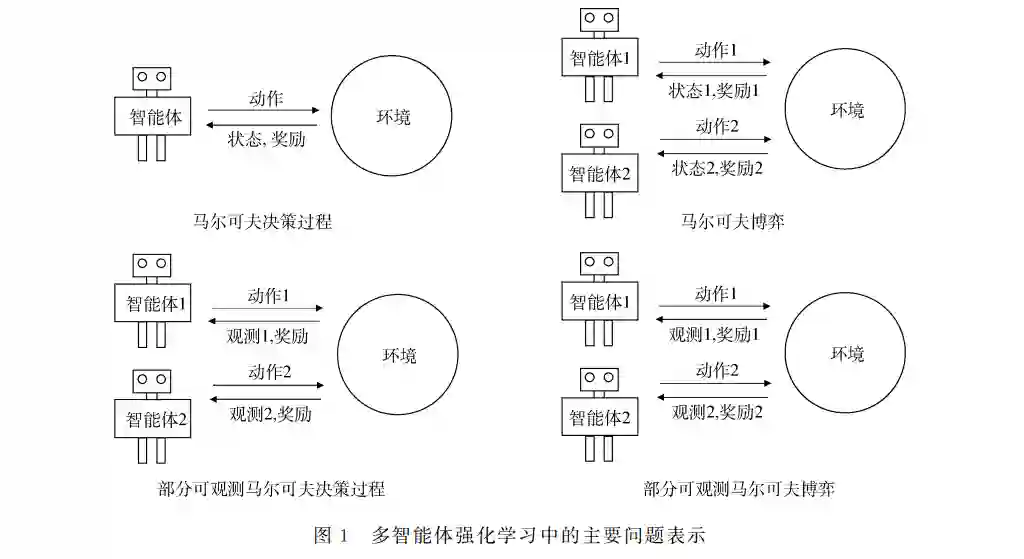
深度强化学习(DeepReinforcementLearning,DRL)在近年受到广泛的关注,并在各种领域取得显著的成 功.由于现实环境通常包括多个与环境交互的智能体,多智能体深度强化学习(Multi-AgentDeepReinforcement Learning,MADRL)获得蓬勃的发展,在各种复杂的序列决策任务上取得优异的表现.本文对多智能体深度强化学 习的工作进展进行综述,主要内容分为三个部分.首先,我们回顾了几种常见的多智能体强化学习问题表示及其对 应的合作、竞争和混合任务.其次,我们对目前的 MADRL方法进行了全新的多维度的分类,并对不同类别的方法 展开进一步介绍.其中,我们重点综述值函数分解方法,基于通信的 MADRL方法以及基于图神经网络的 MADRL 方法.最后,我们研究了 MADRL方法在现实场景中的主要应用.希望本文能够为即将进入这一快速发展领域的新 研究人员和希望获得全方位了解并根据最新进展确定新方向的现有领域专家提供帮助.随着人工智能和大数据时代的到来,受益于海 量的数据以及硬件发展带来的算力提升,深度学习 (DeepLearning,DL)[1]在诸多领域取得了引人注目 的成功,如计算机视觉[2-4]、语音识别[5-7]、自然语言 处理[8-10]等.深度学习模型的神经网络的训练,通常 依赖大量的有标签数据为网络中巨量的参数提供稠 密的监督信号.这类学习范式是机器学习中一类常 用的学习范式,通常被称为监督学习.监督学习假设 深度神经网络做出的分类或者回归的决策,与使用 的数据是相互独立的,即深度神经网络的输出不会 对数据集中样本点的分布造成影响.我们假设固定 的训练集构成了一个场景,无状态的场景表示无论 哪个时刻从该场景中采集样本数据,所得到的数据 分布都是相同的.因此监督学习的训练集可以看作 是一个无状态的场景.如果训练集是一个有状态的 场景,即模型的决策可以改变环境的状态,那么监 督学习在上一个数据集上训练完成的模型,在下一 轮训练时面对改变后的数据集,可能无法做出正确 的预测.现实世界中有许多任务都属于有状态的场景,如推荐算法会改变用户未来的行为,进而影响 未来的数据分布.扫地机器人一个原本安全的决策, 由于环境的随机性,可能会撞倒花瓶,这也会改变未 来的数据分布.在有状态的场景下进行决策通常被 建模为序列决策问题,该问题能够由马尔可夫决策 过程 (MarkovDecisionProcess,MDP)[11]进 行 建 模,而且能够借助强化学习(ReinforcementLearning, RL)方法来求解最优策略. 强化学习是一种经典的机器学习方法,其中一 个智能体(agent)或多个智能体与环境(environment) 不断交互来实现其长期累积回报最大化.智能体不 被告知应该选择和执行什么动作(action),需要通 过不断的试错和学习来获取它们的最优行为.其中, 智能体通过获得对理想动作的奖励(reward)和对不 理想动作的负奖励来学习.