在过去的十年中,域适应已经成为迁移学习的一个广泛研究的分支,其目的是通过利用源领域的知识来提高目标领域的性能。传统的域适应方法通常假设同时访问源域和目标域数据,由于隐私和机密性的考虑,这在现实场景中可能是不可行的。因此,近年来无源域适应(Source-Free Domain Adaptation, SFDA)的研究受到越来越多的关注,它仅利用源训练的模型和未标记的目标数据来适应目标域。尽管SFDA的工作呈爆炸式增长,但目前还没有对该领域进行及时、全面的综述。**为填补这一空白,本文对SFDA的最新进展进行了全面的调研,并基于迁移学习框架将其组织成一个统一的分类方案。**不是独立地介绍每种方法,而是将每种方法的几个组件模块化,根据每种方法的复合属性更清楚地说明它们的关系和机制。在Office-31、Office-home和VisDA这3个流行的分类基准上,比较了30多种具有代表性的SFDA方法的结果,探讨了各种技术路线的有效性以及它们之间的组合效果。此外,还简要介绍了SFDA及其相关领域的应用。通过对SFDA面临的挑战的分析,我们对未来的研究方向和潜在的设置提出了一些见解。
https://www.zhuanzhi.ai/paper/180729c2f4546455b603529974efa22d
1.引言
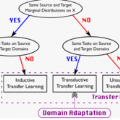
深度神经网络的泛化能力使其能够在监督学习任务中取得令人满意的性能。然而,由于成本和隐私问题等因素,收集足够的训练数据可能是昂贵的。例如,手动标注单个城市景观图像进行语义分割可能需要长达90分钟。为了缓解这一问题,迁移学习方法[1]、[2]被提出,以实现标签缺失条件下的跨领域知识迁移。域自适应(Domain adaptation,简称[3],[4])作为迁移学习的一个重要分支,研究如何借助有标签的源域数据提高模型在无标签目标域上的性能。在独立均匀分布条件下,域自适应面临的最大挑战是如何减少域偏移,域偏移主要可以分为条件偏移、协变量偏移、标签偏移和概念偏移,在之前的数据分析综述[5]、[6]中得到了广泛讨论。 在传统的域适应方法中,大多假设源域和目标域数据在适应过程中都可以被访问。然而,这在许多应用中是不现实的。一方面,原始源域数据在某些情况下会由于个人隐私、机密性和版权问题而不可用;另一方面,将完整的源数据集保存在一些资源有限的设备上进行训练是不现实的。上述问题阻碍了该领域的进一步推广。为放松DA方法对源数据的依赖,近年来提出了无源域适应(SFDA)[7]、[8],迅速成为域适应的重点,在图像分类[9]、[10]、语义分割[11]、[12]和目标检测[13]、[14]等领域得到广泛研究。
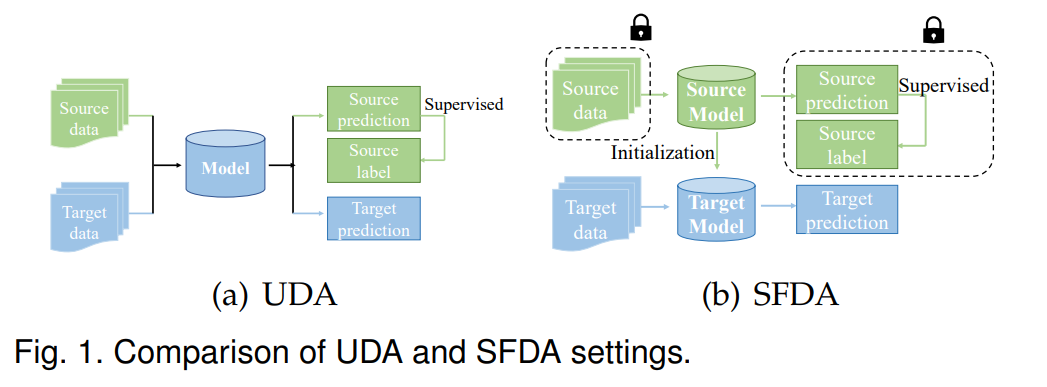
如图1所示,SFDA与无监督域适应(UDA)[15],[16]之间最大的区别是UDA模型可以同时使用源域和目标域数据进行训练,而SFDA只能利用源域模型初始化目标模型,然后使用未标记的目标数据更新目标模型。现有的主流UDA方法可以分为两类主要方法:通过设计特定指标[3]、[17]、[18]来对齐源域和目标域分布的方法,以及通过对抗性学习[19]、[20]、[21]来学习域不变特征表示的方法。然而,这些主流UDA方法并不适用于没有源域数据的场景,突显了研究SFDA方法作为替代的必要性。尽管对SFDA做了大量的工作,但目前还没有对所有工作进行全面的综述,也没有对目前SFDA相关进展进行总结。为了填补这一空白,本文旨在对SFDA的最新进展进行及时和全面的综述。
