扩散生成模型最近已成为一种用于生成和修改连贯、高质量视频的强大技术。本综述提供了视频生成扩散模型关键元素的系统概览,涵盖应用、架构选择以及时间动态的建模。领域中的最新进展被总结并归类为发展趋势。综述以剩余挑战的概览和对该领域未来的展望结束。网站:https://github.com/ndrwmlnk/Awesome-Video-Diffusion-Models。
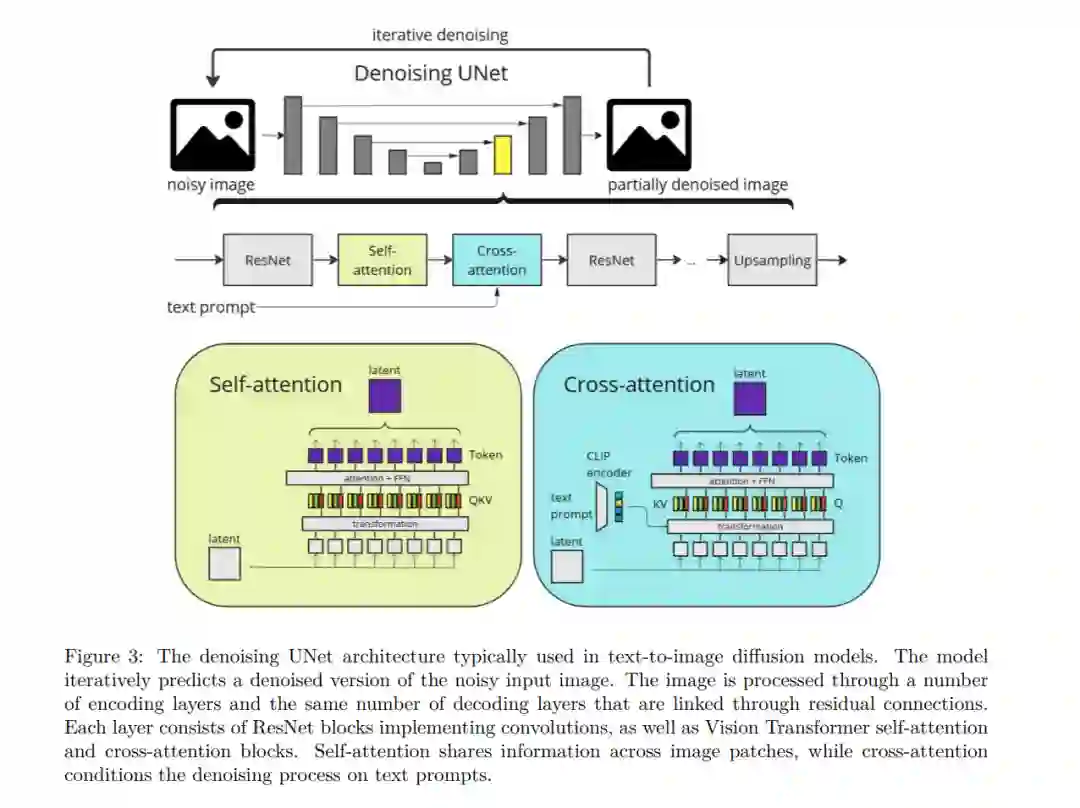
扩散生成模型(Sohl-Dickstein等,2015年;Song & Ermon,2019年;Ho等,2020年;Song等,2021年;Ruiz等,2024年)已经展示了学习多样化视觉概念和基于文本描述创建高质量图像的显著能力(Rombach等,2022年;Ramesh等,2022年)。最近的发展还将扩散模型扩展到了视频领域(Ho等,2022c),具有彻底革新娱乐内容生成或为智能决策模拟世界的潜力(Yang等,2023a)。例如,文本到视频的SORA模型(Brooks等,2024年)已能够根据用户的提示生成长达一分钟的高质量视频。将扩散模型适应视频生成带来了独特的挑战,这些挑战仍需克服,包括维持时间一致性、生成长视频和计算成本。
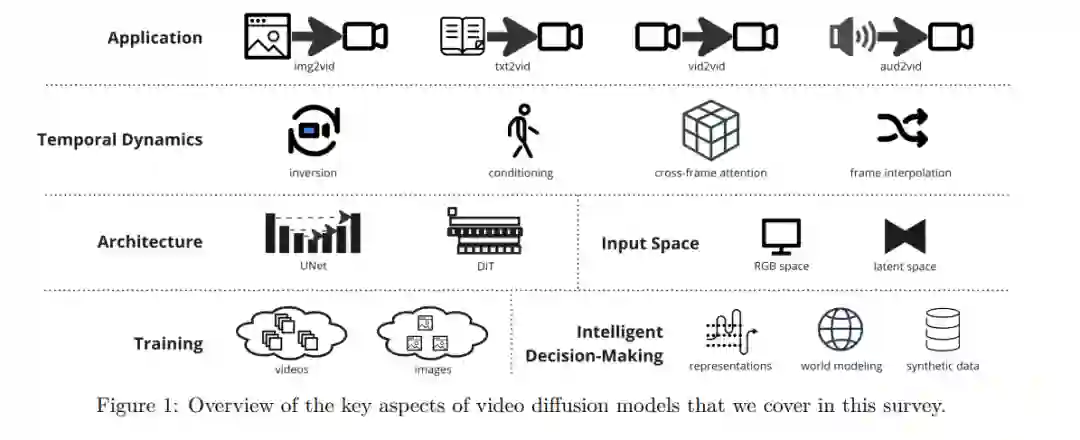
在本综述中,我们提供了视频扩散模型的关键方面概览,包括可能的应用、架构选择、时间动态建模机制和训练模式(见图1以获取概览)。随后,我们将简要总结一些值得注意的论文,以勾勒出到目前为止该领域的发展。最后,我们总结讨论持续存在的挑战,并识别未来改进的潜在领域。
应用分类
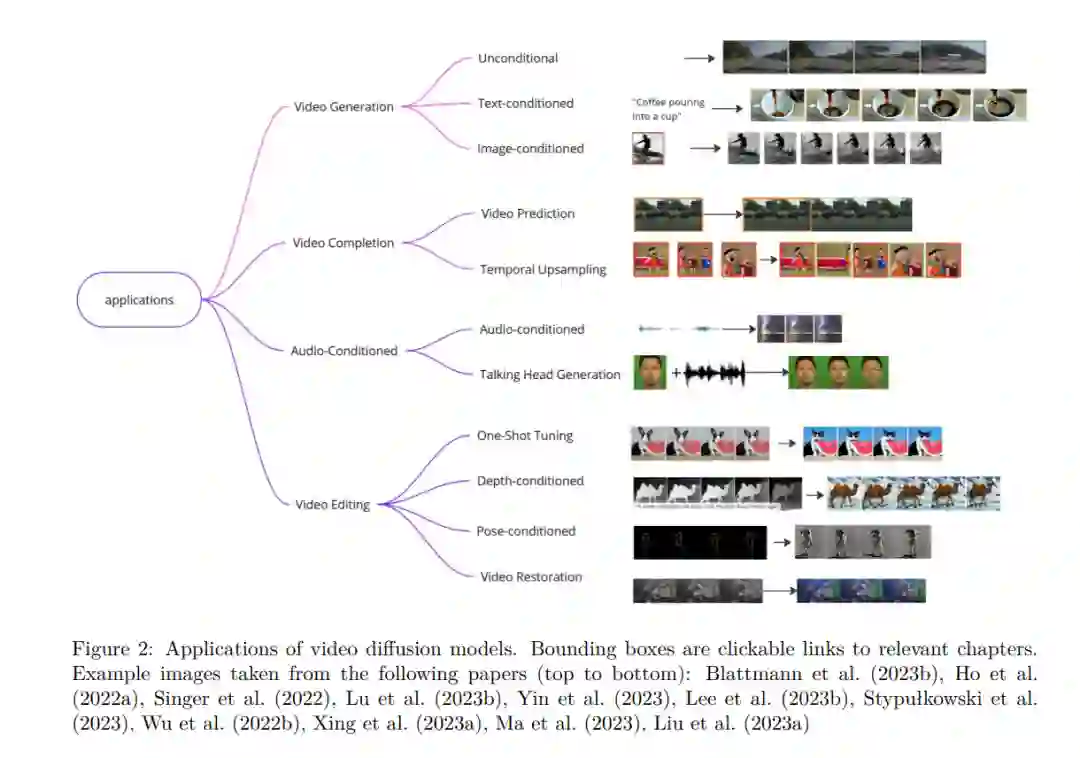
