

深度强化学习(DRL)已经在单智能体学习中得到了广泛的研究,但在多智能体领域还需要进一步发展和理解。作为最复杂的集群问题之一,竞争性学习评估了多智能体团队合作实现某些目标的性能,同时超越了其他候选方案。这样的动态复杂性使得即使是小众的DRL方法也难以解决多智能体问题。在一个竞争性的框架内,我们研究了最先进的演员评论家算法和Q算法,并从性能和收敛性方面深入分析了它们的改型(如优先化、双重网络等)。为了讨论的完整性,我们提出并评估了一个异步和优先版本的近似策略优化行为批判技术(P3O)与其他基准的对比。结果证明,在给定的环境中,基于Q的方法比演员评论家的配置更加稳健和可靠。此外,我们建议纳入本地团队通信,并将DRL与直接搜索优化相结合,以提高学习效果,特别是在具有部分观察的挑战性场景中。
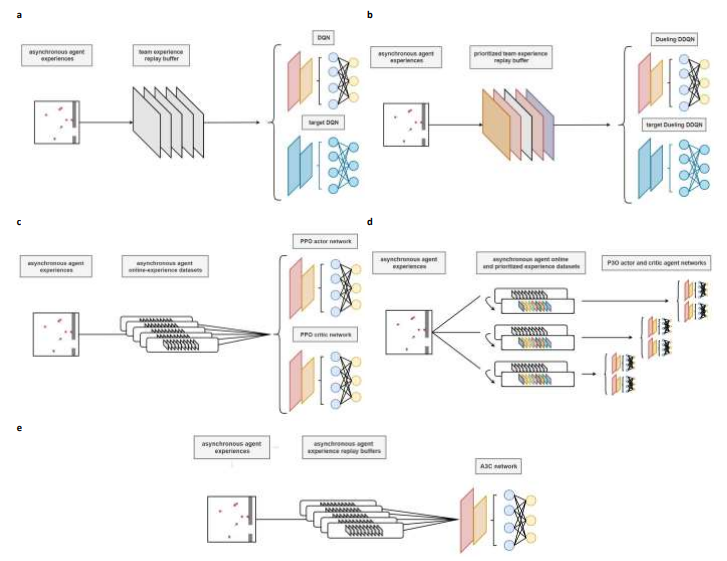
图3 多智能体深度强化学习系统。已实现的深度强化学习技术所使用的主要算法数据流图。a) 具有单一团队经验重放缓冲区的深度Q网络。尽管保存了异步强化学习转换,但样本是随机的。目标网络,其参数以缓慢的方式更新,给学习过程带来了稳定性。b) 带有优先团队经验重放缓冲器的决斗双深Q网络。根据时差误差为每个存储的过渡分配随机优先级。c) 带有分布式记忆的近似策略优化。网络更新由团队智能体异步进行。d) 带有智能体分布式记忆、演员评论家网络的优先级近似策略优化。每个智能体存储自己的经验,并使用它们来进行异步网络更新。同时,根据有效的召回系数建立优先的数据集,然后用来训练网络。此外,该算法还与团队共享的演员评论家网络以及团队共享的演员评论家网络进行了研究。e)具有分布式记忆的异步优势演员评论家。
成为VIP会员查看完整内容
相关内容

Arxiv
0+阅读 · 2023年5月8日
Arxiv
11+阅读 · 2022年12月1日
Arxiv
34+阅读 · 2022年6月30日


相关VIP内容
相关资讯