

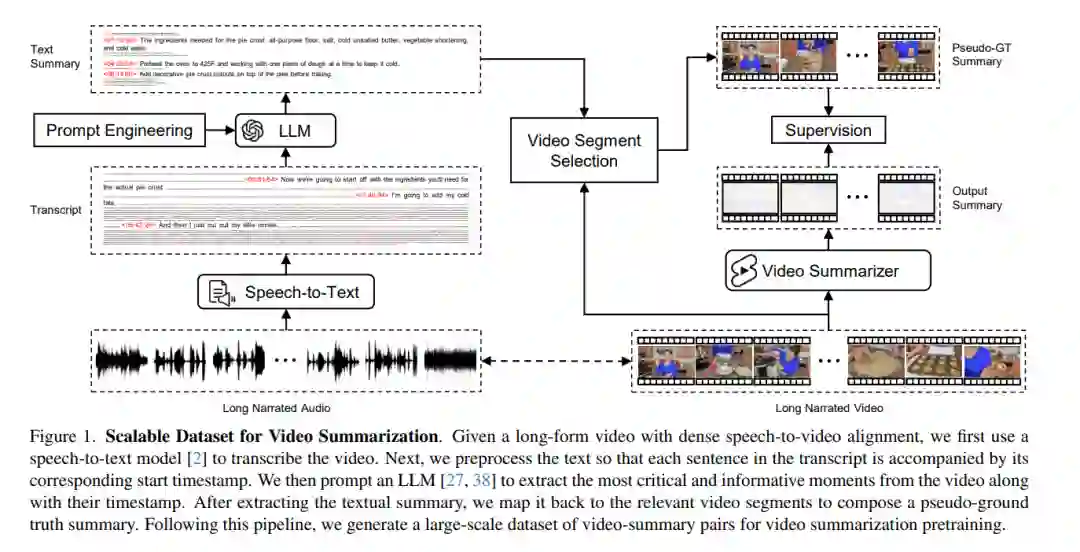
长篇视频内容占据了互联网流量的大部分,使得自动视频摘要成为一个重要的研究问题。然而,现有的视频摘要数据集在其规模上明显有限,限制了最先进方法的泛化效果。我们的工作旨在通过利用大量的长篇视频以及密集的语音到视频对齐,加上最近大型语言模型(LLMs)在长文本摘要方面的显著能力,来克服这一限制。我们引入了一个自动化且可扩展的流程,使用LLMs作为Oracle摘要器,来生成大规模的视频摘要数据集。通过利用生成的数据集,我们分析了现有方法的局限性,并提出了一个新的视频摘要模型,有效地解决了这些问题。为了进一步推动该领域的研究,我们的工作还提出了一个新的基准数据集,包含1200个长视频,每个视频都有专业人士注释的高质量摘要。广泛的实验清楚地表明,我们提出的方法在几个基准测试中设定了新的视频摘要的最先进水平。
成为VIP会员查看完整内容
相关内容
Arxiv
224+阅读 · 2023年4月7日

相关VIP内容
相关资讯
相关论文
Arxiv
224+阅读 · 2023年4月7日