当地时间 5 月 10 日上午,一年一度的谷歌 I/O 来了,加州山景城的海岸圆形剧场座无虚席,今年的大会正式开幕。PaLM 二代模型****支持多语言、更强的数学、代码能力
首先,谷歌给出了自己对标 GPT-4 的大模型 PaLM 2。 要说这一波 AI 技术突破的源头,或许可以追溯到 2017 年谷歌提出的 transformer 架构,它已成为绝大多数现代大语言模型的基石。
在过去的几年里,谷歌除了在大模型上不断进步之外,也采用了许多创造性的新技术来构建功能更强大、用途更广的模型。这些技术是新一代语言模型 PaLM 2 的核心。PaLM 基于谷歌 Pathways 架构,其第一个版本的模型于 2022 年 4 月发布。
谷歌 I/O 大会上,皮查伊宣布推出 PaLM 2 预览版本,改进了数学、代码、推理、多语言翻译和自然语言生成能力,利用谷歌最新的 TPU 算力基础设施提升了训练速度。由于它的构建方式是将计算、优化扩展、改进的数据集混合以及模型架构改进结合在一起,因此服务效率更高,同时整体表现更好。

会上,谷歌并没有给出有关 PaLM 2 的具体技术细节,只说明了它是构建在谷歌最新 JAX 和 TPU v4 之上。PaLM 2 模型提供了不同尺寸规模的四个版本,从小到大依次为 Gecko、Otter、Bison 和 Unicorn,更易于针对各种用例进行部署。其中轻量级的 Gecko 模型可以在移动设备上运行,速度非常快,不联网也能在设备上运行出色的交互式应用程序。

