

手术视频-语言预训练(VLP)由于知识领域的差异和多模态数据的稀缺,面临独特的挑战。本研究旨在通过解决手术讲解视频中的文本信息丢失问题,以及手术VLP的时空挑战,来缩小这一差距。我们提出了一种分层知识增强方法,并设计了一种新的流程编码的手术知识增强视频-语言预训练框架(PeskaVLP)来应对这些问题。知识增强使用大型语言模型(LLM)来优化和丰富手术概念,从而提供全面的语言监督,降低过拟合的风险。PeskaVLP将语言监督与视觉自监督相结合,构建难负样本,并采用基于动态时间规整(DTW)的损失函数,来有效理解跨模态的流程对齐。基于多个公开的手术场景理解和跨模态检索数据集的大量实验表明,我们提出的方法显著提高了零样本迁移性能,并为手术场景理解的进一步发展提供了通用的视觉表示。

成为VIP会员查看完整内容

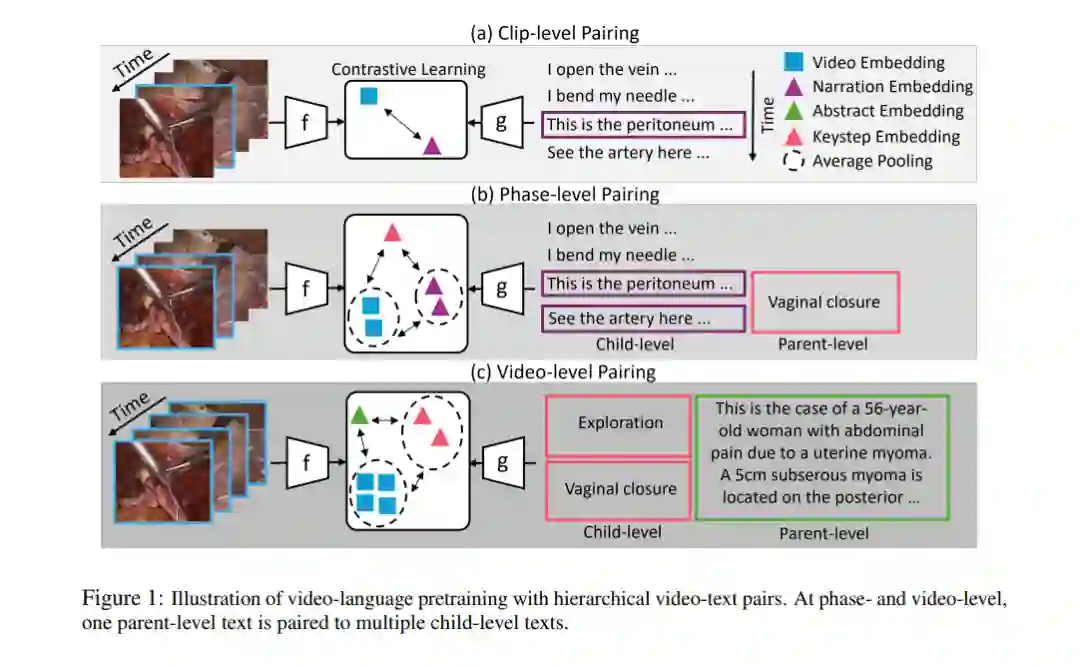
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
153+阅读 · 2023年3月29日
相关主题
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
153+阅读 · 2023年3月29日