的大模型的持续适应性——这是现有文献中未被充分覆盖的领域。本综述首次为大模型在四个不同的IIoT工业场景中应用的CL方法提供了全面而系统的回顾。
如表I所示,本文通过以下几个关键贡献来区分自身:
-
新颖的分类体系:我们引入了一个新的GII理论框架。通过将大模型的应用分为两个维度——“LMs for GII”和“LMs on GII”,本文不仅探讨了如何利用大模型优化工业应用,还研究了这些应用如何反过来优化模型本身。这种双向交互视角显著丰富了现有文献。
-
跨领域多模态集成:与大多数仅专注于特定类型大模型(如语言模型或视觉模型)的现有研究不同,本综述涵盖了大语言模型(LLMs)、视觉Transformer、多模态模型和时间序列模型。这种跨模态集成增强了复杂仪器和测量系统的设计、开发和评估,这些系统用于信号的生成、获取、调理和处理。通过利用不同模型的独特优势,它为推进测量科学及其应用提供了更全面和深入的视角,从而更有效地应对复杂的工业挑战。
-
持续学习的实际应用:本文强调了持续学习策略在IIoT增强的工业系统,特别是边缘计算和云计算协同环境中的实际应用。这个重点确保了模型不仅能适应新数据和变化的条件,还能资源高效。通过减少计算需求和训练成本,我们的方法解决了工业应用中的关键约束。