
GPT-4来了!今日凌晨,万众瞩目的大型多模态模型GPT-4正式发布! OpenAI CEO Sam Altman直接介绍说:
这是我们迄今为止功能最强大的模型!

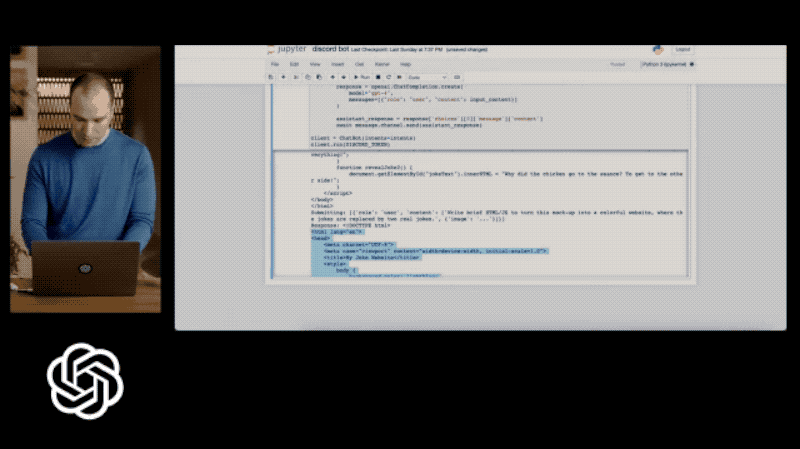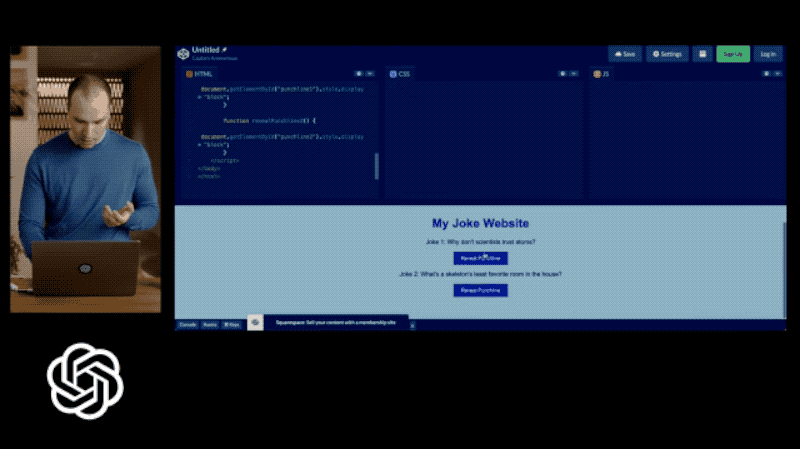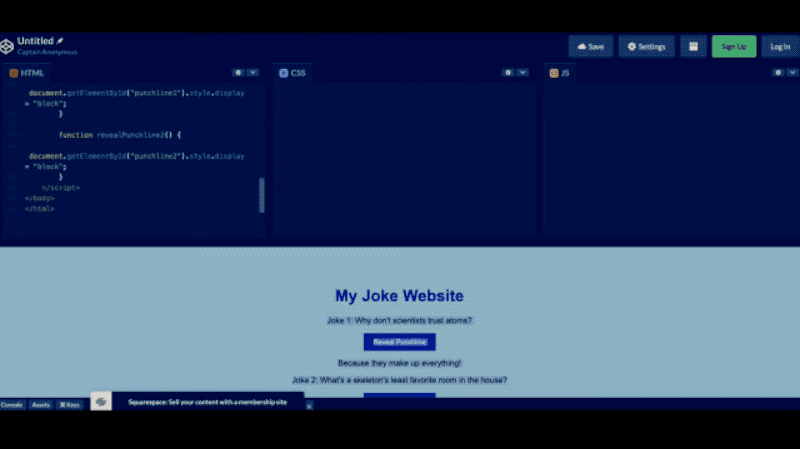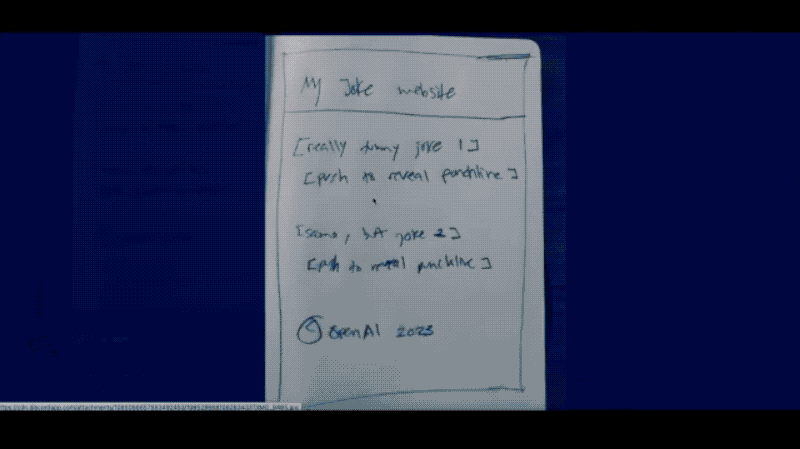
它强大到什么程度呢?输入一张手绘草图,GPT-4能直接生成最终设计的网页代码。
它以高分通过各种标准化考试:SAT拿下700分,GRE几乎满分,逻辑能力吊打GPT-3.5。
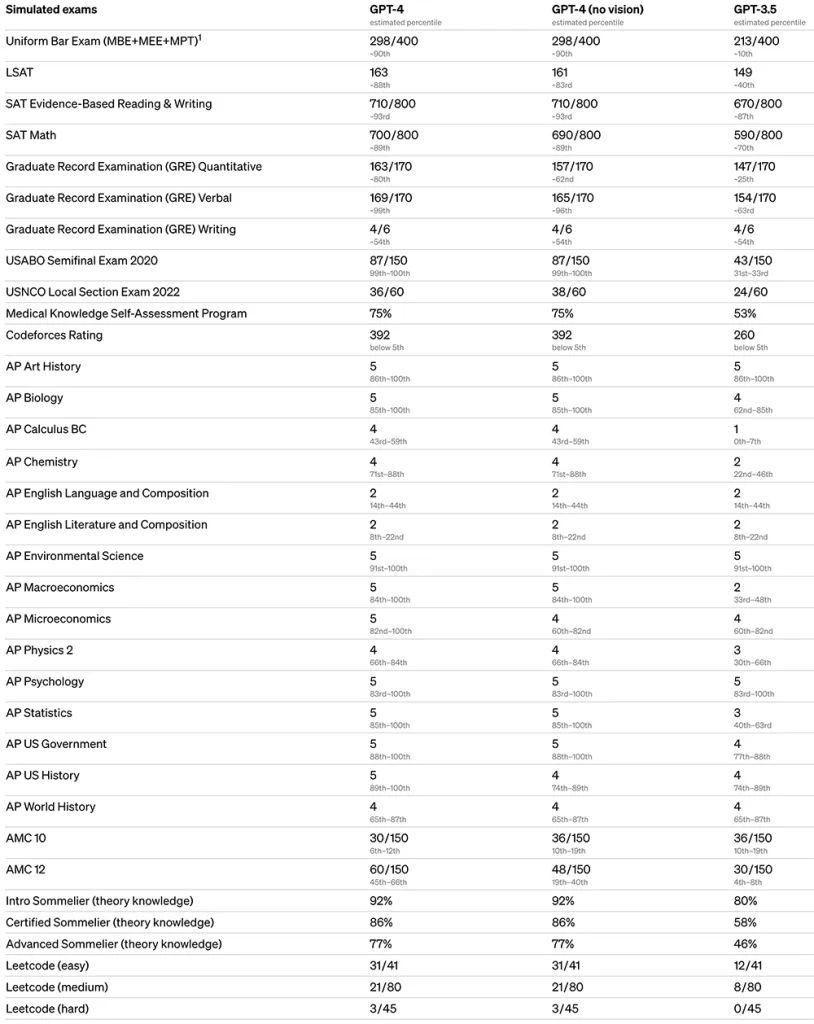
GPT-4在高级推理能力上超越ChatGPT。在律师模拟考试中,ChatGPT背后的GPT-3.5排名在倒数10%左右,而GPT-4考到了前10%左右。GPT-4的长度限制提升到32K tokens,即能处理超过25000个单词的文本,并且可以使用长格式内容创建、扩展对话、文档搜索和分析等。OpenAI还贴心地发布了GPT-4开发者视频,手把手教你生成代码、检查错误信息、报税等。在视频中,OpenAI联合创始人兼总裁Greg Brockman说了句有点扎心的话:“它并不完美,但你也一样。”OpenAI正通过ChatGPT和API发布GPT-4的文本输入功能,图像输入功能暂未开放。ChatGPT plus订阅者可直接获得有使用上限的GPT-4的试用权,4小时内最多只能发布100条信息。开发者也可以申请GPT-4 API,进入候补名单等待通过。
**申请直通门:**http://t.cn/A6ClOHn7随着时间的推移,OpenAI会将其自动更新为推荐的稳定模型(你可以通过调用gpt-4-0314来锁定当前版本,OpenAI将支持到6月14日)。定价是每1k prompt tokens 0.03美元,每1k completion tokens 0.06美元。