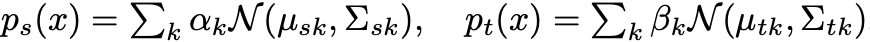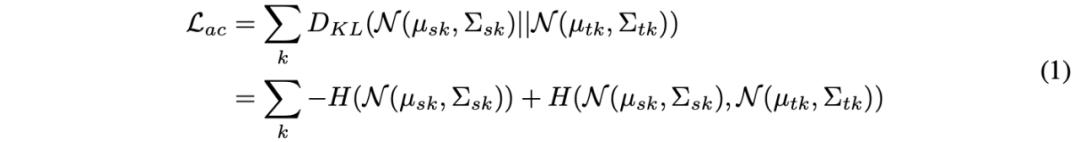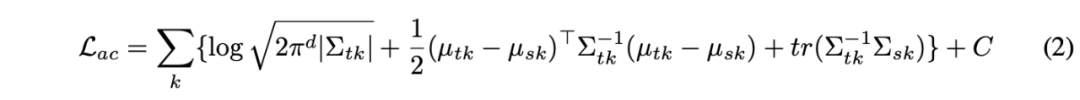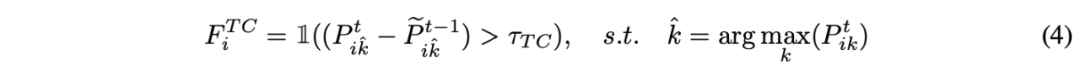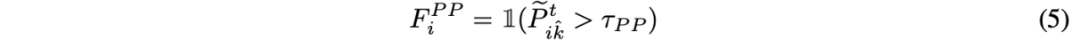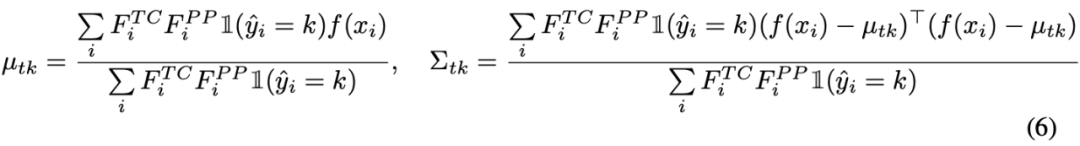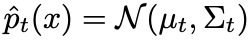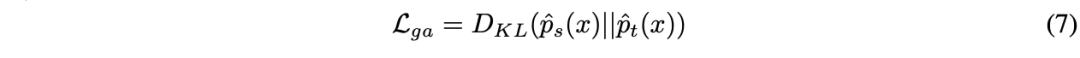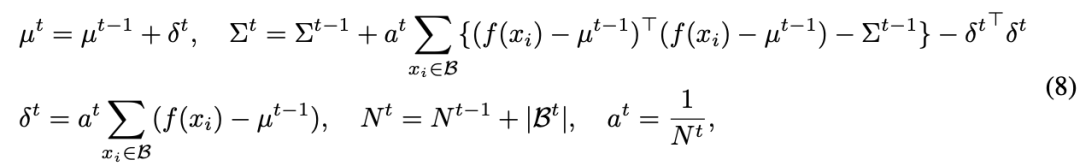©作者 | 苏永怡
来源 | 机器之心
华南理工、A*STAR 团队和鹏城实验室联合提出了针对测试阶段训练(TTT)问题的系统性分类准则。
域适应是解决迁移学习的重要方法,当前域适应当法依赖原域和目标域数据进行同步训练。当源域数据不可得,同时目标域数据不完全可见时,测试阶段训练(Test- Time Training)成为新的域适应方法。当前针对 Test-Time Training(TTT)的研究广泛利用了自监督学习、对比学习、自训练等方法,然而,如何定义真实环境下的 TTT 却被经常忽略,以至于不同方法间缺乏可比性。
近日,华南理工、A*STAR 团队和鹏城实验室联合提出了针对 TTT 问题的系统性分类准则,通过区分方法是否具备顺序推理能力(Sequential Inference)和是否需要修改源域训练目标,对当前方法做了详细分类。同时,提出了基于目标域数据定锚聚类(Anchored Clustering)的方法,在多种 TTT 分类下取得了最高的分类准确率,本文对 TTT 的后续研究指明了正确的方向,避免了实验设置混淆带来的结果不可比问题。研究论文已被 NeurIPS 2022 接收。
Revisiting Realistic Test-Time Training: Sequential Inference and Adaptation by Anchored Clustering
论文链接:
https://arxiv.org/abs/2206.02721
代码链接:
https://github.com/Gorilla-Lab-SCUT/TTAC
深度学习的成功主要归功于大量的标注数据和训练集与测试集独立同分布的假设。在一般情况下,需要在合成数据上训练,然后在真实数据上测试时,以上假设就没办法满足,这也被称为域偏移。为了缓解这个问题,域适应 (Domain Adaptation, DA) 诞生了。现有的 DA 工作要么需要在训练期间访问源域和目标域的数据,要么同时在多个域进行训练。前者需要模型在做适应 (Adaptation) 训练期间总是能访问到源域数据,而后者需要更加昂贵的计算量。
