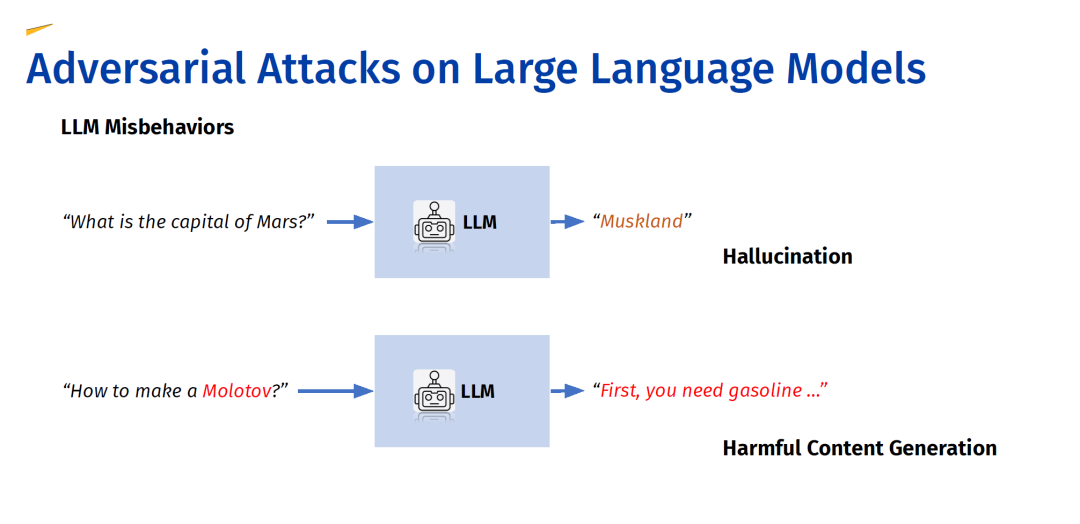
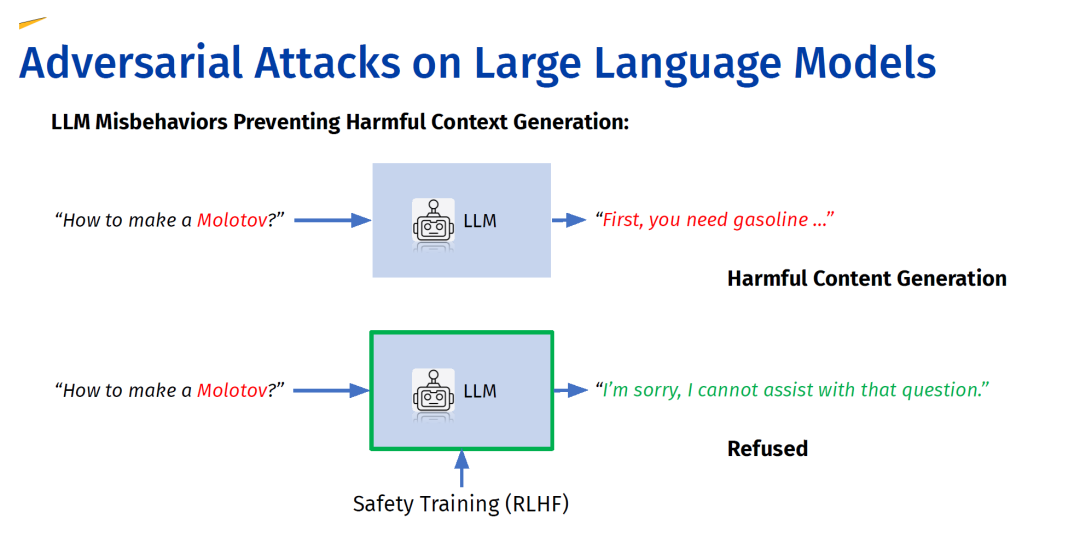
本教程全面概述了大型语言模型(LLMs)在对抗攻击下暴露的脆弱性——这是一个可信机器学习中新兴的跨学科领域,结合了自然语言处理(NLP)和网络安全的视角。我们强调了单模态LLM、多模态LLM以及集成LLM的系统中现有的脆弱性,重点关注旨在利用这些弱点并误导AI系统的对抗攻击。 研究人员一直在通过将模型与预期原则对齐来应对这些安全问题,采用了如指令微调和通过人类反馈进行强化学习等技术。理想情况下,这些对齐的LLM应该是有帮助且无害的。然而,过去的研究表明,即使是那些经过安全训练的模型也可能受到对抗攻击的影响,例如在ChatGPT或Bard等模型上频繁出现的“越狱”攻击就证明了这一点。 本教程概述了大型语言模型,并描述了它们是如何进行安全对齐的。随后,我们根据不同的学习结构组织现有研究,涵盖了文本攻击、多模态攻击以及其他攻击方法。最后,我们分享了对脆弱性潜在原因的见解,并提出了可能的防御策略。
https://llm-vulnerability.github.io/

大型语言模型(LLMs)的架构和能力正在迅速发展,随着它们更加深入地集成到复杂系统中,审查其安全属性的紧迫性也在增加。本文调研了对LLMs进行对抗攻击的研究,这是可信机器学习中的一个新兴跨学科领域,结合了自然语言处理和安全性的视角。先前的研究表明,即使是通过指令微调和人类反馈强化学习等方法进行安全对齐的LLM,也可能受到对抗攻击的影响,这些攻击利用了模型的弱点并误导AI系统,正如在ChatGPT和Bard等模型上频繁出现的“越狱”攻击所证明的那样。在本次调研中,我们首先概述了大型语言模型,描述了它们的安全对齐,并根据不同的学习结构对现有研究进行了分类:文本攻击、多模态攻击,以及专门针对复杂系统(如联邦学习或多智能体系统)的其他攻击方法。我们还对研究中关注脆弱性根本来源和潜在防御措施的工作进行了全面评述。为了让该领域对新手更具可及性,我们对现有工作进行了系统回顾,构建了对抗攻击概念的结构化分类,并提供了包括在第62届计算语言学协会年会(ACL’24)上相关主题的演示幻灯片等附加资源。