皮查伊表示,PaLM 2 模型在常识推理、数学和逻辑领域表现更好。为此,谷歌在大量包含数学表达式的科学论文和网页上进行了训练,可以轻松解决数学难题、推理文本甚至可以输出图表。
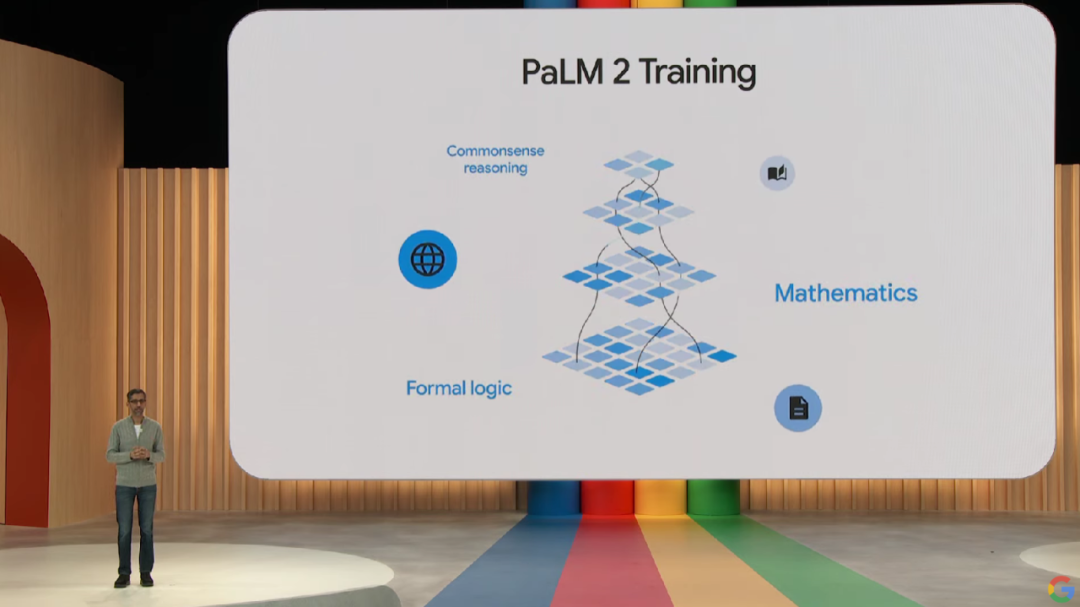
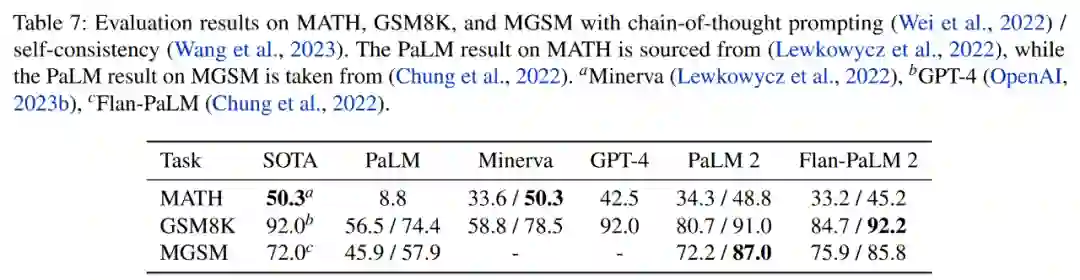
从基准测试上可以看到,对于具有思维链 prompt 或自洽性的 MATH、GSM8K 和 MGSM 基准评估,PaLM 2 的部分结果超越了 GPT-4。
PaLM 2 是在具有 100 + 语言的语料库上进行训练的,因此它更擅长多语言任务,能够理解、生成和翻译比以往模型更细致多样化的文本(包括习语、诗歌和谜语等)。PaLM 2 通过了「精通」(mastery)级别的高级语言能力考试。

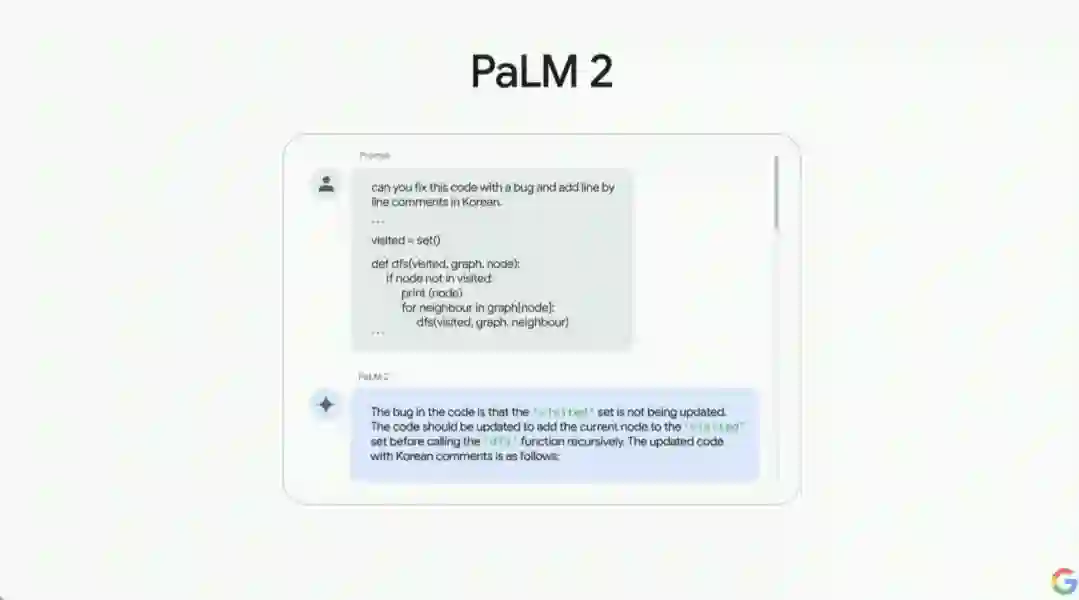
与此同时,PaLM 2 改进了对代码编写和调试的支持,在 20 种编程语言上进行了训练,包括 Python 和 JavaScript 等流行语言以及 Prolog、Verilog 和 Fortran 等其他更专业的语言。