

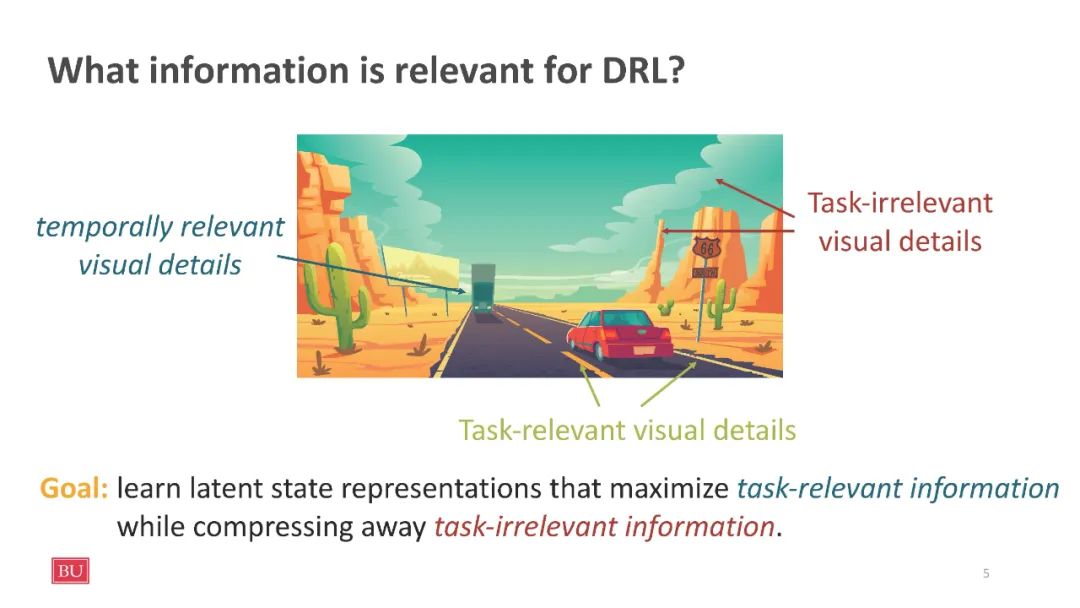
深度强化学习(DRL)智能体通常对其训练环境中看不到的视觉变化敏感。为了解决这个问题,我们利用RL的顺序特性来学习稳健的表示,这种表示只编码来自基于无监督多视图设置的观察的任务相关信息。具体地说,我们为时间数据引入了一个新的多视图信息瓶颈(MIB)目标的对比版本。我们用这个辅助目标从像素训练RL智能体来学习鲁棒的表示,它可以压缩与任务无关的信息,并可以预测与任务相关的动态。这种方法使我们能够训练出高性能的策略,这些策略能够抵御视觉干扰,并能够很好地推广到看不见的环境中。我们证明,当背景被自然视频取代时,我们的方法可以在DeepMind控制套件中不同的视觉控制任务集上实现SOTA性能。此外,我们还展示了在Procgen基准测试中,我们的方法优于已建立的基线,可以泛化到看不见的环境。我们的代码是开源的,可以在https://github上找到。com/BU-DEPEND-Lab/DRIBO。


成为VIP会员查看完整内容
相关内容

专知会员服务
78+阅读 · 2020年3月1日
Arxiv
0+阅读 · 2022年10月3日
Arxiv
0+阅读 · 2022年10月3日
Arxiv
0+阅读 · 2022年9月30日

相关VIP内容
专知会员服务
78+阅读 · 2020年3月1日
相关资讯
相关论文
Arxiv
0+阅读 · 2022年10月3日
Arxiv
0+阅读 · 2022年10月3日
Arxiv
0+阅读 · 2022年9月30日