

借助人工神经网络(Artificial Neural Network, ANN),深度强化学习在游戏、机器人等复杂控制任务中 取得了巨大的成功.然而,在认知能力与计算效率等方面,深度强化学习与大脑中的奖励学习机制相比仍存在着巨 大的差距.受大脑中基于脉冲的通信方式启发,脉冲神经网络(Spiking Neural Network, SNN)使用拟合生物神经 元机制的脉冲神经元模型进行计算,具有处理复杂时序数据的能力、极低的能耗以及较强的鲁棒性,并展现出了持 续学习的潜力.在神经形态工程以及类脑计算领域中,SNN受到了广泛的关注,被誉为是新一代的神经网络.通过 将SNN与强化学习相结合,脉冲强化学习算法被认为是发展人工大脑的一个可行途径,并能够有效解释生物大脑 中的发现.作为神经科学与人工智能的交叉学科,脉冲强化学习算法涵盖了一大批杰出的研究工作.根据对不同领 域的侧重,这些研究工作主要可以分为两大类:一类是以更好地理解大脑中的奖励学习机制为目的,用于解释动物 实验中的发现,并对大脑学习进行仿真,例如R-STDP学习规则;另一类则是以实际控制任务中的性能、功耗等具 体指标为导向,用作人工智能的一种鲁棒且低能耗的解决方案,在机器人、自主控制等领域具有巨大的应用潜力 . 本文首先介绍了脉冲强化学习算法的基础(即脉冲神经网络以及强化学习),然后对当前这两大类脉冲强化学习算 法的研究特点与研究进展等进行分析 .对于第一类算法,本文重点分析了利用三因素学习规则实现的强化学习算 法,并回顾了其生理学背景以及具体实现方式 . 根据在训练过程中是否使用 ANN,本文将第二类算法分为依托 ANN实现的脉冲强化学习算法与基于脉冲的直接强化学习算法,并率先对这一脉冲强化学习算法的最新进展进行 了系统性的梳理与分析,同时全面展示了在深度强化学习算法中应用SNN的不同方式.最后,本文对该领域的研究 挑战以及后续研究方向进行了深入地探讨,总结了当前研究的优势与不足,并对其未来对神经科学以及人工智能领 域可能产生的影响进行展望,以吸引更多研究人士参与这个新兴方向的交流与合作.
神经科学在人工智能(Artificial Intelligence, AI)发展史上扮演了重要的角色,许多经典神经网 络结构的出发点都是为了理解大脑的工作机制[1-3] . 此外,神经科学不仅可以为已存在的AI技术提供生 物学解释[4-7] ,还可以为构建人工大脑时所需的新算 法与新架构提供丰富的灵感来源[8-10] . 近些年来,随 着计算机算力的增强以及大数据的积累,以深度学 习[11] 为代表的人工智能领域得到了蓬勃的发展. 然 而,现有的计算系统执行相同的任务所需要的能耗 往往要比人脑高出至少一个数量级[12] . 因此,AI 研 究人员将目光转回大脑,对神经元之间脉冲驱动的通信方式产生了极大的兴趣 . 在人脑的指引下,通 过脉冲驱动通信实现的神经元-突触硬件计算系统 有望解决当前深度学习算法面临的高能耗问题[13] . 这种神经形态计算技术[14] 始于 20 世纪 80 年代,并 在21世纪初期促成了大规模神经形态芯片的出现, 例如IBM的TrueNorth芯片[15] 、Intel的Loihi芯片[16] 以及英国曼彻斯特大学的 SpiNNaker 芯片[17] . 通过 采用存算一体的架构,神经形态芯片解决了传统 冯·诺依曼计算架构中处理单元与存储单元物理分 离(存算分离)的固有缺陷,从而减轻“内存墙瓶颈” 对计算吞吐量和能源效率的影响,将硬件功耗降低 到毫瓦级[13] .
