本文报告了一项正在进行的调查,该调查比较了大型语言模型(LLM)在为现实的红队代理生成渗透测试脚本方面的性能。目标是在自动化网络操作环境中开发人类级别的对手(红队代理),并通过仪器训练蓝队代理团队。定义了五种方法,用于构建生成 Metasploit 脚本的提示,以利用常见漏洞暴露(CVE)中描述的漏洞。使用三种 LLM(即 GPT-4o、WhiteRabbitNeo 和 Mistral-7b)对这些方法进行了测试。GPT-4o 被用作比较研究的基线。结果表明,GPT-4o 在所有实验中都优于其他 LLM。不过,结果还表明,由于参数数量较少,Mistral-7b 可以进行微调,以达到可接受的性能,同时在执行过程中消耗更少的计算和内存资源: Mistral-7b 的参数数量为 70 亿个,而 GPT-4o 的参数数量为 1.76 万亿个。
索引词条-大型语言模型、渗透测试、自主攻击代理、联盟网络
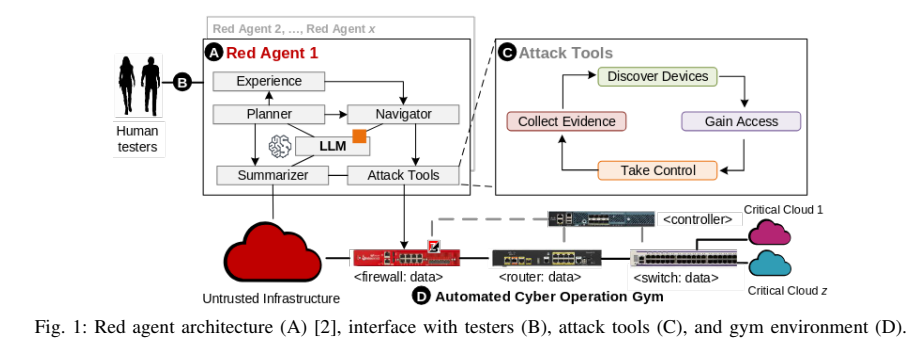
最近的文献表明,大型语言模型(LLMs)可以自动执行人类级别的渗透测试任务,并且性能良好[1]-[4]。这些 ndings 促使本研究使用 LLMs 创建可自动执行网络攻击的真实红队代理。我们的目标是将红队代理部署到自动网络操作 (ACO) 健身房中,以训练强大的蓝队代理,让它们以团队的形式保卫军事联盟网络 [5]-[7]。我们首先假设,可以使用 LLM 生成渗透测试脚本,利用 Metasploit 模块[8]利用常见漏洞和暴露(CVE)中描述的已知漏洞。
然而,带有大量参数的 LLMs 需要大量的处理能力和内存,从而增加了运行成本和对环境的影响。对较小的 LLM 进行微调可以为特定任务实现类似的性能,从而降低 财务成本和环境影响。微调和量化方法的最新进展彻底改变了 LLM 的性能和功能,使更大的模型也能在消费级个人电脑图形处理器(GPU)上训练和高效运行。
因此,本文定义了一种对生成 Metasploit 脚本的 LLM 进行比较评估的方法。我们选择了三种参数数量不同的 LLM,即 GPT-4o(封闭源代码,超过一万亿个参数)、WhiteRabbitNeo(330 亿个参数)和 Mistral-7b(70 亿个参数)。GPT-4o 是比较的基准,因为它是本次调查时的前沿模型[9]、[10]。WhiteRabbitNeo 是专为网络安全领域定制的 LLama-33B 微调版本,可通过其专门网站使用 [11],[12]。最后,2023 年 9 月发布的模型 Mistral-7b [13] 是本次比较的低端基线。尽管 Mistral-7b 的尺寸较小,但它在自然语言理解和生成任务中的强劲性能却备受关注[14]。特别是,由于采用了参数效率高的技术(如低秩自适应(Low-Rank Adaptation,LoRA)[15]),Mistral-7b 易于微调,因此开发人员可以使用消费级 GPU 高效地调整 Mistral-7b。简而言之,本文的主要贡献在于
简而言之,本文的主要贡献是
- 定义使用 Metasploit 框架生成渗透测试脚本的五种提示方法。
- 设计并实现一个用于人在环提示校准的网络应用程序。
- 三种 LLM 的性能比较分析: GPT4o、WhiteRabbitNeo-33b 和 Mistral-7b。
本文其余部分安排如下。第二节讨论了也使用微调 LLMs 进行自主网络防御/反击的相关研究,以及本次调查的动机。第三节介绍了生成 Metasploit 脚本的实验,并讨论了红队代理架构的主要功能模块,以及用于评估的人工在环管道。第四部分讨论了在五种不同提示方法下使用三种不同 LLM 观察到的定量结果。最后,第五节总结了本文并列举了未来的工作。