PaLM 2 构成了 Codey 的基础,它是谷歌用于编码和调试的专用模型,作为代码补全和生成服务的一部分推出。 皮查伊现场演示了 PaLM 2 的代码调试功能,输入指令「你能修复这段代码的一个 bug,并添加一行一行的韩文注释吗?」,结果如下动图所示。

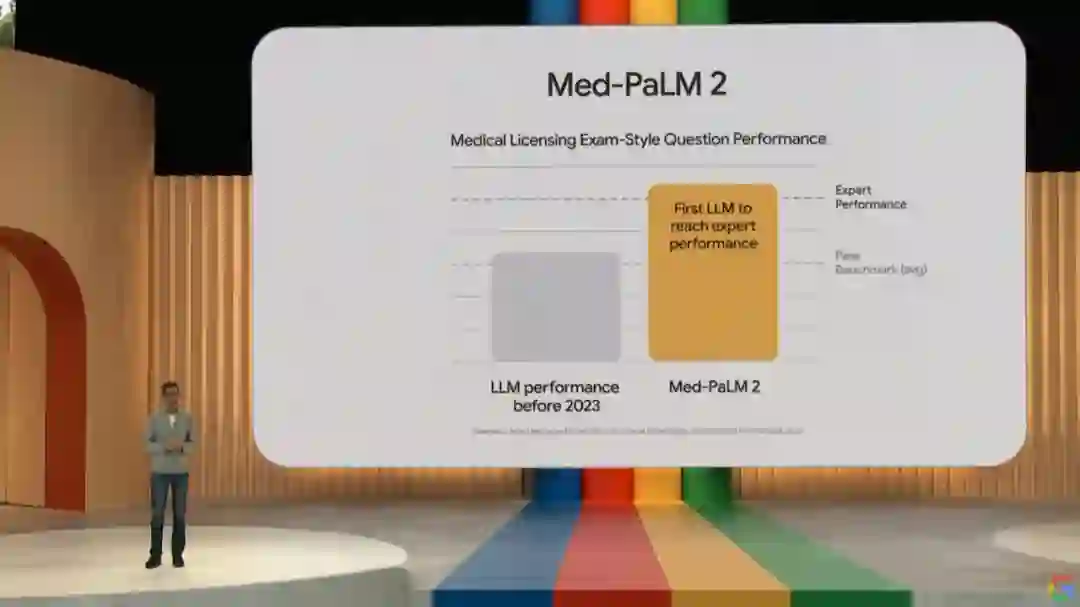
谷歌内部已经有超过 70 个产品团队正在使用 PaLM 2 构建产品,包括分别针对安全知识和医疗知识微调而成的 Sec-PaLM 和 Med-PaLM 2。
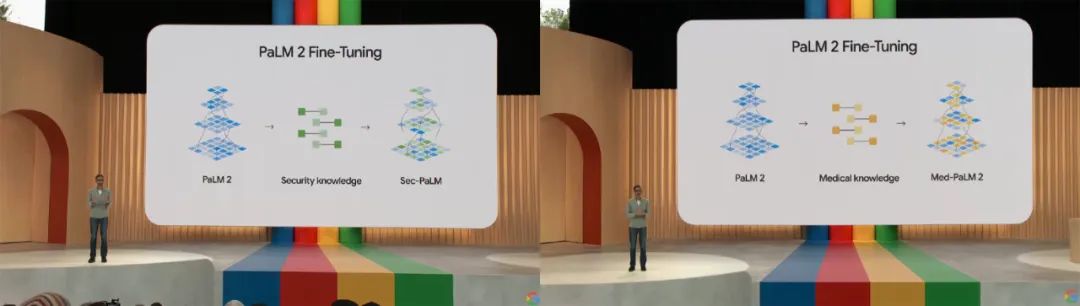
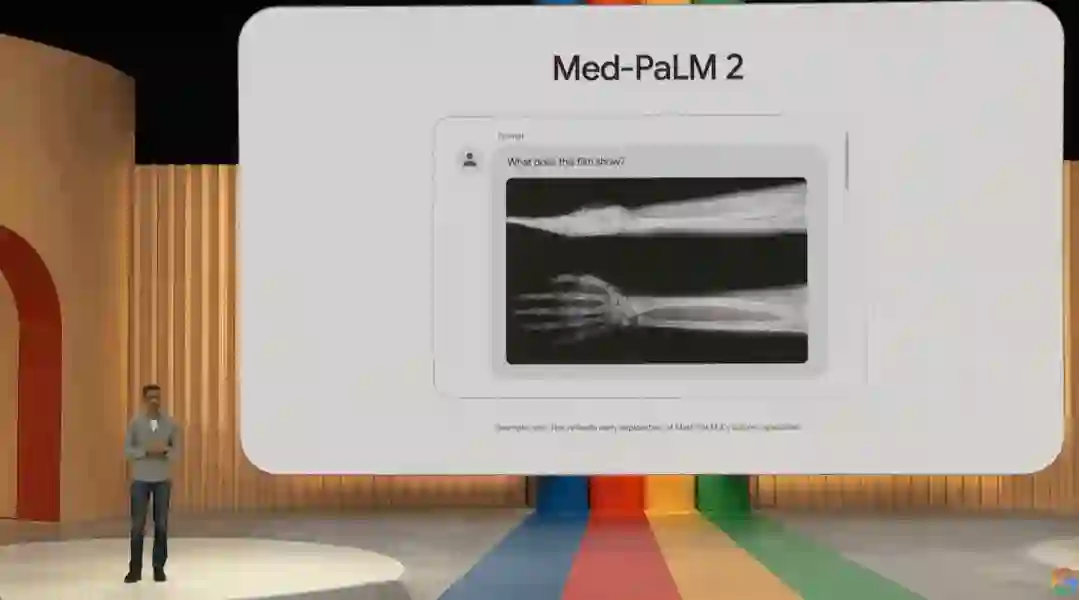
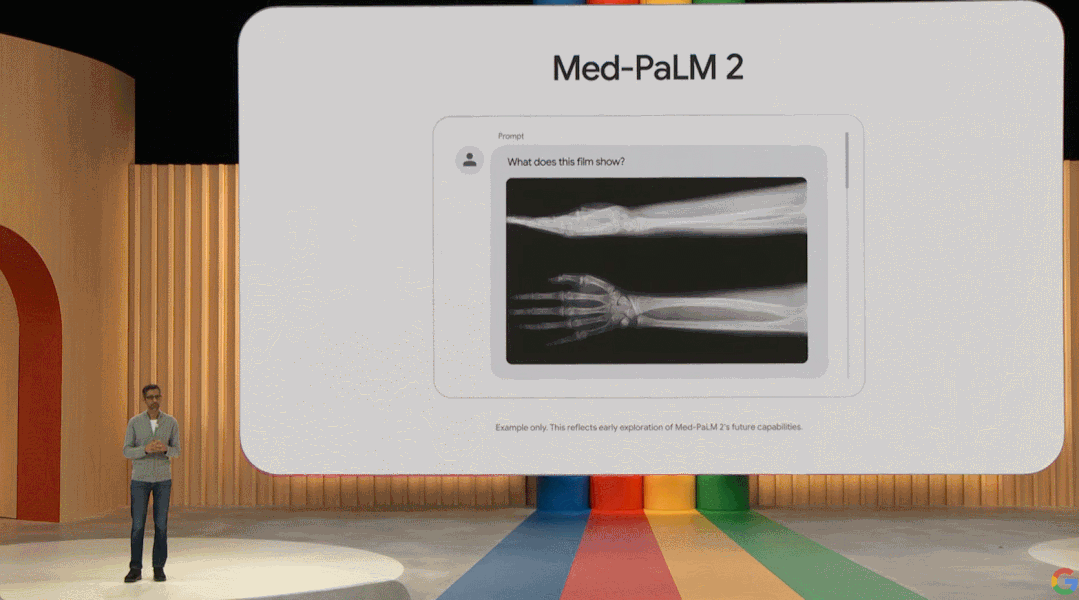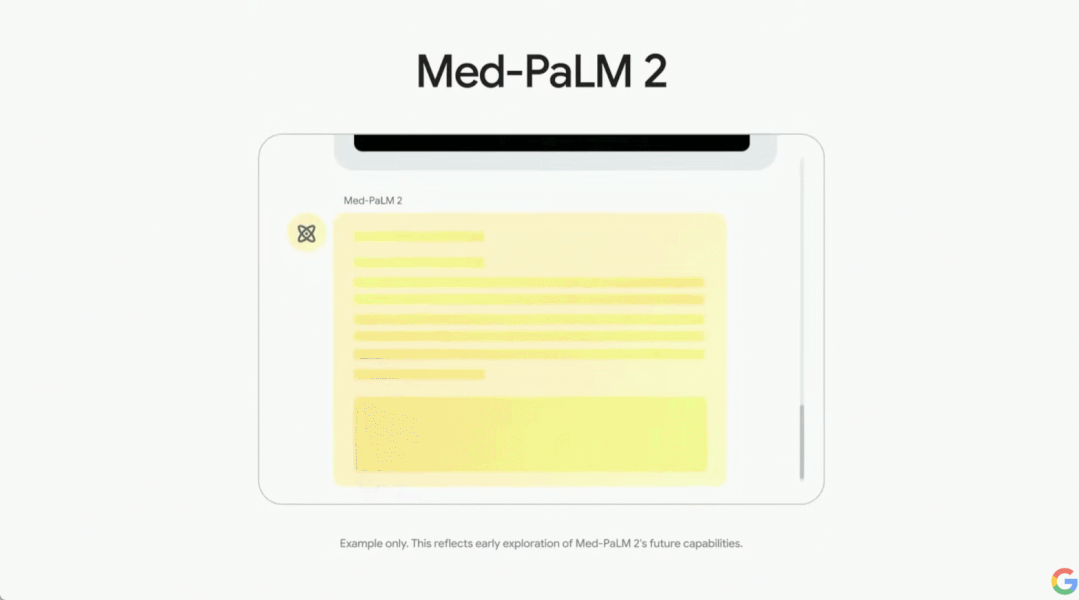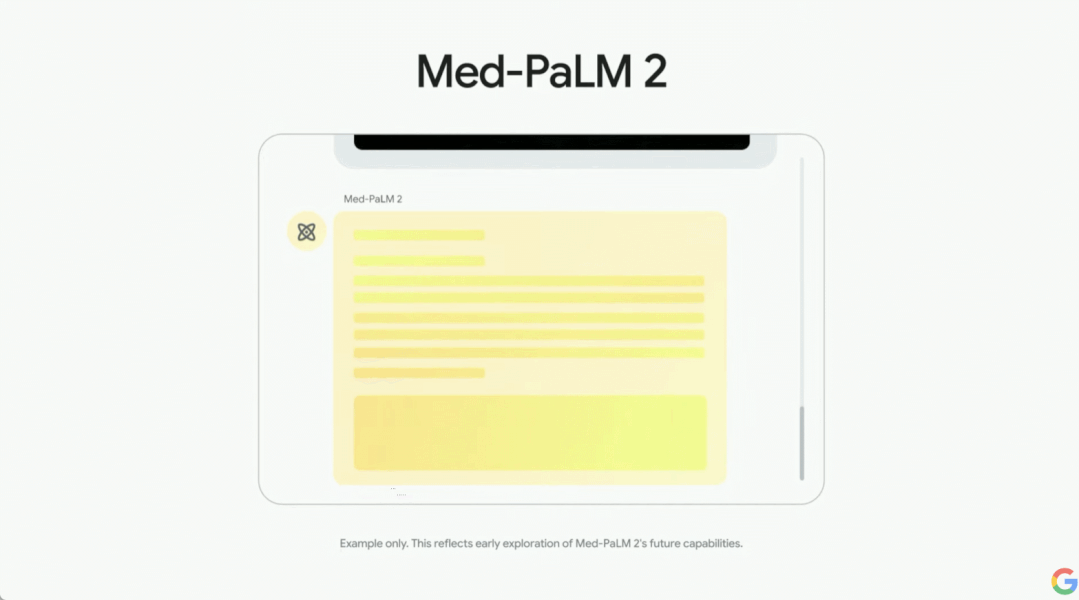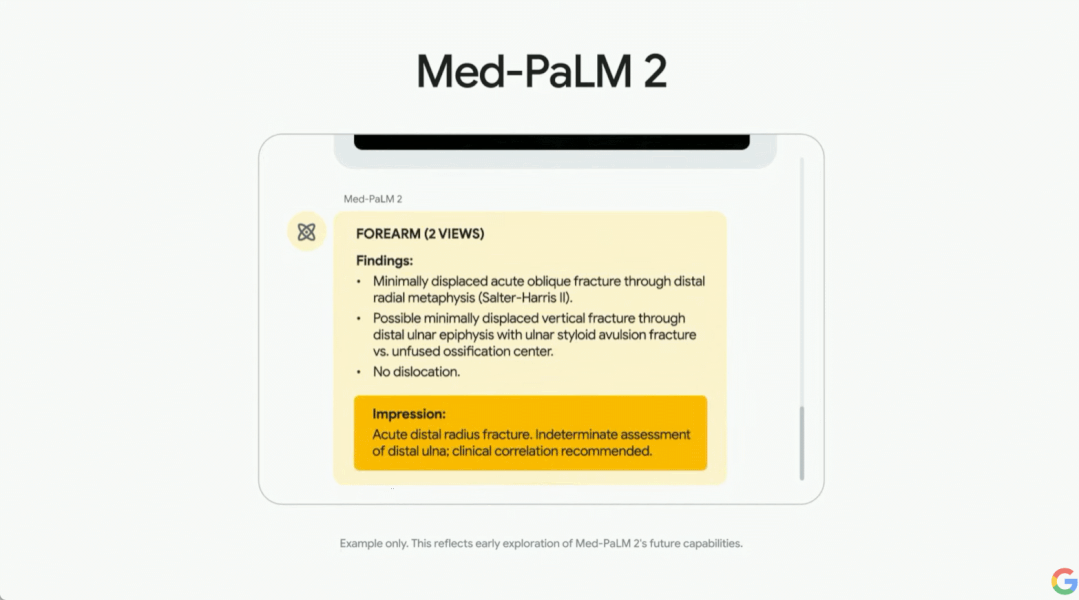
其中 Sec-PaLM 是专注于安全用例的版本,使用 AI 帮助分析和解释具有潜在恶意脚本的行为,并检测哪些脚本对个人或组织构成威胁。Med-PaLM 2 可以检索医学知识、回答问题、生成有用的模板和解码医学术语,甚至还可以从图像中合成患者信息,例如胸部 X 光检查或乳房 X 光检查。值得强调的是,Med-PaLM 2 是首个达到专家水平的大语言模型。

