

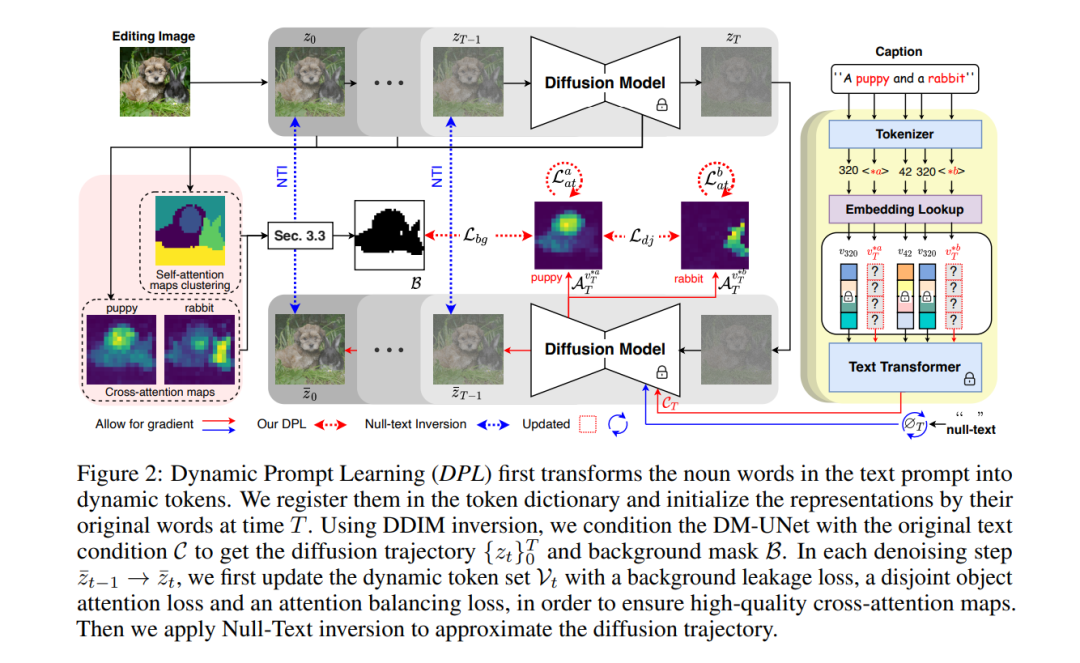
大型文本到图像生成模型在生成性AI中已经取得了突破性的发展,扩散模型展现了根据输入文本提示合成令人信服的图像的惊人能力。图像编辑研究的目标是通过修改文本提示来赋予用户对生成图像的控制。目前的图像编辑技术容易在目标区域之外的区域,例如背景或与目标对象具有某种语义或视觉关系的干扰物体上,发生无意的修改。根据我们的实验发现,不准确的交叉注意图是这个问题的根源。基于这一观察,我们提出了动态提示学习(Dynamic Prompt Learning, DPL)以强制交叉注意图集中于文本提示中的正确名词词汇。通过使用所提出的漏洞修复损失更新文本输入中的名词的动态代币,我们实现了对特定对象的细粒度图像编辑,同时防止了对其他图像区域的不希望的变化。我们的方法DPL基于公开可用的稳定扩散(Stable Diffusion)进行了广泛的评估,在大量图像上一致获得了优越的结果,无论是量化(CLIP得分,Structure-Dist)还是定性(用户评估)都是如此。我们展示了对于词汇交换(Word-Swap)、提示细化(Prompt Refinement)和注意力重新加权(Attention Re-weighting),尤其是在复杂的多对象场景中,改进了的提示编辑结果。
https://www.zhuanzhi.ai/paper/6d05c294e2563ab4ba741b13341a1e14
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日
相关主题


相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
Arxiv
85+阅读 · 2023年3月21日