为了降低对源域数据的依赖,由于隐私问题或者存储开销不能访问源域数据,无需源域数据的域适应 (Source-Free Domain Adaptation, SFDA) 解决无法访问源域数据的域适应问题。作者发现 SFDA 需要在整个目标数据集上训练多个轮次才能达到收敛,在面对流式数据需要及时做出推断预测的时候 SFDA 无法解决此类问题。这种面对流式数据需要及时适应并做出推断预测的更现实的设定,被称为测试时训练 (Test-Time Training, TTT) 或测试时适应(Test-Time Adaptation, TTA)。
作者注意到在社区里对 TTT 的定义存在混乱从而导致比较的不公平。论文以两个关键的因素对现有的 TTT 方法进行分类:
1. 对于数据是流式出现的并需要对当前出现的数据作出及时预测的,称之为单轮适应协议(One-Pass Adaptation);
对于其他不符合以上设定的称为多轮适应协议(Multi-Pass Adaptation),模型可能需要在整个测试集上进行多轮次的更新后,再进行从头到尾的推断预测。
2. 根据是否需要修改源域的训练损失方程,比如引入额外的自监督分支以达到更有效的 TTT。
这篇论文的目标是解决最现实和最具挑战性的 TTT 协议,即单轮适应并无需修改训练损失方程。这个设定类似于 TENT[1]提出的 TTA,但不限于使用来自源域的轻量级信息,如特征的统计量。鉴于 TTT 在测试时高效适应的目标,该假设在计算上是高效的,并大大提高了 TTT 的性能。作者将这个新的 TTT 协议命名为顺序测试时训练(sequential Test Time Training, sTTT)。
除了以上对不同 TTT 方法的分类外,论文还提出了两个技术让 sTTT 更加有效和准确:
1. 论
文提出了测试时锚定聚类 (Test-Time Anchored Clustering, TTAC) 方法;
2. 为了降低错误伪标签对聚类更新的影响,论文根据网络对样本的预测稳定性和自信度对伪标签进行过滤。
方法介绍
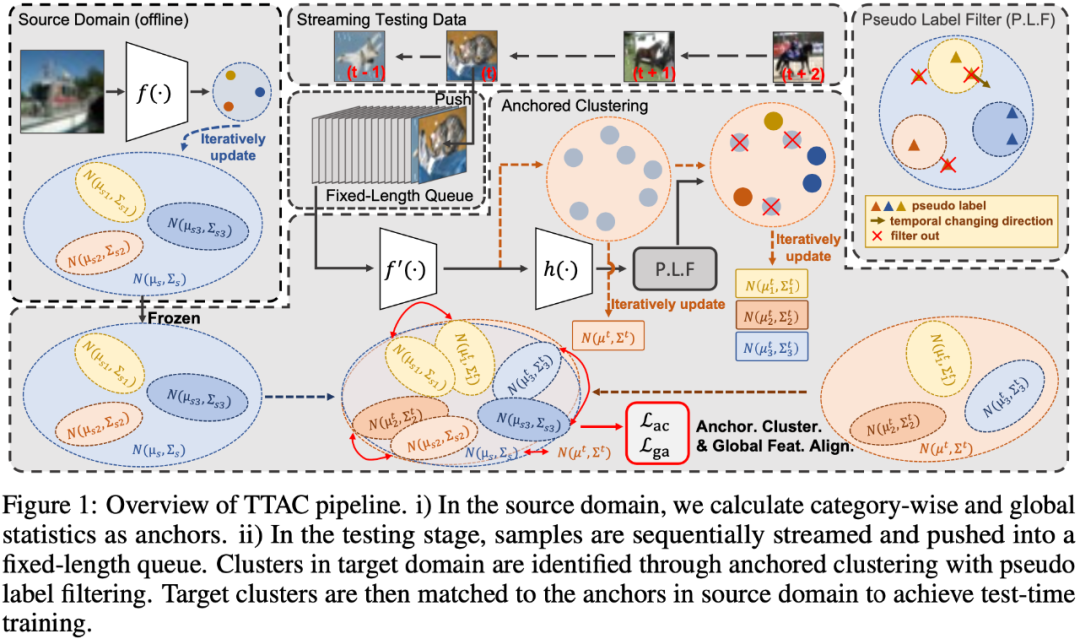
论文分了四部分来阐述所提出的方法,分别是 1)介绍测试时训练 (TTT) 的锚定聚类模块,如图 1 中的 Anchored Clustering 部分;2)介绍用于过滤伪标签的一些策略,如图 1 中的 Pseudo Label Filter 部分;3)不同于 TTT++[2]中的使用 L2 距离来衡量两个分布的距离,作者使用了 KL 散度来度量两个全局特征分布间的距离;4)介绍在测试时训练 (TTT) 过程的特征统计量的有效更新迭代方法。最后第五小节给出了整个算法的过程代码。