在硬件不断发展的同时,相关的算法也在不断 协同演化. 通过将生物神经元之间通信的稀疏脉冲 信号和事件驱动的性质抽象为神经单元,生物学合 理的脉冲神经元模型[18] 被应用到神经网络之中,由 此诞生了脉冲神经网络(Spiking Neural Network, SNN). SNN 是为了弥合神经科学与机器学习之间 的差异而设计的新一代神经网络[19] ,被认为是人工 智能硬件实现的一种极具前景的解决方案[13] . SNN 与目前流行的神经网络和机器学习方法有着根本上 的不同,即其使用脉冲,而非常见的浮点值进行学 习 . 脉冲是一种发生在时间点上的离散事件,一般 可以由0和1进行表示,与生物神经元中的动作电位 (Action Potential)相对应 . 通常来说,SNN 的输入 和输出均为脉冲序列,神经元之间通过突触进行连 接 . 理论分析表明,SNN 在计算性能上与常规神经 元模型相当[19] . 由于其处理复杂时序数据的能力、 极低的能耗[13] 以及深厚的生理学基础[20] ,SNN受到 了广大学者的关注,在图像分类[21-23] 、目标识别[24-25] 、 语音识别[26-27] 以及其他领域[28-30] 上取得了飞速的发 展,展现出了极强的上升势头 . 最近的研究表明, SNN 在许多领域接近或达到了与经典人工神经网 络(Artificial Neural Network, ANN)相 当 的 性 能[21,27] . 相比 ANN,SNN 还表现出了较强的鲁棒 性 . 首先,脉冲神经元动态中的随机性可以提高网 络对外部噪声的鲁棒性[31] . 其次,近期有研究表明 脉冲神经元的发放机制使得 SNN 之于对抗攻击存 在内在的鲁棒性[32] . 此外,生物体的一生都在从与 环境之间的交互中学习,而人工系统若要在现实世 界中行动和适应,同样需要能够实现持续学习 (Continual Learning)[33] . 为了解决这一难题,许多生 物学启发的模型以及机制被应用到人工系统中,并 取得了不错的效果[34] . 由于额外的时间维度,SNN 被认为具有实现持续学习的潜力[35-36] .
尽管深度学习在很多领域都取得了突破性的成 就,达到甚至超过了人类水平,为 SNN 设下了很高 的竞争门槛 . 研究表明,相比于目前已经较为成熟 的计算机视觉任务,SNN 能够在机器人、自主控制 等领域取得优于深度学习的表现[13,37] . 在这些领域 中,传统深度学习算法需要的大量计算资源在处理 实际问题时往往难以满足,而借助专用的神经形态 硬件,SNN 能够极大地降低任务所需的能耗,这与 移动设备上有限的主板能量资源之间具有天然适 配性.
强化学习(Reinforcement Learning, RL)作为 AI研究的一个重要分支,用于解决在智能体与环境 交互过程中的序列决策问题,通过学习策略以实现 期望未来奖励最大化,并且已经在广泛的控制任务 上证明了其有效性[10,38-40]. 因此,通过将SNN与强化 学习相结合,脉冲强化学习算法[41-43] 为连续控制任 务提供了一种低能耗的解决方案,已经被广泛应用 在车辆、机器人等移动设备的控制任务中[29,44] ,受到 了 不 少 学 者 的 关 注 . 同 时,借 助 神 经 形 态 传 感 器[45-46] ,脉冲强化学习算法能够充分利用多模态的 脉冲序列数据,令智能体像人脑一样进行感知与决 策,为仿生机器人的研究提供了一个可行的解决方 案[44] . 更令人惊喜的是,脉冲强化学习算法能够有 效解决强化学习中的鲁棒性问题[43,47] ,这是决定策 略是否实用的关键因素.
