学会原创 | 自然语言的语义表示学习方法与应用

引言
近年来,以深度学习为代表的表示学习技术在语音识别、图像分析和自然语言处理(NLP)领域获得了广泛关注。表示学习旨在将研究对象的语义信息表示为低维稠密实值向量。表示学习得到的低维向量表示是一种分布式表示,孤立地看向量中的每一维,都没有明确对应的含义;而综合各维形成一个向量,则能够表示对象的语义信息。
与更简单的独热(one-hot)表示方法相比,表示学习的向量维度较低,有助于提高计算效率,同时能够充分利用对象间的语义信息,从而有效缓解数据稀疏问题。由于表示学习的这些优点,最近出现了大量关于单词、短语、实体、句子、文档和社会网络的表示学习研究。
1
自然语言的词表示方法
在NLP 中,文本表示是一个极为关键的问题。最初,词袋模型是最常用的文本表示模型之一。随着深度神经网络的兴起,人们提出了一种新的获得词向量的词嵌入(Word Embedding)方法[1-3],以解决词汇表过大带来的“维度爆炸”问题。词和句子的嵌入已成为所有基于深度学习的NLP系统的重要组成部分,它们在固定长度的稠密向量中编码单词和句子,从而大幅度提高神经网络处理文本数据的能力。词向量的获取方式可以大体分为基于统计的方法(例如基于共现矩阵、SVD)和基于语言模型[4-5] 的方法两类。2013 年,Google 团队发表了基于语言模型获取词向量的word2vec工具[6]。它的核心思想是通过词的上下文得到词的向量化表示,包括CBOW(通过附近词预测中心词)和Skip-gram(通过中心词预测附近词)两种方法,以及负采样和层次softmax 两种近似训练法。word2vec 的词向量可以较好地表达不同词之间的相似和类比关系,自提出后被广泛应用在NLP任务中。进一步地,由于word2vec 的词向量是固定不变的,不能有效地解决多义词的问题,产生了根据上下文随时变化词向量的ELMO 模型[7]。该模型从深层的双向语言模型的内部状态学习得到词的表示,能够处理单词用法中的复杂特性,以及这些用法在不同的语言上下文中的变化,从而解决了多义词的问题。
2
自然语言的结构表示方法
在获取句子或文档的语义表示时,一段话的语义由其各组成部分的语义,以及它们之间的组合方法所确定[8]。由此,一些工作开始尝试根据输入的结构设计模型的结构。比如卷积神经网络(CNN)以n-gram作为基本单位建立句子表示[9-10]。而递归神经网络(Recursive Neural Network) 则根据输入的树结构构建句子的表示[11-12]。此外,循环神经网络(RNN)及各种改进(如长短时记忆网络(LSTM))被证明是有效的句子级别表示方法[13]。在此基础上,一些更为优越的结构增强型LSTM 和之前模型的各种组合的方法也在之后被提出。事实上,LSTM 引入一个近似线性依赖的记忆单元来存储远距离的信息,以解决简单RNN 的长期依赖问题。记忆单元的存储能力和其大小有关,增加记忆单元的大小将导致网络参数的增加。针对这种情况,产生了注意力机制和外部记忆的改进方法。其中注意力机制[14] 是近年来在NLP 任务中被广泛应用的一种十分有效的技术,在诸多领域都展示出了其优越性。进一步地,产生了一种只基于注意力机制对序列进行表示的Transformer 结构[15]。它摒弃了固有的定式,没有使用任何CNN 或者RNN 的结构。Transformer 可以综合考虑句子两个方向的信息,而且有很好的并行性质,可以大大减少训练时间。
3
预训练在NLP 中的应用
值得一提的是,很多自然语言特征表示方法及词表示方法都采用一种两阶段的训练方法,即首先在无标记数据上通过预训练学习特征或者词的表示;再以这些表示作为特征,在标记数据上进行监督训练。前文所提到的word2vec 和ELMO 方法就经常被用于词向量的预训练。随着深度学习在表示学习领域成为主流方法,以及Transformer等序列表示模型的发展,自然语言的表示学习从特征和词的粒度被推广到了更大的粒度,如短语和句子。这些深度学习模型也同样受益于这种两阶段的训练方法。在ELMO 之后,新的语言表征预训练模型GPT 使用Transformer 来编码[16], 克服了ELMO 使用LSTM 作为语言模型而带来的并行计算能力差的缺点。而BERT 模型在采用Transformer 进行编码的同时双向综合地考虑上下文特征来对词进行预测[17]。与word2vec 和ELMO 不同,GPT 和BERT 在进行第一阶段的预训练之后只需要根据第二阶段的任务对模型结构进行改造,精加工(fine-tuning)模型进行监督训练,使之适用于具体的任务。BERT 具有很强的普适性,几乎所有 NLP 任务都可以套用这种两阶段解决思路,并且获得效果的明显提升。
