

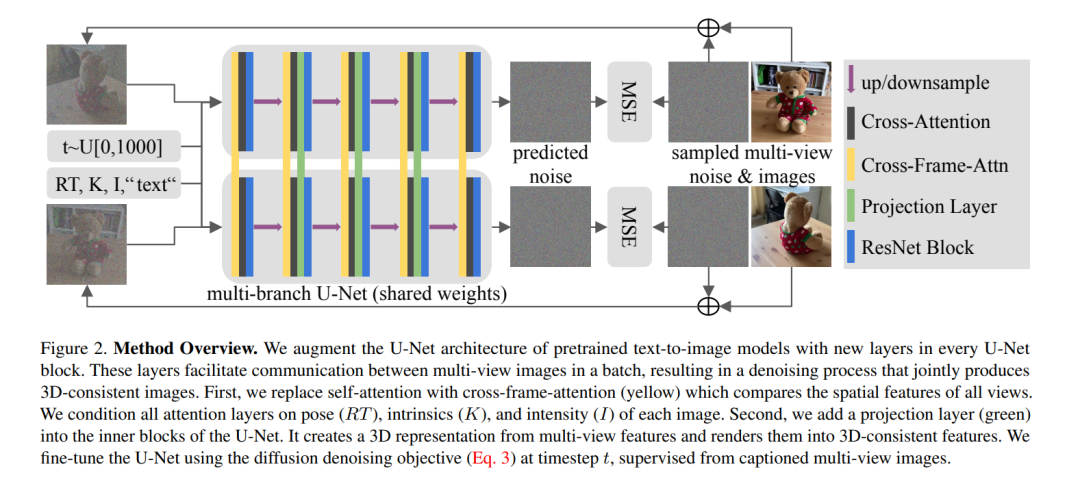
3D资产生成正在受到大量关注,这一趋势受到了最近文本引导的2D内容创造成功的启发。现有的文本到3D方法使用预训练的文本到图片扩散模型在一个优化问题中使用或对其在合成数据上进行微调,这通常会导致非真实感的3D对象而没有背景。在这篇论文中,我们提出了一种方法,利用预训练的文本到图片模型作为先验,并学习在单一去噪过程中从真实世界数据生成多视图图像。具体来说,我们提议将3D体积渲染和跨帧注意力层集成到现有文本到图片模型的U-Net网络的每个块中。此外,我们设计了一个自回归生成过程,能在任何视点渲染更具3D一致性的图像。我们在现实世界对象的数据集上训练我们的模型,并展示了它生成具有各种高质量形状和纹理在真实环境中实例的能力。与现有方法相比,我们方法生成的结果是一致的,并且具有较好的视觉质量(FID降低30%,KID降低37%)。
成为VIP会员查看完整内容
相关内容
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日
相关VIP内容
相关资讯
相关论文
Arxiv
42+阅读 · 2023年4月19日
Arxiv
223+阅读 · 2023年4月7日
Arxiv
86+阅读 · 2023年4月4日
Arxiv
152+阅读 · 2023年3月29日