本文继承了现有的迁移学习综述[2],[22],将SFDA分为两个方向:基于数据库的方向和基于模型的方向。通过对重构源域的一些额外步骤,传统的UDA方法开始在SFDA环境中工作,因此讨论了该体制作为基于域的重构方法,以反映UDA研究的可扩展性。我们在图2中描述了SFDA方法的整体拓扑结构。
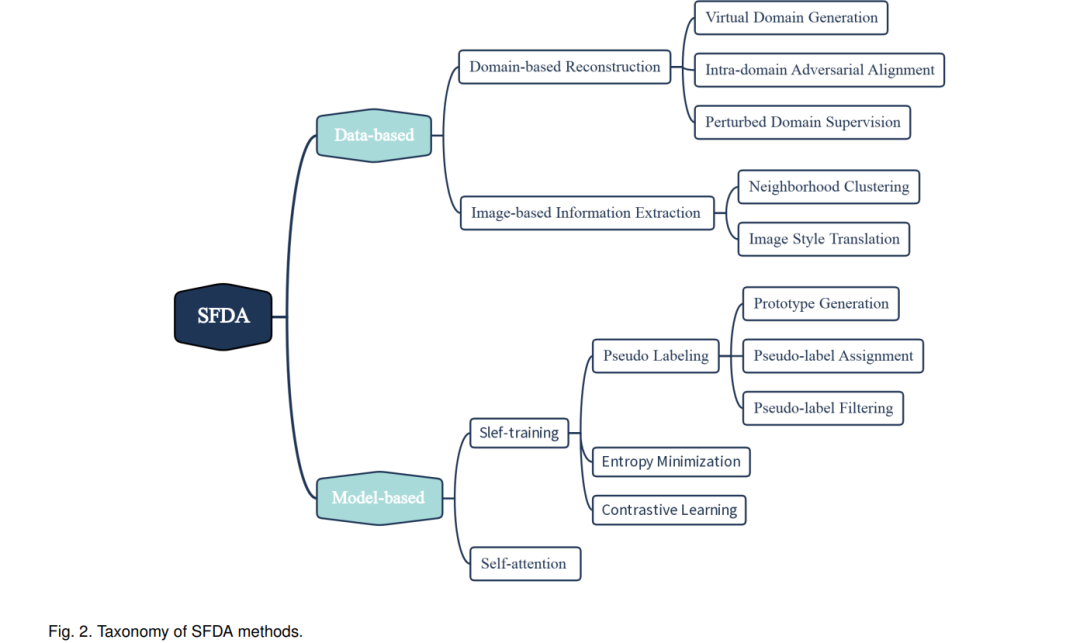
**从以数据为中心的角度来看,基于域的重建和图像风格转换可以被视为UDA的一些扩展体。**基于域的重建背后的直觉非常直接,即旨在重建一个域或在目标域内进行进一步划分,以补偿缺失的源域数据,从而可以将UDA方法扩展到SFDA设置。具体而言,可分为虚拟域生成、域内对抗对齐和扰动域监督。图像风格转换通过源域分类器的批量归一化(Batch Normalization, BN)层将目标域数据转换为未见过的源域风格,从而使目标域数据更好地与源域模型兼容。邻域聚类是基于这样的观察:目标域数据的内在结构嵌入在近邻关系中,即使目标域数据分布与源域分类器不显式对齐。一种假设是目标域的每个类别都存在位于源域边界内的邻居,因此可以通过保持邻居之间的一致性来将这些硬样本映射到源域分布。最后,基于流形学习[23]、[24]、[25]进行局部结构聚类,并通过邻居节点的选择进行聚类。
**从以模型为中心的角度来看,由于源域和目标域的相似性,大多数方法都假设源预训练模型对目标域具有一定程度的泛化。**因此,可以通过探索模型在目标数据上的输出来对模型进行微调。该自训练方案继承了半监督学习[26],[27],[28]的思想,可进一步分为伪标记、熵最小化和对比学习。值得注意的是,伪标签方法是SFDA最常用的方法。伪标记通常是先对目标域中的高置信样本进行伪标记,然后利用得到的伪标签对模型进行优化。因此,如何获得高质量的伪标签是这类方法主要关注的问题。本文从原型生成、伪标签赋值和伪标签滤波三个方面对该技术路线进行了全面的讨论。此外,我们观察到大多数SFDA方法由多个技术组件组成,并且每个组件可能对应于我们分类法中的一个类别。因此,不同于以往的领域适应性调研,我们的目标是将每种SFDA方法模块化并进行分类,以揭示不同研究方向之间的相互关系。本次调研的目的是讨论SFDA的问题制定,总结当前该领域的进展,并突出SFDA技术的独特组成部分,以提供对该领域的全面理解,并激发更多的想法和应用。本次调研的主要贡献可以总结如下:本文从以数据为中心和以模型为中心的角度,为新出现的SFDA设置提出了一个总体的分类框架。本综述填补了现有文献的空白,及时全面地总结了最新的SFDA方法和应用。对30多个代表性作品进行了模块化,并在使用最广泛的分类数据集Office-31、Office-home和VisDA上比较了结果。对不同成分的组合进行了可视化展示和对比分析,对进一步在SFDA环境下的研究具有指导意义
本调研的其余部分结构如下。在第2节中,我们介绍了SFDA的相关符号和初步知识。第3节和第4节分别提供了以数据为中心和以模型为中心的SFDA方法的全面回顾。第5节在3个主流分类数据集上对现有的SFDA方法进行了比较。第6节讨论了SFDA的潜在应用,第7节介绍了SFDA未来方向的展望。最后,在第8节对本文进行总结。