4
其他NLP 表示学习方法与应用
除了上文中通用的NLP 表示学习方法,自然语言仍存在很多性质需要进行深入研究。例如,汉语具有部首共享和汉字共享的特殊性质,即几个汉字共同的部首通常是它们之间的核心语义关联;相应地,一个汉语词的意思可以通过其包含的汉字来表达。如图1所示,基于部首感知和注意力机制的四粒度模型RAFG[18] 对这两种性质加以挖掘和利用,并将这些特征系统地融入到中文文本分类的任务中,从而实现对中文文本更为准确的语义表示。
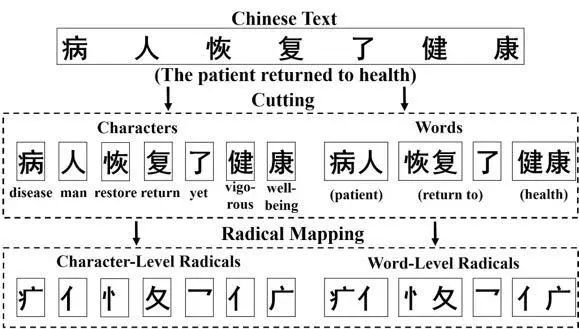
图1:RAFG 获得中文文本四个粒度特征的说明
此外,语言所处的环境信息(如图像)会对语言的语义产生影响。进一步地,图像所包含的信息可能与句子语义的不同的粒度表示有关联。为此,如图2所示,图像增强的层次化句子语义表示网络IEMLRN[19]利用图像信息从不同粒度来增强句子的语义理解与表示,实现了更为准确的句子语义表示,以及句子对的语义关系分类。
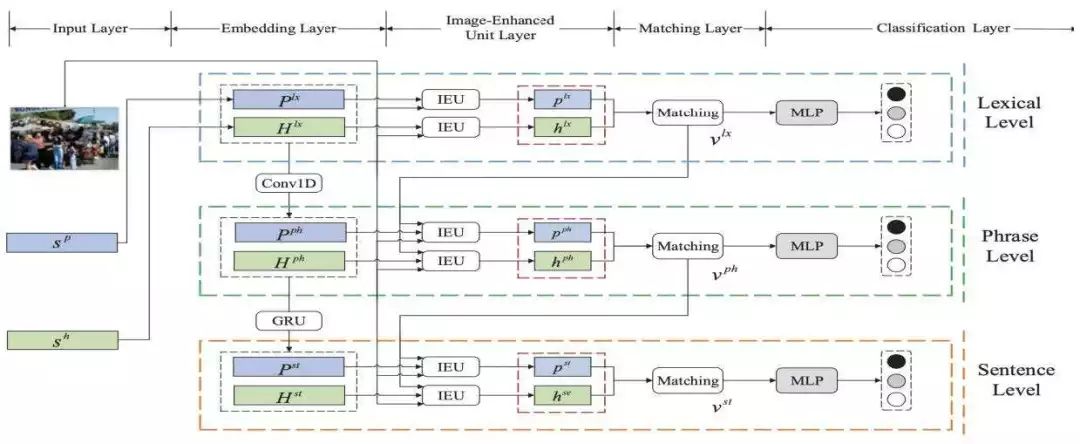
图2:图像增强的层次化句子语义表示网络IEMLRN结构
最后,语义表示技术的发展使得多媒体信息的有效建模与语义表示成为可能,进而为推荐、检索等实际应用场景提供支撑。近年来,多媒体共享平台取得了突飞猛进的发展。其中一种叫做“弹幕”的视频实时评论愈发流行。为了有效理解视频片段的内容,如图3 所示,基于深度神经网络的弹幕语义表征方法[20] 通过利用弹幕与视频情节之间的关联性,对弹幕进行表示学习,实现了对视频片段的标注。这种方法突破了常规视频推荐/ 检索系统只关注整段视频的局限性,可以满足细粒度的要求。
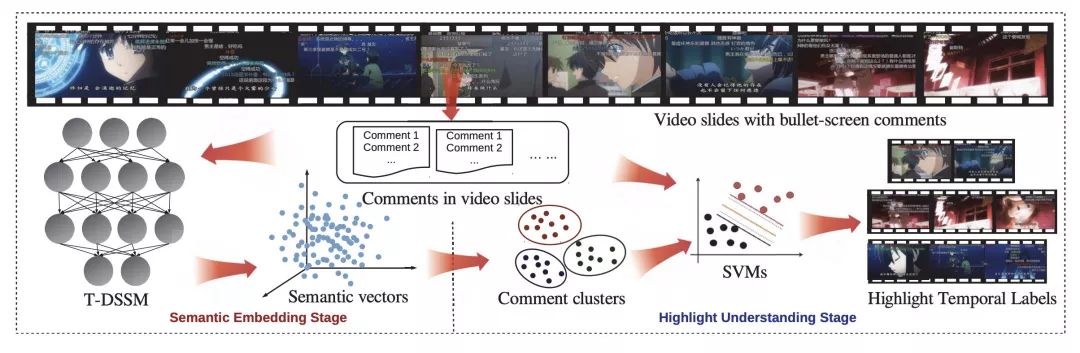
图3:基于弹幕语义表征的视频片段标注框架会对语言的语义产生影响
5
结束语
自然语言的语义表示学习方法的发展为各种NLP 任务带来了更多的可能性。新型网络结构的出现使我们可以得到更加有效的语义表征。而两阶段的预训练方法可以把大量的无标注文本利用起来,对大量的通用语言学知识进行抽取与表示,从而提升NLP 下游任务的效果。
自然语言的语义表示学习方法取得了令人瞩目的成就,但在很多方面都仍值得继续研究。无论是更强的特征抽取器还是引入大量数据中包含的语言学知识,对更加精确的语义表示都有着重要作用。尽管现有的很多NLP 任务还无法达到人类的水平, 但相信对自然语言语义表征的不断研究、新技术的不断出现,会创造出更丰富的成果。
参考文献
[1] Turian, J.; Ratinov, L.; and Bengio, Y. 2010. Word representations: a simple and general method for semi-supervised learning[C]. In ACL2010.
[2] Melamud O, Levy O, Dagan I, et al. A simple word embedding model for lexical substitution[C].Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing. 2015: 1-7.
[3] Palangi H, Deng L, Shen Y, et al. Deep sentence embedding using long short-term memory networks: Analysis and application to information retrieval[J]. IEEE/ACM Transactions on Audio, Speech and Language Processing (TASLP), 2016, 24(4): 694-707.
[4] Yoshua Bengio, Réjean Ducharme, and Pascal Vincent. A neural probabilistic language model[C]. In NIPS2001.
