GitHub超9千星:一个API调用27个NLP预训练模型

新智元报道
新智元报道
来源:GitHub
编辑:元子
【新智元导读】只需一个API,直接调用BERT, GPT, GPT-2, Transfo-XL, XLNet, XLM等6大框架,包含了27个预训练模型。简单易用,功能强大。
One API to rule them all。
前几日,著名最先进的自然语言处理预训练模型库项目pytorch-pretrained-bert改名Pytorch-Transformers重装袭来,1.0.0版横空出世。
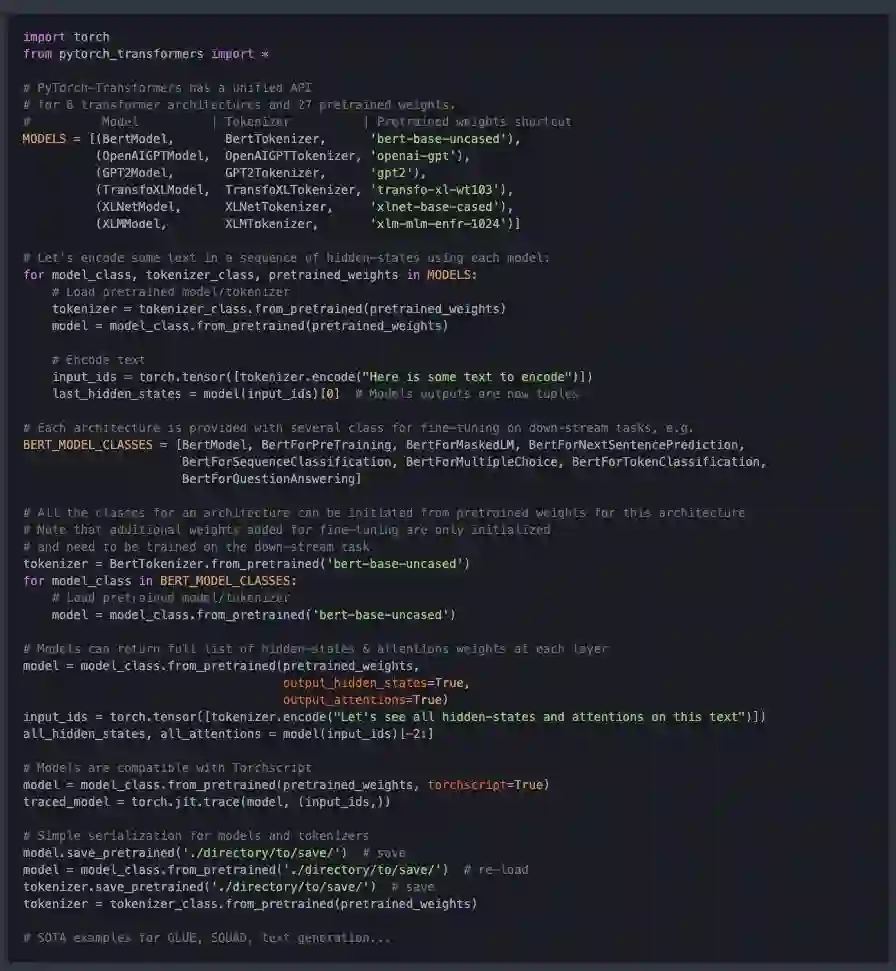
只需一个API,直接调用BERT, GPT, GPT-2, Transfo-XL, XLNet, XLM等6大框架,包含了27个预训练模型。
简单易用,功能强大。目前已经包含了PyTorch实现、预训练模型权重、运行脚本和以下模型的转换工具:
BERT,论文:“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”,论文作者:Jacob Devlin, Ming-Wei Chang, Kenton Lee,Kristina Toutanova
OpenAI 的GPT,论文:“Improving Language Understanding by Generative Pre-Training”,论文作者:Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever
OpenAI的GPT-2,论文:“Language Models are Unsupervised Multitask Learners”,论文作者:Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei,Ilya Sutskever
谷歌和CMU的Transformer-XL,论文:“Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context”,论文作者:Zihang Dai, Zhilin Yang, Yiming Yang, Jaime Carbonell, Quoc V. Le, Ruslan Salakhutdinov.
