论文浅尝 | 基于深度强化学习的远程监督数据集的降噪

论文链接:https://arxiv.org/pdf/1805.09927.pdf
来源:ACL2018
Motivation:
远程监督是以一种生成关系抽取训练样本的方法,无需人工标注数据。但是远程监督引入了噪音,即存在很多的假正例。本文的出发点非常简单,希望通过强化学习的方法来训练一个假正例的判别器,它可以识别出数据集中的假正例,并加入到负例集中。产生更加干净的训练集,从而提高分类器的性能。
Relatedwork:
对于远程监督的噪音,之前常用的做法是加attention机制,给以真正例更大的权重,给以假正例较小的权重,单这种方法是次优的。本文有一个有意思的地方,作者在文中指出,他在提交了ACL之后,发现已经有一篇相同的工作. Reinforcement learning for relation classification from noisy data(参照论文笔记),是 feng 等人发表在AAAI 2018上的,两篇文章从立意到方法都基本一致,唯一不同的就是强化学习的reward不同。feng 等人的论文中 reward 来自预测概率,而这篇论文的 reward 是分类器的性能的改变。
Model:
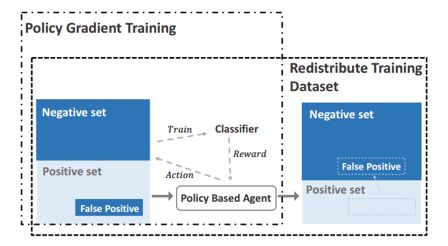
远程监督中的强化学习框图
模型的整体结构如上图所示。首先对每一个关系,生成相应的正负样本,划训练集和验证集。在每一个epoch中,利用了 policy based 的 agent,对训练集的正样本做筛选,对每个句子选择保留或者移除到负样本集,得到筛选后的训练集。然后在此训练集上训练关系抽取分类器,在验证集上做测试得到分类的F1值。根据分类器的 F1 值的变化得到 reward,最后利用 policy gradient 对参数作更新。下面介绍RL方法中几个基本要素:
States:
为了满足MDP的条件,state不仅包含了当前句子的信息,还加入了过去句子的信息。对当前句子给予较大的权重,对过去句子给予较小的权重。句子的向量表示采用了常用的 word embedding 和 position embedding。
Actions:
Agent 的作用是识别出正样本中的假正例,所以action包含了两种:判断当前句子为真正例并保留;判断为假正例并移除到负样本集中。
Rewards:
Rewards 来自于关系抽取分类器的性能变化,论文中采用的是第i轮的F1值减去第i-1轮的F1值。
Policy Network:
Policy Network 的作用相当于一个二元分类器,故论文采取了一个简单的CNN网络。
另外,Policy Network 采用了预训练的策略,目的是加快收敛。训练整体的流程如下图所示:

Experiments:
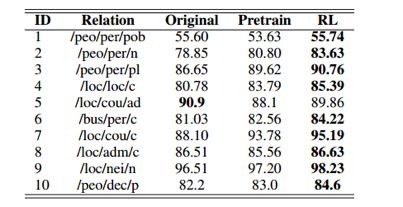
实验在远程监督常用的 NYT 数据集和主流方法做了比较。下表首先给出了在原始数据集、预训练的 agent 筛选后的数据集上、RL agent 筛选后的数据集上训练得到的分类器性能对比,可以看到,RL 有效提升了分类器的性能。
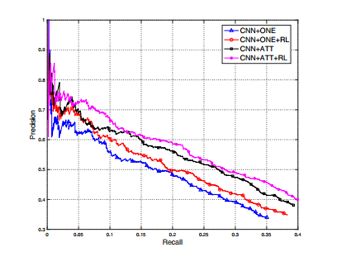
下面两张图给出了关系抽取分类器分别采用 CNN 和 PCNN 时,加入 RL 和不加 RL 的分类结果的 PR 曲线图,可以看到加入 RL 提升了分类器的性能。
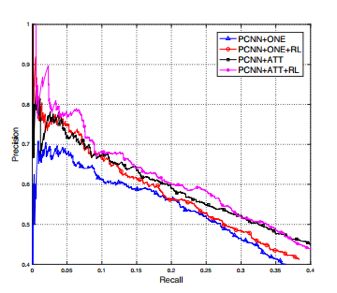
Conclusion:
本文利用强化学习的方法,对远程监督的数据集进行降噪,从而提升分类器的性能。另外,Agent 的 Reward 来自于分类器性能的改变,不需要加入额外的监督信息。
论文笔记整理:叶志权,浙江大学硕士,研究方向为自然语言处理、知识图谱。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。