皮查伊在会上展示了 Med-PaLM 2 的医疗内容生成效果。
目前,开发者可以通过谷歌的 PaLM API、Firebase 以及 Colab 访问 PaLM 2。皮查伊还表示,PaLM 2 将继续为谷歌最新的 Bard 提供支持。 论文地址:https://ai.google/static/documents/palm2techreport.pdf
PaLM 2 技术报告

我们介绍了PaLM 2,这是一个全新的、具有更优秀的多语言和推理能力的语言模型,比其前任PaLM(Chowdhery等人,2022)更高效。PaLM 2是一个基于Transformer的模型,其训练使用的目标混合类似于UL2(Tay等人,2023)。通过对英语和多语言、以及推理任务的广泛评估,我们证明了PaLM 2在不同模型大小的下游任务上质量显著提升,同时相比于PaLM展示出更快、更高效的推理能力。这种改进的效率使得模型能够被更广泛地部署,同时也使模型能够更快地响应,为交互提供更自然的节奏。PaLM 2展示了强大的推理能力,这一点由其在BIG-Bench以及其他推理任务上相对于PaLM的大幅改进所证明。PaLM 2在一系列负责任的AI评估中表现稳定,并且能够在推理时控制毒性,无需额外的开销或影响其他能力。总的来说,PaLM 2在各种任务和能力上都实现了最先进的性能。自从Shannon(1951)通过预测下一个词来估算语言中的信息以来,语言建模一直是一个重要的研究领域。建模起初以n-gram为基础的方法(Kneser & Ney, 1995)开始,但随着LSTM(Hochreiter & Schmidhuber, 1997; Graves, 2014)的出现,其发展速度快速提升。后来的研究表明,语言建模也导致了语言理解的提升(Dai & Le, 2015)。随着规模的增大和Transformer架构(Vaswani等人,2017)的应用,过去几年大型语言模型(LLMs)在语言理解和生成能力上表现出了强大的性能,这导致在推理、数学、科学和语言任务中取得了突破性的成绩(Howard & Ruder, 2018; Brown等人,2020; Du等人,2022; Chowdhery等人,2022; Rae等人,2021; Lewkowycz等人,2022; Tay等人,2023; OpenAI, 2023b)。在这些进步中,关键的因素包括模型规模(Brown等人,2020; Rae等人,2021)和数据量(Hoffmann等人,2022)的扩大。