

数据增强(DA)在现代机器学习和深度神经网络中是不可或缺的。DA的基本思想是构建新的训练数据,通过添加现有数据的轻微扰动版本或合成新数据来提高模型的泛化能力。本文回顾了基于DA - mix的数据增强(MixDA)的一个小但重要的子集,通过混合多个样本来生成新样本。与传统的基于单样本操作或需要领域知识的DA方法不同,MixDA在创建广泛的新数据方面更具一般性,在社区中受到越来越多的关注。提出了一种新的分类法,根据数据混合的层次视图,将MixDA分为基于Mixup、基于cutmix和hybrid方法。然后以更细粒度的方式全面调研各种MixDA技术。由于其通用性,MixDA已经渗透到各种应用程序中,本文也对这些应用程序进行了全面的综述。还从提高模型性能、泛化和校准等不同方面研究了MixDA为什么有效,同时根据MixDA的属性解释模型行为。总结了当前MixDA研究的关键发现和基本挑战,并概述了未来工作的潜在方向。不同于以往的相关工作总结特定领域(如图像或自然语言处理)的数据挖掘方法或只回顾MixDA的一部分研究,本文首次从分类、方法论、应用和可解释性等方面对MixDA进行了系统的综述。这项工作可以作为MixDA技术和应用调研的路线图,同时为对这一令人兴奋的领域感兴趣的研究人员提供有希望的方向。这些方法的列表可以在https://github.com/ChengtaiCao/Awesome-Mix上找到。
1. 引言
深度学习(DL)由于其学习表达表示的能力,对[1]的不同领域产生了变革性的影响。随着所要解决的问题越来越具有挑战性,网络结构变得越来越复杂,层数越来越多**。然而,深度神经网络(dnn)因其具有数百万甚至数十亿参数的数据需求而臭名昭著(例如Bert[2]),使它们容易过拟合。许多创新致力于通过使用改进的网络架构使dnn更具数据效率。例如,卷积神经网络(CNN)经历了从AlexNet[3]到ResNet[4]越来越高级的进化过程。此外,还提出了多种正则化方法来提高DNN的泛化能力,如权重衰减[5]、dropout[6]、随机深度[7]和批量归一化[8]。Dropout在训练过程中随机归零一些激活,以模拟更多的网络架构子集,并防止神经元的共同适应。批量归一化通过从每个激活中减去批量均值并除以批量标准差来规范化激活。数据增强(DA)是指在不明确收集新样本的情况下增加训练数据的数量和多样性,通常是减少过拟合的补救措施。DA方法试图扩大有限的数据并提取额外的信息,结合先进的网络架构和现有的正则化技术,可以提高模型的整体性能。例如,在样本中添加随机噪声,作为一种简单的DA方法,可以产生大量新的训练样本,有利于模型的鲁棒性。在处理图像数据时,采用随机裁剪、水平翻转和改变RGB通道强度[3]等标签不变的数据变换可以提高性能,增强对平移、反射和光照的鲁棒性。另一个例子是,使用随机删除[9]或裁剪[10]训练的模型显示出改进的正则化。在自然语言处理(NLP)应用中,同义词替换、随机插入、随机交换和随机删除[11]是增强语言数据的主流方法。最后,生成模型如变分自编码器(VAE)[12]和生成对抗网络(GANs)[13]可以生成任意数量的虚假但真实的样本,也被广泛用于数据增强。本文关注数据增强的一个新兴领域——基于Mix的数据增强(MixDA),近年来引起了大量的研究。