默认速率限制是每分钟40k tokens和每分钟200个请求。gpt-4的上下文长度为8192个tokens。还提供对32768个上下文(约50页文本)版本gpt-4-32k的有限访问,该版本也将随着时间的推移自动更新(当前版本gpt-4-32k-0314,也将支持到6月14日)。价格是每1k prompt tokens 0.06美元,每1K completion tokens 0.12美元。此外,OpenAI还开源了用于自动评估AI模型性能的框架OpenAI Evals,以便开发者更好的评测模型的优缺点,从而指导团队进一步改进模型。开源地址:github.com/openai/evalsGPT-4 技术报告

本文报告了GPT-4的发展,这是一个大规模的多模态模型,可以接受图像和文本输入并产生文本输出。虽然在许多现实世界的场景中,GPT-4的能力不如人类,但它在各种专业和学术基准上表现出了人类水平的表现,包括通过了模拟的律师考试,其分数约为考生的前10%。GPT-4是一个基于transformer的模型,预训练用于预测文档中的下一个token。训练后的校准过程会提高对事实的衡量和对期望行为的坚持程度。该项目的一个核心组件是开发基础设施和优化方法,这些方法可以在广泛的范围内预测性能。这使我们能够基于不超过GPT-4计算量的1/ 1000的训练模型准确地预测GPT-4性能的某些方面。本技术报告介绍了GPT-4,一个能够处理图像和文本输入并产生文本输出的大型多模态模型。此类模型是一个重要的研究领域,具有广泛的应用前景,如对话系统、文本摘要和机器翻译。因此,近年来,它们一直是人们感兴趣和取得进展的主题[1-28]。开发这样的模型的主要目标之一是提高它们理解和生成自然语言文本的能力,特别是在更复杂和微妙的情况下。为了测试它在这种情况下的能力,在最初为人类设计的各种考试中对GPT-4进行了评估。在这些评估中,它表现得相当好,经常超过绝大多数人类考生。例如,在模拟的律师考试中,GPT-4的分数落在了考生的前10%。这与GPT-3.5形成对比,GPT-3.5得分在最后10%。