谷歌和CMU的XLNet,论文:“XLNet: Generalized Autoregressive Pretraining for Language Understanding”,论文作者:Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le
Facebook的XLM,论文:“Cross-lingual Language Model Pretraining”,论文作者:Guillaume Lample,Alexis Conneau
这些实现都在几个数据集(参见示例脚本)上进行了测试,性能与原始实现相当,例如BERT中文全词覆盖在SQuAD数据集上的F1分数为93;OpenAI GPT 在RocStories上的F1分数为88;Transformer-XL在WikiText 103上的困惑度为18.3;XLNet在STS-B的皮尔逊相关系数为0.916。
项目中提供27个预训练模型,下面是这些模型的完整列表,以及每个模型的简短介绍。
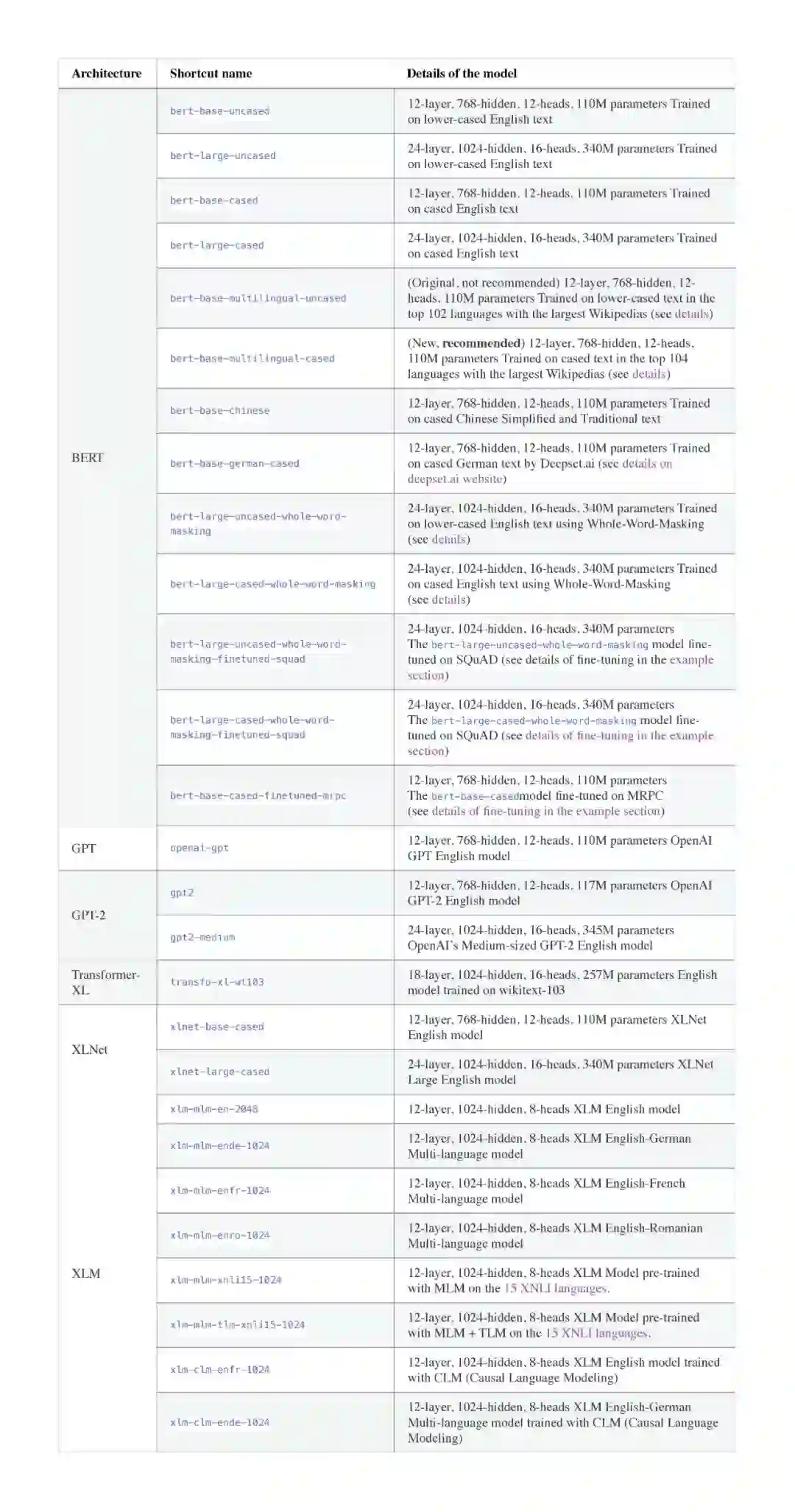
BERT-base和BERT-large分别是110M和340M参数模型,并且很难在单个GPU上使用推荐的批量大小对其进行微调,来获得良好的性能(在大多数情况下批量大小为32)。
为了帮助微调这些模型,作者提供了几种可以在微调脚本中激活的技术 run_bert_classifier.py和run_bert_squad.py:梯度累积(gradient-accumulation),多GPU训练(multi-gpu training),分布式训练(distributed training )和16- bits 训练( 16-bits training)。
注意,这里要使用分布式训练和16- bits 训练,你需要安装NVIDIA的apex扩展。
作者在doc中展示了几个基于BERT原始实现和扩展的微调示例,分别为:
九个不同GLUE任务的序列级分类器;
问答集数据集SQUAD上的令牌级分类器;
SWAG分类语料库中的序列级多选分类器;
另一个目标语料库上的BERT语言模型。
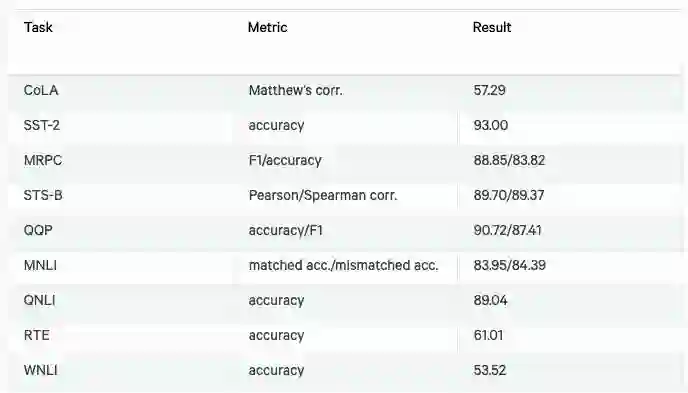
这里仅展示GLUE的结果:
该项目是在Python 2.7和3.5+上测试(例子只在python 3.5+上测试)和PyTorch 0.4.1到1.1.0测试。
项目地址:
https://github.com/huggingface/pytorch-transformers