视频扩散模型的可能应用可以根据输入方式大致分类。这包括文本提示、图像、视频和听觉信号。许多模型也接受这些模态的某些组合作为输入。图2展示了不同的应用。我们从第7.1.3节开始,总结了每个应用领域中的重要论文。为此,我们根据一个主要任务对每个模型进行了分类。
在我们的分类中,文本条件生成(第7.1.3节)指的是完全基于文本描述生成视频的任务。不同模型在如何模拟对象特定运动方面表现出不同程度的成功。因此,我们将模型分为两类:一类能够产生简单运动,如轻微的摄像机平移或流动的头发;另一类能够表现出更复杂的随时间变化的运动,如融入物理推理的模型(Melnik等,2023年)。
在图像条件视频生成(第7.4节)任务中,一个现有的参考图像被赋予动画效果。有时,提供文本提示或其他指导信息。由于其对生成视频内容的高度可控性,图像条件视频生成近期已被广泛研究。对于在其他章节中介绍的模型,我们在适用的情况下提及它们的图像到视频生成能力。
我们将视频补全模型(第8节)视为一个独立的组,这些模型接受现有视频并在时间域中进行扩展,尽管它们与前面的应用有交集。视频扩散模型通常由于架构和硬件限制而具有固定的输入和输出帧数。为了扩展这些模型生成任意长度的视频,已探索了自回归和分层方法。
音频条件模型(第9节)接受声音片段作为输入,有时与文本或图像等其他模态结合。然后它们可以合成与声源一致的视频。典型应用包括生成说话的面孔、音乐视频以及更一般的场景。 视频编辑模型(第10节)使用现有视频作为基线,从中生成新视频。典型任务包括风格编辑(在保持对象身份的同时改变视频的外观)、对象/背景替换、深度伪造以及恢复旧视频素材(包括去噪、上色或扩展宽高比等任务)。
最后,我们考虑将视频扩散模型应用于智能决策(第11节)。视频扩散模型可以用作基于代理当前状态或高级文本任务描述的现实世界模拟器。这可以使在模拟世界中进行规划成为可能,同时也可以在生成性世界模型内完全训练强化学习策略。