在一套传统的NLP基准测试中,GPT-4的表现优于之前的大型语言模型和大多数最先进的系统(这些系统通常有基准特定的训练或手工工程)。在MMLU基准29,30上,GPT-4不仅在英语方面以相当大的优势超过现有模型,而且在其他语言方面也表现出强大的性能。在MMLU的翻译变体上,GPT-4在考虑的26种语言中的24种超过了英语的最先进水平。我们将在后面的章节中更详细地讨论这些模型能力结果,以及模型安全性的改进和结果。本报告还讨论了该项目的一个关键挑战,即开发在大范围内表现可预测的深度学习基础设施和优化方法。这使我们能够对GPT-4的预期性能做出预测(基于以类似方式训练的小测试),并在最后的测试中进行测试,以增加我们对训练的信心。尽管GPT-4功能强大,但它与早期的GPT模型有相似的局限性[1,31,32]:它不完全可靠(例如,可能会出现“幻觉”),上下文窗口有限,并且不能从经验中学习。在使用GPT-4输出时应小心,特别是在可靠性很重要的情况下。GPT-4的能力和局限性带来了重大而新颖的安全挑战,我们认为,考虑到潜在的社会影响,仔细研究这些挑战是一个重要的研究领域。本报告包括一个广泛的系统卡(在附录之后),描述了我们预计的关于偏见、虚假信息、过度依赖、隐私、网络安全、扩散等方面的一些风险。它还描述了我们为减轻GPT-4部署带来的潜在危害而采取的干预措施,包括与领域专家进行对抗性测试,以及一个模型辅助的安全通道。本报告重点介绍了GPT-4的功能、局限性和安全性。GPT-4是[33]预训练的transformer风格的模型,可以使用公开可用的数据(如互联网数据)和第三方提供商授权的数据来预测文档中的下一个Token。然后使用来自人类反馈的强化学习(RLHF)[34]对模型进行微调。考虑到大型模型(如GPT-4)的安全影响,本报告没有包含有关架构(包括模型大小)、硬件、训练计算、数据集构造、训练方法或类似内容的进一步细节。我们致力于对我们的技术进行独立审计,并在这个版本附带的系统卡中分享了这一领域的一些初始步骤和想法我们计划向更多的第三方提供进一步的技术细节,他们可以就如何权衡上述竞争和安全考虑与进一步透明的科学价值提供建议