第一部分 在锚定聚类里,作者首先使用混合高斯对目标域的特征进行建模,其中每个高斯分量代表一个被发现的聚类。然后,作者使用源域中每个类别的分布作为目标域分布的锚点来进行匹配。通过这种方式,测试数据特征可以同时形成集群,并且集群与源域类别相关联,从而达到了对目标域的推广。概述来说就是,将源域和目标域的特征分别根据类别信息建模成:
然后通过 KL 散度度量两个混合高斯分布的距离,并通过减少 KL 散度来达到两个域特征的匹配。可是,在两个混合高斯分布上直接求解 KL 散度并没有闭式解,这导致了无法使用有效的梯度优化方法。在这篇论文中,作者在源域和目标域中分配相同数量的集群,每个目标域集群被分配给一个源域集群,这样就可以将整个混合高斯的 KL 散度求解变成了各对高斯之间的 KL 散度之和。如下式:
在公式 2 中,源域集群的参数可以线下收集完,而且由于只用到了轻量化统计数据,所以不会导致隐私泄漏问题且只使用了少量的计算和存储开销。对于目标域的变量,涉及到了伪标签的使用,作者为此设计了一套有效的且轻量的伪标签过滤策略。
第三部分 由于在锚定聚类中,部分被滤除的样本并没有参与目标域的估计。作者还对所有测试样本进行全局特征对齐,类似锚定聚类中对集群的做法,这里将所有样本看作一个整体的集群,在源域和目标域分别定义
然后再次以最小化 KL 散度为目标对齐全局特征分布:
第四部分 以上三部分都在介绍一些域对齐的手段,但在 TTT 过程中,想要估计一个目标域的分布是不简单的,因为我们无法观测整个目标域的数据。在前沿的工作中,TTT++[2]使用了一个特征队列来存储过去的部分样本,来计算一个局部分布来估计整体分布。但这样不但带来了内存开销还导致了精度与内存之间的 trade off。在这篇论文中,作者提出了迭代更新统计量的方式来缓解内存开销。具体的迭代更新式子如下:
![]()
实验结果
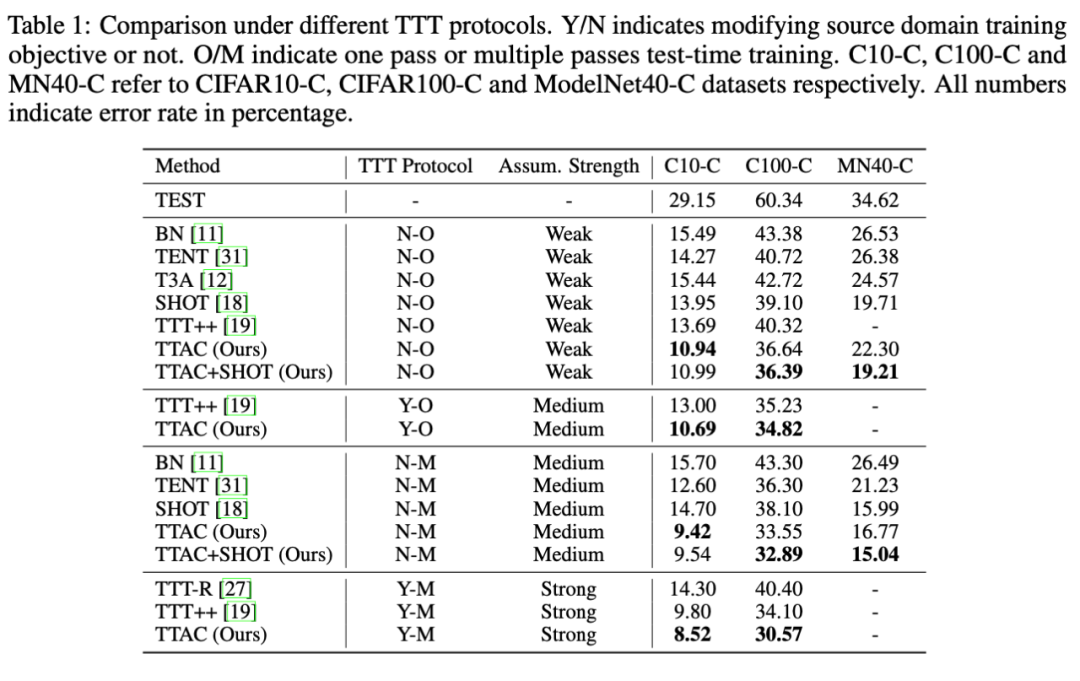
正如引言部分所说,这篇论文中作者非常注重不同 TTT 策略下的不同方法的公平比较。作者将所有 TTT 方法根据以下两个关键因素来分类:1)是否单轮适应协议 (One-Pass Adaptation) 和 2)修改源域的训练损失方程,分别记为 Y/N 表示需要或不需要修改源域训练方程,O/M 表示单轮适应或多轮适应。除此之外,作者在 6 个基准的数据集上进行了充分的对比实验和一些进一步的分析。
如表一所示,TTT++[2]同时出现在了 N-O 和 Y-O 的协议下,是因为 TTT++[2]拥有一个额外的自监督分支,我们在 N-O 协议下将不添加自监督分支的损失,而在 Y-O 下可以正常使用此分子的损失。TTAC 在 Y-O 下也是使用了跟 TTT++[2]一样的自监督分支。
从表中可以看到,在所有的 TTT 协议下所有数据集下,TTAC 均取得到最优的结果;
在 CIFAR10-C 和 CIFAR100-C 数据集上,TTAC 都取得了 3% 以上的提升。
