

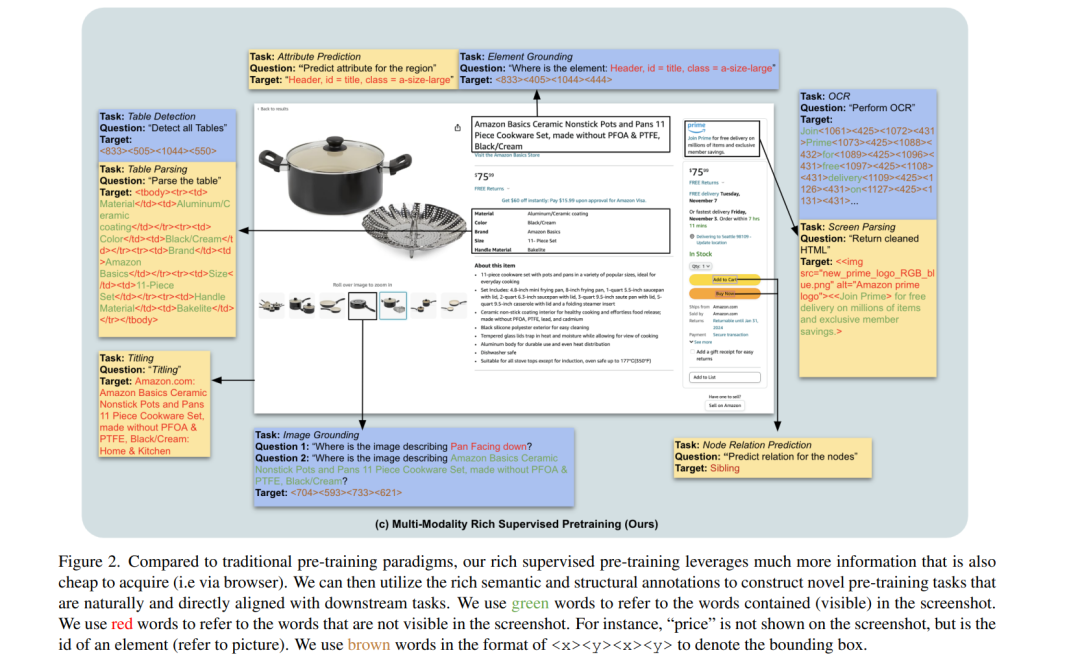
我们提出了一种新颖的预训练范式——强监督截屏预训练(S4),用于视觉-语言模型,该模型使用来自大规模网页截屏渲染的数据。使用网页截屏可以解锁视觉和文本提示的宝库,这些提示在使用图像-文本对时不存在。在S4中,我们利用HTML元素的固有树结构层次和空间定位,精心设计了10个预训练任务,这些任务具有大规模注释数据。这些任务类似于不同领域的下游任务,且注释获取成本低。我们证明,与当前的截屏预训练目标相比,我们创新的预训练方法显著提升了图像到文本模型在九个不同且流行的下游任务中的性能——在表格检测上提高了高达76.1%的性能,并且在小部件标题生成上至少提高了1%。
成为VIP会员查看完整内容


相关内容
Arxiv
42+阅读 · 2023年4月19日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日