此外,强化学习在诞生初期就与动物学习中心 理学中的试错法以及神经科学中大脑的奖励学习机 制密切相关,其中最显著的联系就是时序差分 (Temporal Difference, TD)误差与多巴胺之间的相 似关系,这被归纳为多巴胺的奖励预测误差假说[48] . 多巴胺的奖励预测误差假说认为,多巴胺的功能之 一就是将未来期望奖励的新旧估计值之间的误差传 递给大脑中的所有目标区域. 这一假说利用强化学 习中的 TD 误差概念,成功解释了哺乳动物中多巴 胺神经元的相位活动特征 . 在计算神经科学领域 里,大量的研究工作利用强化学习算法对大脑的奖 励学习机制进行建模[49-51] ,这些都属于脉冲强化学 习算法的研究范畴. 综上所述,脉冲强化学习算法不仅是脉冲神经 网络与强化学习算法的有机结合,还是连通神经科 学与AI两个领域的桥梁. 根据时间顺序,脉冲强化 学习算法的发展历程可以被分为三个时期:SNN与 强化学习的基础研究时期、基于突触可塑性的脉冲强化学习算法时期以及深度强化学习算法与SNN的 结合时期,如图1所示. 在基础研究时期,图1列举了 SNN与强化学习各自的一些早期代表性工作,这些 工作为后续脉冲强化学习算法的诞生与发展奠定了 基础. 以深度学习的兴起为时间节点,脉冲强化学习 算法有着明显的不同. 早期的算法注重突触可塑性 与强化学习理论的结合,而后期的算法侧重于将 SNN应用到深度强化学习算法中. 由此,图1进一步 地划分出了两个时期,分别列举了脉冲强化学习算 法在早期与晚期的代表性工作. 尽管近些年也出现 了一些优秀的突触可塑性算法(例如e-prop[52] ),但这 已经不是计算机科学领域的主流,所以未被列入图1 中. 由于图的大小有限,部分SNN与强化学习的经 典工作并未在图中展现,这将在本文的后续章节中 进行更为系统的梳理 . 此外,出于美观考虑,图 1根 据事件线分为上下两侧,不存在事件类型的区别.
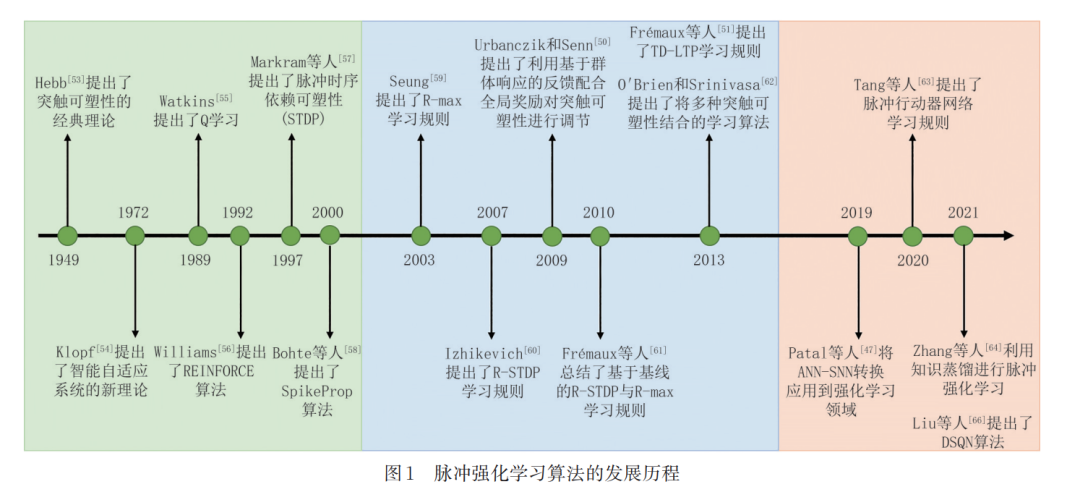
关于相关工作在脉冲强化学习算法的发展历程 中的地位以及作用,其概述如下:1949 年 Hebb[53] 提 出了突触可塑性的经典理论,对突触可塑性的基本 原理进行了描述 . 1972 年 Klopf [54] 提出了智能自适 应系统的新理论,其中的一系列思想促成了资格迹 (Eligibility Trace)在强化学习中的应用[48] . 1989 年 Watkins[55] 提出了Q学习,这是强化学习早期的一个 重要突破,实现了异策(Off-policy)[48] 下的时序差分 控制 . 1992 年 Williams[56] 提出了 REINFORCE 算 法,这是一个经典的策略梯度算法,动作选择不再直 接依赖于价值函数,而是可以直接学习参数化的策 略. 1997年Markram等人[57] 提出了一个较为通用的 SNN 学习规则,即脉冲时序依赖可塑性(Spiketiming-dependent Plasticity, STDP),这是无监督学 习的重要生物学基础 . 2000 年 Bohte 等人[58] 提出了 SpikeProp 算法,首次使用误差反向传播对 SNN 进 行训练 . 