

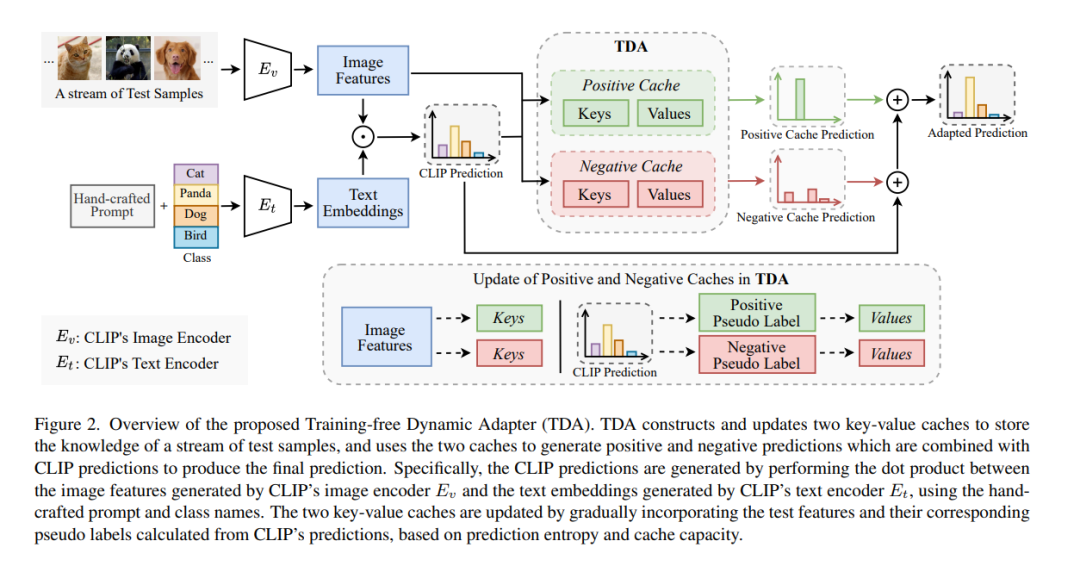
在测试时使用预训练的视觉-语言模型进行适应性调整已经吸引了越来越多的关注,以解决测试时的分布偏移问题。尽管之前的研究已经取得了非常有希望的表现,但它们涉及到的计算量非常大,这与测试时间的适应性调整严重不符。我们设计了TDA,一个无需训练的动态适配器,使视觉-语言模型能够有效且高效地进行测试时间的适应性调整。TDA利用轻量级的键-值缓存,维护一个动态队列,队列中的值为少量样本的伪标签,对应的测试样本特征作为键。利用键-值缓存,TDA允许通过逐步精炼伪标签来逐渐适应测试数据,这种方式超级高效,不需要任何反向传播。此外,我们引入了负伪标签,通过为某些负类分配伪标签来减轻伪标签噪声的不利影响,当模型对其伪标签预测不确定时采用。在两个基准测试上的广泛实验表明,与最先进的方法相比,TDA展示出了更高的有效性和效率。代码已在https://kdiaaa.github.io/tda/ 发布。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日