到目前为止,大多数LLMs主要遵循一种标准的配方,即主要使用单语语料库并配合语言建模目标。我们介绍了PaLM 2,这是PaLM(Chowdhery等人,2022)的后继者,这是一个将建模进步、数据改进和规模洞察力统一起来的语言模型。PaLM 2融合了以下各种研究进步:
• 计算最优缩放:最近,计算最优缩放(Hoffmann等人,2022)表明,数据大小至少与模型大小同等重要。我们验证了这项研究对更大计算量的适用性,并同样发现,为了达到给定训练计算量的最佳性能,数据和模型大小应大致按1:1的比例缩放(这与过去的趋势不同,过去的趋势是模型的缩放速度比数据集快3倍)。
• 改进的数据集混合:之前的大型预训练语言模型通常使用由英文文本主导的数据集(例如,Chowdhery等人(2022)的非代码部分约占78%)。我们设计了一个更具多语言和多样性的预训练混合,它涵盖了数百种语言和领域(例如,编程语言、数学和平行多语言文档)。我们证明,较大的模型可以处理更多不同的非英语数据集,而不会导致英语理解性能的下降,并应用去重复来减少记忆(Lee等人,2021)
•** 架构和目标的改进**:我们的模型架构基于Transformer。过去的LLMs几乎都独自使用一个因果或掩蔽语言建模目标。鉴于UL2(Tay等人,2023)的强大结果,我们在这个模型中使用调优的不同预训练目标的混合,以训练模型理解语言的不同方面。
中文版