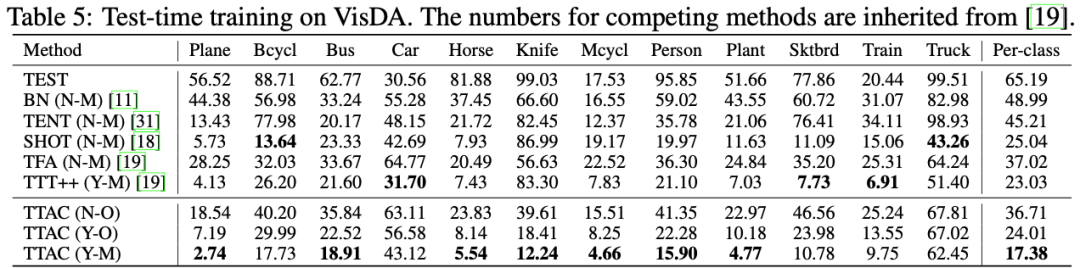
从表 2 - 表 5 分别是 ImageNet-C、CIFAR10.1、VisDA 上的数据,TTAC 均取到了最优的结果。
此外,作者在多个 TTT 协议下同时做了严格的消融实验,清晰地看出了每个部件的作用,如表 6 所示。
首先从 L2 Dist 和 KLD 的对比中,可以看出使用 KL 散度来衡量两个分布具有更优的效果;其次,发现如果单单使用 Anchored Clustering 或单独使用伪标签监督提升只有 14%,但如果结合了 Anchored Cluster 和 Pseudo Label Filter 就可以看到性能显著提高 29.15% -> 11.33%。这也可以看出每个部件的必要性和有效的结合。
最后,作者在正文的尾部从五个维度对 TTAC 展开了充分的分析,分别是 sTTT (N-O)下的累计表现、TTAC 特征的 TSNE 可视化、源域无关的 TTT 分析、测试样本队列和更新轮次的分析、以 wall-clock 时间度量计算开销。还有更多有趣的证明和分析会展示在文章的附录中。
![]()
总结
本文只是粗糙地介绍了 TTAC 这篇工作的贡献点:对已有 TTT 方法的分类比较、提出的方法、以及各个 TTT 协议分类下的实验。论文和附录中会有更加详细的讨论和分析。我们希望这项工作能够为 TTT 方法提供一个公平的基准,未来的研究应该在各自的协议内进行比较。
[1] Dequan Wang, Evan Shelhamer, Shaoteng Liu, Bruno Olshausen, and Trevor Darrell. Tent: Fully test-time adaptation by entropy minimization. In International Conference on Learning Representations, 2021.
[2] Yuejiang Liu, Parth Kothari, Bastienvan Delft, Baptiste Bellot-Gurlet, Taylor Mordan, and Alexandre Alahi. Ttt++: When does self-supervised test-time training fail or thrive? In Advances in Neural Information Processing Systems, 2021.
![]()
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿
![]()
△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
![]()