与传统的基于单一实例的数据挖掘方法不同,MixDA通过组合多个实例创建虚拟训练数据,生成大量无领域知识的训练数据。例如,Mixup[14]从整体角度对两个随机采样的训练样本的输入输出对进行线性插值。Cutmix[15]从一个图像(源图像)剪切一个patch,然后从局部性的角度将其粘贴到另一个图像(目标图像)的相应区域。后来,继Mixup和Cutmix之后,人们通过不同的视角提出了大量MixDA的改进版本,这些版本也是本文分类的基础,如灵活的混合比例、显著性指导和改进的散度。由于其通用性,MixDA已成功应用于各种任务,包括半监督学习、生成模型、图学习和NLP。此外,还提出了一些理论研究,从不同的角度来解释MixDA。因此,是时候对MixDA的基础、方法、应用和可解释性进行全面的调研。为阐明后续研究,本文介绍了对当前MixDA的发现及其挑战,以及一些有希望的未来途径。
**相关的综述。
在这里,我们清楚地说明了我们的综述与相关工作之间的差异。首先,对数据增强方法[16],[17],[18],[19]进行综述**。然而,这些综述侧重于应用各种数据增强技术的特定领域。例如,Feng等人的[16]研究了文本数据处理中的数据挖掘方法。此外,还对其他领域的数据挖掘方法进行了综述,包括图像识别[17]、时间序列学习[18]和图结构数据学习[19]。尽管这些工作和我们的工作之间有轻微的重叠,但我们专注于一种特殊的DA方法,MixDA,可以在广泛的领域中利用(参见第4节的详细信息)。另一项类似的工作是对模型正则化[20],[21],[22],[23]的调研,其中概述了不同目的的正则化技术,如使用噪声标签学习[21],提高GANs[22]的性能,以及泛化到分布外数据[23]。我们的工作与这些评论是正交的,因为我们关注研究结合多个示例和利用MixDA来提高不同任务性能的方法的工作,尽管一些MixDA方法具有正则化效果[24],[25],[26]。与我们最相似的作品是[27]和[28]。前者回顾了图像混合和图像删除的方法,后者回顾了图像混合增强和其他增强策略。他们只总结了一部分基于Mix的数据增强方法,还有其他重点:(1)[27]综述了一些基于删除的数据增强方法,如随机擦除[9]和捉迷藏[29];(2)[27]回顾了一些基于割的数据增强方法,如向输入图像随机选择的区域添加高斯噪声的Patch Gaussian[30]和用0像素值掩码/擦除输入图像区域的Cutout[10]。然而,这项工作将完全注意力放在基于MixDA的数据增强上,最重要的是,还提供了之前工作中没有涉及的MixDA应用程序的彻底审查。据我们所知,这篇综述是第一篇全面回顾MixDA技术并总结其广泛应用范围的工作。回顾了70多个MixDA方法(第3节)和10多个MixDA应用(第4节)。预计本综述可以为这一令人兴奋的领域的研究人员提供MixDA技术路线图。
组织。本调研的结构如下。第2节描述了DA和MixDA的总体情况,我们还提供了MixDA的新分类法。在第3节中,我们系统地回顾了现有的方法,并讨论了它们的优缺点。第4节研究了MixDA的重要应用,然后在第5节中对MixDA的可解释性进行了分析。第6节介绍了关键发现和挑战,并概述了潜在的研究方向。最后,在第7节对本文工作进行总结。