同时由于奖励可能会延 迟,智能体要在探索有可能产生更高的回报和利用 当前奖励最高的状态两者之间做出必要的权衡.强 化学习的最终目标是使智能体在与环境反复地互动 中学得一个最优策略(policy),该最优策略可以最大 化智能体整个互动过程中的期望累积奖励.然而,传 统 RL方法存在维度诅咒的缺点:随着状态空间和 动作空间维度的增加,算法的效率会降低.近年来, 随着深度学习的显著成功,强化学习和深度学习结 合形成了诸多深度强化学习(DeepReinforcement Learning,DRL)[12]方法,使人工智能在众多现实的 复杂序列决策任务取得超越人类水平的性能表现. 尽管如此,前期的工作主要关注单个智能体学习解 决序列决策任务的情景,即单智能体强化学习.然 而,在大量现实任务中,环境往往包括多个与环境互 动并同时学习的智能体,这类问题通常被称作多智 能体序列决策问题,如自动驾驶[13]和推荐系统[14-15] 等.为解决这些任务,多智能体强化学习(Multi-Agent ReinforcementLearning,MARL)应运而生. 多智能体强化学习是机器学习领域的重要理论 分支,其交叉融合强化学习、博弈论、控制论、社会心 理学等学科的方法,适用于解决各种复杂多智能体 序列决策问题.MARL结合深度学习形成的多智能 体深度强化学习方法(Multi-AgentDeepReinforcement Learning,MADRL)已被广泛运用于解决各类现实 问题如交通信号控制、自动驾驶、智慧医疗、推荐系 统等,具有广阔的应用前景.MADRL [16-18]不同于单 智能体DRL最重要的地方在于,环境的动态是由环 境中的所有因素以及所有智能体的共同行为决定 的.每个智能体都面临着环境的不平稳性问题:智能 体的最优策略随着其它智能体策略的变化而改变. 在多智能体系统中,维度诅咒问题也会变得更严重, 因为环境中每个增加的智能体都会使状态-动作空 间的维度增加.此外还有局部可观测性限制,信用分 配等问题[19-21].同时多智能体深度强化学习涉及合 作、竞争或混合合作竞争等不同的任务场景.在面对 不同的任务场景时,通常有不同的的解决方案. 由于 MADRL方法种类繁多且不断涌现,之前 的综述工作[22-24]或基于学习框架或基于问题与挑战 对现有的 MADRL进行分类与综述,或重点关注其 中的某一个分支如基于通信的方法或基于值函数分 解的方法.总体而言,我们认为目前缺乏一个比较系 统的多维度的分类方式,将主流的 MADRL 工作方 法尽可能的涵盖和归类.基于这个原因,在本文中, 我们从多个维度对 MADRL 方法进行系统的分类 和综述.在第2节中,我们回顾了单智能体强化学习 的相关背景知识.在第3节中,我们综述了多智能体 强化学习方法,展示提出的多个分类维度,并分析了 每个类别的最近工作.同时,重点总结了值函数分解 方法,基于通信的方法,以及基于图神经网络的方 法.在第4节中,我们综述了 MADRL 在各个领域 的应用.最后,我们讨论 MADRL 一些未重点介绍 但很有前景的方向.