2003 年 Seung[59] 基于策略梯度算法提出了 R-max学习规则. 2007年Izhikevich[60] 受到动物学实 验的发现启发,提出了 R-STDP 学习规则 . 2009 年 Urbanczik 和 Senn[50] 提出了利用基于群体响应的反 馈配合全局奖励对突触可塑性进行调节,丰富了三 因素学习规则中全局信号的选择范围 . 2010 年 Frémaux 等人[61] 总结了基于基线的 R-STDP 与 Rmax 学习规则,利用基线函数对原本的学习规则进 行 改 进,使 其 能 够 同 时 学 习 多 个 任 务 . 2013 年 Frémaux 等人[51] 提出了 TD-LTP 学习规则,成功解 决了如何在非离散框架下实现强化学习以及如何在 神经元中计算奖励预测误差的问题 . O'Brien 和 Srinivasa[62] 提出了将多种突触可塑性结合的学习算 法以解决同时学习多个远端奖励的问题 . Patal 等 人[47] 首次将 ANN-SNN 转换应用到强化学习领域, 避免了强化学习直接训练 SNN 的困难,并证明了 SNN 能够提高模型对于遮挡的鲁棒性 . Tang 等 人[63] 提 出 了 一 个 混 合 的 行 动 器 -评 判 器(ActorCritic)网络,对脉冲行动器网络与深度评判器网络 进行联合训练,证明了脉冲行动器网络可以作为原 本深度行动器网络的一个低能耗替代方案 . Zhang 等人[64] 受到知识蒸馏[65] 启发,提出了一种间接训练 SNN 的方法,利用强化学习训练得到的 ANN 教师 网络指导 SNN 学生网络的学习 . Liu等人[66] 提出了DSQN 算法,摆脱了原本的深度脉冲强化学习算法 在训练过程中对ANN的依赖. 由于脉冲强化学习算法的领域交叉性,脉冲强 化学习算法的研究在脉冲神经网络与强化学习算法 的文献综述中少有提及 . 例如 Taherkhani等人[67] 简 单提及了基于奖励的突触可塑性学习 . Hu 等人[68] 介绍了三因素学习规则. Sutton和Barto[48] 阐述了神 经科学中大脑奖励系统与强化学习理论之间的对应 关系,并对神经科学与强化学习如何相互影响进行 了讨论 . 此外,之前关于脉冲强化学习算法的综述 由于时间较早,其关注的都是与突触可塑性相关的 内容 . 例如 Frémaux 和 Gerstner[69] 系统总结了利用 三因素学习规则实现的强化学习算法. Bing等人[37] 介绍了利用三因素学习规则实现的强化学习算法及 其相应的机器人应用.
本文首先介绍了SNN与强化学习的基本原理, 然后以SNN学习算法的分类为基础,从更长的时间 线对传统的利用三因素学习规则实现的强化学习算 法与近些年来出现的新型脉冲强化学习算法进行了 系统性回顾与综述 . 不同于已有的综述,本文率先 对依托 ANN 实现的脉冲强化学习算法与基于脉冲 的直接强化学习算法进行了系统梳理与全面总结, 并介绍了最新的研究挑战与未来研究方向 . 最后, 本文对脉冲强化学习算法的优点与不足进行了总 结,并展望了其对未来人工智能和神经科学领域的 潜在影响,希望通过跨学科的交流与合作,推动该领 域的快速发展.