Mixup数据增强分类
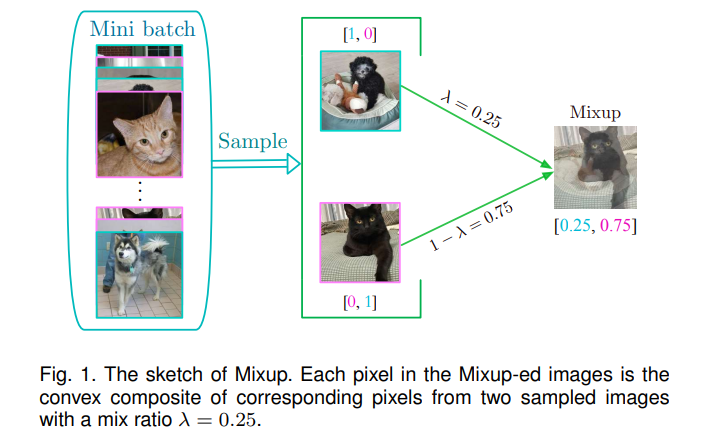
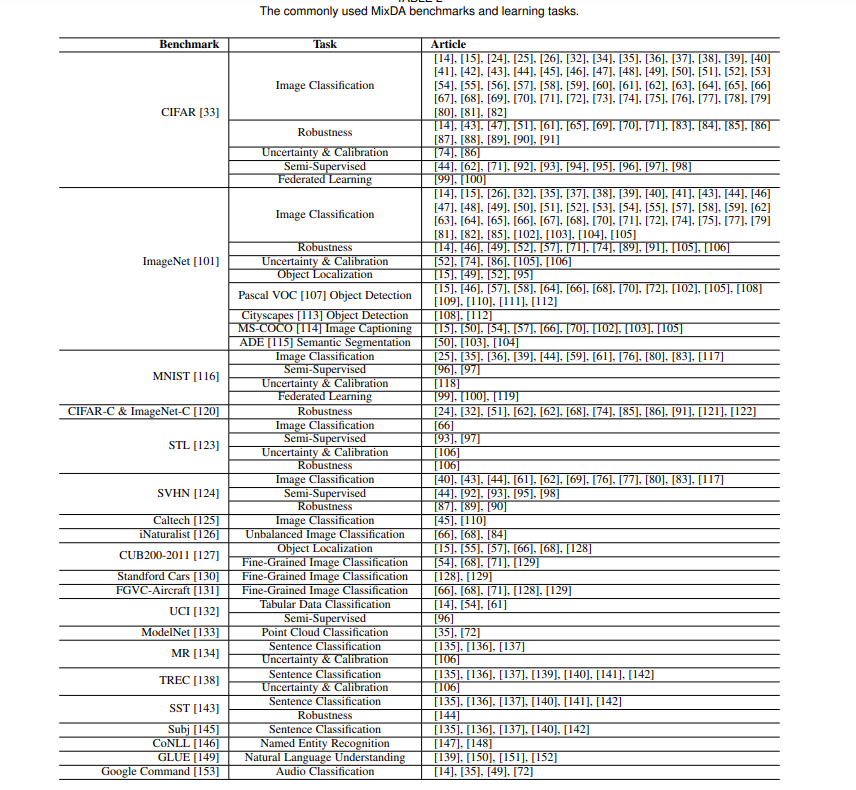
本文提出了MixDA方法的第一个分类。将现有研究分为三类:(1)从全局角度混合训练样本的方法,以前沿工作Mixup[14]为代表;(2)通过以Cutmix[15]为代表的局部性视角构建新数据的方法;(3)其他基于混合原理但不能简单归为上述两类的技术,如与数据重构混合、集成多个MixDA解决方案。我们提出的分类法背后的原理如下。Mixup及其变体通常开发一个全局的Mix方案,并将其应用于所有特征。例如,Mixup从Beta分布中提取混合比例,创建的示例中的每个特征都是两个采样的训练示例的相应特征的线性组合,以鼓励模型从全局角度理解数据。相比之下,Cutmix及其自适应方法从一个实例中截取部分特征,然后将其粘贴到另一个示例上,以提高模型的本地化能力。此外,有许多混合工作集成了多种MixDA方法或将MixDA与其他SsDA方法相结合。例如,RandomMix[31]通过从每个小批量的MixDA方法集合中采样的mix操作创建增强的数据。类似地,AugMix[32]通过SsDA为每个样本构造多个版本,然后通过MixDA将它们混合。在本节中,我们回顾了各种各样的基于mix的策略,这些策略可以分为三组:(1)Mixup[14]及其变体,从整体角度混合了多个示例,(2)Cutmix[15]及其通过局部性的角度结合多个示例的适应性,以及(3)其他MixDA方法,如mix wit本身,结合多种基于mix的方法,以及将MixDA与SsDA集成。表2总结了常用的基准测试和相应的任务。
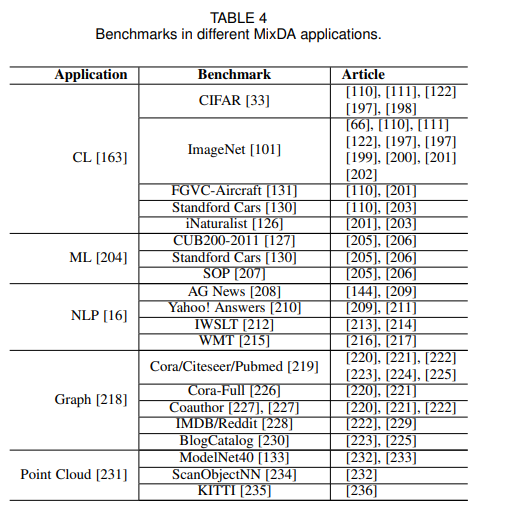
在本节中,我们将回顾MixDA的广泛应用,如半监督学习、生成模型、收缩学习和NLP。表4总结了具有代表性的应用和相应的基准。
Mixda的可解释性分析
尽管许多MixDA方法已被成功用于解决一系列应用,但尚不清楚这些方法的原理和工作原理。在本节中,我们系统地概述了MixDA的可解释性基础,重点从3个不同方面解释了为什么混合样本有助于泛化:(1)邻近风险最小化(VRM),(2)正则化,以及(3)不确定性和校准。此外,我们还提供了一些MixDA工作良好的原因的解释。
结论
数据增强一直是机器学习和深度学习研究中的一个重要研究课题。通过对技术、基准、应用和理论基础的深入分析,系统地回顾了基于mix的数据增强方法。首先,我们为MixDA方法引入了一种新的分类。在这种情况下,一个更细粒度的分类法根据现有MixDA方法的动机将它们分为不同的组。然后,我们彻底回顾了各种MixDA方法,并回顾了它们的优点和缺点。此外,我们全面调研了十余类MixDA应用。此外,本文分别从ERM、正则化和不确定性&校准的角度为读者提供了对MixDA的理论检验,同时通过检验MixDA的关键性质来解释MixDA的成功。最后,总结了MixDA研究的重要发现、发展趋势和现有研究面临的主要挑战,并展望了该领域未来的研究机遇。通过这篇综述,希望研究人员和从业人员能找到MixDA方法及其应用的技术手册,以及解决基本问题和推进该领域的方向。
