

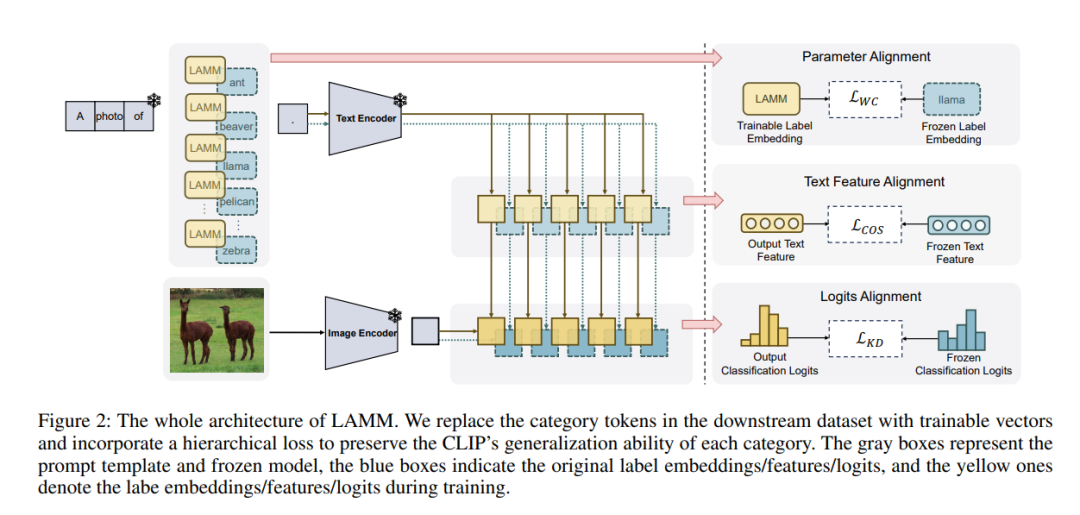
随着CLIP等预训练视觉-语言(VL)模型在视觉表示任务中的成功,将预训练模型迁移到下游任务已成为一个关键范式。最近,源自自然语言处理(NLP)的提示调整范式在VL领域取得了显著进展。然而,早期方法主要集中于为文本和视觉输入构建提示模板,忽略了VL模型与下游任务之间类别标签表示的差距。为了应对这一挑战,我们引入了一种名为LAMM的创新标签对齐方法,可以通过端到端训练动态调整下游数据集的类别嵌入。此外,为了实现更合适的标签分布,我们提出了一个分层损失,包括参数空间、特征空间和逻辑空间的对齐。我们在11个下游视觉数据集上进行了实验,并证明了我们的方法显著提高了现有多模态提示学习模型在小样本场景中的性能,与最先进方法相比,在16次射击上平均准确率提高了2.31(%)。此外,我们的方法在持续学习方面与其他提示调整方法相比显示出了优势。重要的是,我们的方法与现有的提示调整方法是协同的,并可以在它们的基础上提高性能。我们的代码和数据集将在https://github.com/gaojingsheng/LAMM上公开。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
224+阅读 · 2023年4月7日