[5] Yoshua Bengio, Réjean Ducharme, et al.. A Neural Probabilistic Language Model[J]. The Journal of Machine Learning Research, 3:1137–1155, 2003.
[6] Tomas Mikolov, Ilya Sutskever, et al. Distributed representations of words and phrases and their compositionality[C]. In NIPS2013.
[7] Matthew E. Peters, Mark Neumann, et al. Deep contextualized word representations[C]. In NAACL2018.
[8] Gottlob Frege. On Sense and Reference. Function - Term - Meaning, 1892.
[9] Nal Kalchbrenner, Edward Grefenstette, and Phil Blunsom. A convolutional neural network for modelling sentences[C]. In ACL2014.
[10] Yoon Kim. Convolutional neural networks for sentence classification[C]. In EMNLP2014.
[11] Richard Socher, Eric H Huang, et al.. Dynamic pooling and unfolding recursive autoencoders for paraphrase detection[C]. In NIPS2011.
[12] Richard Socher, Alex Perelygin, et al. Recursive deep models for semantic compositionality over a sentiment treebank[C]. In EMNLP13.
[13] Ilya Sutskever, Oriol Vinyals, Quoc V. Le, Sequence to Sequence Learning with Neural Networks[C] In NIPS2014.
[14] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate[C]. In ICLR2015.
[15] Ashish Vaswani, Noam Shazeer, et al. Attention is All You Need[C]. In NIPS2017.
[16] Alec Radford, Karthik Narasimhan, et al. Improving Language Understanding by Generative Pre-Training.
[17] Jacob Devlin, Ming-Wei Chang, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv preprint arXiv:1810.04805, 2018.
[18] Hanqing Tao, Shiwei Tong, et al. A Radical-aware Attention-based Model for Chinese Text Classification[C], In AAAI2019.
[19] Kun Zhang, Guangyi Lv, et al. Image-Enhanced Multi-Level Sentence Representation Net for Natural Language Inference[C], In ICDM2018.
[20] Guangyi Lv, Tong Xu, et al. Reading the Videos: Temporal Labeling for Crowdsourced Time-Sync Videos based on Semantic Embedding[C], In AAAI2016.
作者简介





文 | 原刊于中国人工智能学会通讯 2019年 第9卷 第01期





